tr-legal-triplets
收藏Hugging Face2026-05-31 更新2026-06-01 收录
下载链接:
https://huggingface.co/datasets/yunus-emre/tr-legal-triplets
下载链接
链接失效反馈官方服务:
资源简介:
Turkish Legal QA Triplets(土耳其法律问答三元组)是一个高质量的数据集,专为训练和评估文本嵌入模型而设计。该数据集基于土耳其法律文档生成,包含查询、正例和负例的三元组结构。数据来源为土耳其公开的法律条文,经过提取、分块(分为1000字符的语义连贯片段,重叠200字符)后,使用GPT-4o-mini生成检索三元组。每个记录包含一个土耳其语的自然语言搜索查询、相关的原始法律文本(权威答案)、该文本的简化土耳其语版本,以及来自同一法律领域但不同主题的困难负例。数据集规模在100万到1000万样本之间,适用于多语言或土耳其语特定嵌入模型的微调(如使用sentence-transformers)、土耳其法律内容检索系统的基准测试、土耳其法律检索增强生成(RAG)管道开发以及法律问答研究。数据集结构包括唯一标识符、来源信息(如文档标题、类型、编号、条文类型和编号)和文本内容字段。
Turkish Legal QA Triplets is a high-quality dataset designed for training and evaluating text embedding models. It is generated from Turkish legal documents and features a triplet structure of queries, positive examples, and negative examples. The data source is publicly available Turkish legal provisions, which are extracted and chunked into semantically coherent segments of 1000 characters with 200 characters of overlap, then used to generate retrieval triplets via GPT-4o-mini. Each record includes a natural language search query in Turkish, the relevant original legal text (authoritative answer), a simplified Turkish version of that text, and a hard negative example from the same legal domain but a different topic. The dataset size ranges from 1 million to 10 million samples and is suitable for fine-tuning multilingual or Turkish-specific embedding models (e.g., using sentence-transformers), benchmarking Turkish legal content retrieval systems, developing Turkish legal retrieval-augmented generation (RAG) pipelines, and conducting legal question-answering research. The dataset structure includes unique identifiers, source information (such as document title, type, number, article type, and number), and text content fields.
创建时间:
2026-05-31
原始信息汇总
数据集概述:Turkish Legal QA Triplets (tr-legal-triplets)
本数据集是一个大规模的土耳其法律领域查询/正例/负例三元组集合,专为训练和评估土耳其法律内容上的多语言文本嵌入模型而设计。
数据集规模与子集
| 子集名称 | 记录数 | 描述 |
|---|---|---|
default |
1,148,041 | 完整生成的数据集。 |
cleaned |
1,043,913 | 经过质量筛选的数据集,推荐用于训练。 |
数据来源
- 来源文档:基于 19,970 份现行土耳其法律文件。
- 文档构成:
- 法规 (Yönetmelik):9,581
- 公报 (Tebliğ):4,321
- 总统令 (Cumhurbaşkanlığı Kararnamesi):4,006
- 法律 (Kanun):1,796
- 细则 (Tüzük):107
- 央行法规 (TCMB):66
- 法令 (Kanun Hükmünde Kararname):63
- 通函 (Genelge):29
- 宪法 (Anayasa):1
- 法律条款:涵盖 163,616 条法律条款,涉及6种条款类型(如条款、段落、子句、临时条款、部分、附件条款),来自 308 个机构。
数据生成流程
数据集通过一个包含三个步骤的管线生成:
- 标准化 (
pipeline/01_normalize.py):清洗和标准化原始法律条款。处理 157,831 条,输出 157,831 条标准化记录。 - 分块 (
pipeline/02_chunk.py):将长条款切分成语义连贯的片段。分块大小为1000字符,重叠200字符,对超过1500字符的条款进行切分。最终生成 198,789 个文本块。 - 生成 (
pipeline/03_generate_qa.py):使用 GPT-4o-mini 结合土耳其法律领域提示,为每个文本块生成检索三元组。并发100个API调用,根据文本块长度生成了5/7/10个三元组。最终处理 192,985 个文本块,生成 1,148,041 个三元组,零失败。
每条记录的内容
每个记录是一个包含四个文本字段的训练三元组:
| 字段名 | 描述 |
|---|---|
query |
用户可能用来查找法律条款的自然语言搜索查询(土耳其语)。风格多样,包括直接问题、关键词、场景描述和日常语言。 |
positive |
原始权威法律文本(查询的真实答案)。 |
positive_human |
法律文本的简化、通俗土耳其语释义,保留相同信息,更易理解。 |
negative |
硬负例:来自同一法律领域,表面与查询相似但实际上不相关的法律文本。 |
数据模式示例:
- 字段:
id,chunk_id,provision_id,document_title,document_type,document_number,provision_type,provision_number,query,positive,positive_human,negative - 类型:所有字段均为字符串 (
string)。 - 示例:
query为"İş sözleşmesi feshedilirken ihbar süresi ne kadar?",positive为"Belirsiz süreli iş sözleşmelerinin feshinden önce..."。
数据质量评估
自动启发式检查结果(全数据集):
- 错误正例(系统错误):89,314 (7.78%)
- 查询长度:平均值 46 字符
- Positive_human 长度:平均值 180 字符
- 查询与正例 Jaccard 相似度:平均值 0.04(低重叠,表明质量良好)
- 全局重复查询:15.6%
LLM质量评估(10,000条分层样本,使用GPT-4o-mini):
| 评估维度 | 平均得分 (1-5) | 解释 |
|---|---|---|
| positive_human_accuracy | 4.25 | 简化文本较好地保留了原意 |
| negative_hardness | 3.81 | 硬负例具有挑战性和真实性 |
| overall_quality | 3.45 | 可用于训练 |
| query_relevance | 3.20 | 查询相关但自然度不一 |
不同文档类型的平均质量得分:
-
宪法 (Anayasa):3.94
-
法律 (Kanun):3.57
-
公报 (Tebliğ):3.00
-
法令 (KHK):2.78
-
总统令:2.67
-
法规 (Yönetmelik):2.61
-
低质量记录(总分≤2):占样本的 10.85%。
数据清洗
cleaned 子集比 default 子集移除了 104,128 (9.07%) 条记录,具体如下:
| 过滤条件 | 移除数量 |
|---|---|
| Positive字段存在系统错误 | 89,314 |
| 字段长度低于最小阈值 | 14,659 |
| 同一分块内查询重复 | 155 |
预期用途
- 微调多语言或土耳其语专用的嵌入模型(例如
mE5,multilingual-e5,paraphrase-multilingual-mpnet)。 - 在土耳其法律内容上对检索系统进行基准测试。
- 构建用于土耳其法律的检索增强生成(RAG)管道。
- 使用
(query, positive_human)对进行交叉编码器/重排序器训练。 - 法律问答研究。
非预期用途
- 直接法律咨询(本数据集为训练数据,非经过验证的法律意见)。
- 未经领域适配就用于非土耳其法律体系。
许可协议
本数据集基于 Apache 2.0 许可证 发布。底层法律文本来源于公开的土耳其立法,属于公共领域。生成的查询、释义和硬负例在 Apache 2.0 下发布。
搜集汇总
数据集介绍
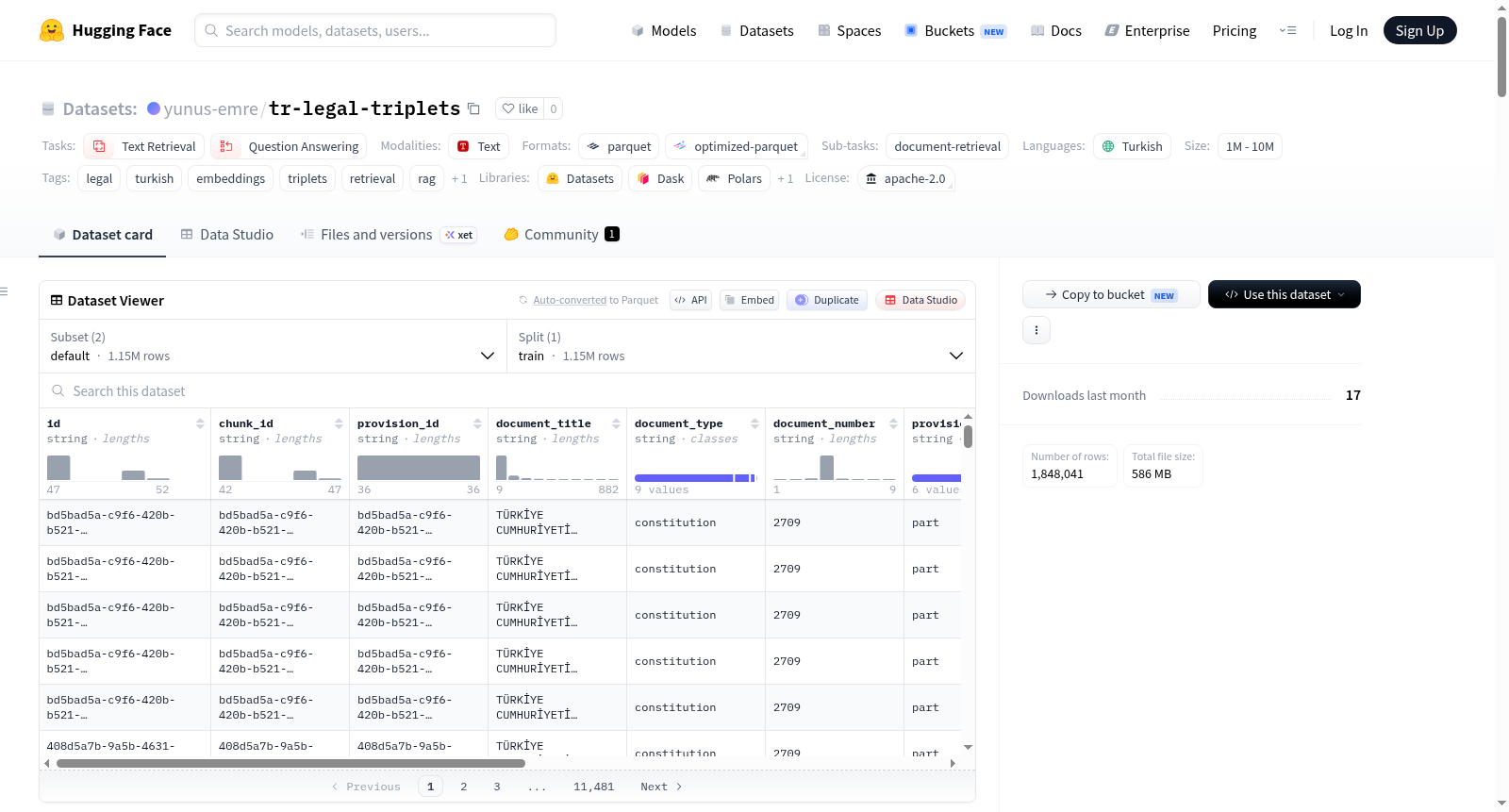
构建方式
该数据集基于土耳其法律领域19,970份现行法律文件构建,涵盖法规、公报、总统令、法律等九类文档类型,共包含163,616条法律条文。构建流程分为三步:首先对原始法律条文进行标准化清洗与噪声去除;其次将超过1,500字符的长文本按1,000字符长度、200字符重叠进行语义切分,最终生成198,789个文本块;最后借助GPT-4o-mini模型,通过土耳其法律领域特定提示词,为每个文本块生成检索三元组。三元组生成数量依据文本块长度动态调整(短文本5组、中文本7组、长文本10组),共计生成1,148,041组三元组。
特点
数据集每条记录由查询、正向文本、正向简化文本及负向文本四个字段构成。查询采用多样化风格生成,包括直接问题、关键词、场景描述及日常用语,模拟真实用户检索行为。正向文本为原始法律条文,正向简化文本则以通俗土耳其语保留原意,便于跨编码器训练。负向文本为同法律领域内具有表面相似性的高难度负样本,可有效提升模型判别能力。数据集提供default与cleaned两个子集,后者已剔除正向字段错误、低信息量及重复查询记录,推荐用于模型训练。
使用方法
用户可通过HuggingFace datasets库加载cleaned子集进行模型微调。在嵌入模型训练场景中,可直接读取查询、正向与负向文本构建三元组损失函数;在跨编码器或重排序模型训练中,则可利用查询与正向简化文本形成配对数据。推荐结合sentence-transformers框架及paraphrase-multilingual-mpnet-base-v2等预训练模型进行微调,适用于土耳其法律领域的检索增强生成(RAG)流水线构建与法律问答研究。
背景与挑战
背景概述
在法律人工智能领域,构建高质量的土耳其语法律文本嵌入模型长期面临标注数据匮乏的困境。土耳其语作为低资源语言,其法律体系涵盖宪法、法律、总统令等多种规范性文件,文本风格高度专业化且结构复杂,导致通用多语言嵌入模型在土耳其法律检索任务中表现不佳。为填补这一空白,研究者yunus-emre于2025年发布了tr-legal-triplets数据集,该数据集依托19,970份现行土耳其法律文件,涵盖163,616个法律条款,系统性地生成了超过114万组查询-正例-负例三元组。每个三元组包含自然语言查询、权威法律原文及其通俗化释义,并设计了领域内的难负样本,旨在为土耳其法律文本的语义检索、问答系统和检索增强生成(RAG)技术提供大规模训练资源。该数据集的创建显著推进了土耳其法律自然语言处理的研究进程,为低资源法律领域嵌入模型的训练与评估建立了基准。
当前挑战
tr-legal-triplets数据集致力于应对两方面的核心挑战。在领域问题层面,其旨在解决土耳其法律文本嵌入模型在检索准确率上的瓶颈,法律文书的冗长句式、术语歧义及跨条款关联性使得传统嵌入方法难以捕捉细粒度语义,而法律检索中高精度要求与低资源语言模型能力之间的鸿沟构成了根本矛盾。在数据构建层面,面临的挑战包括:法律条款长度差异悬殊,需设计合理的分块策略(如以1000字符为窗口、200字符重叠)以保持语义连贯性;通过大语言模型自动生成查询与负样本时需兼顾多样性、真实性与难度,防止低质量问题(如查询与正例的Jaccard相似度仅0.04);此外,数据处理过程中7.78%的源文本不可用错误以及10.85%的低质量样本,凸显了自动化管道中质量控制与错误过滤的复杂性。经清洗后的版本虽去除9.07%的劣质记录,但不同文档类型(如宪法平均质量3.94分VS总统令2.67分)的生成质量差异仍提示领域适配的深层挑战。
常用场景
经典使用场景
在土耳其法律文本检索与语义匹配研究领域,tr-legal-triplets数据集为训练高质量嵌入模型提供了不可多得的基准资源。该数据集精心构造了超过百万条查询-正例-难负例三元组,每条查询以自然语言模拟用户检索法律条款时的多样表达,包括直接提问、关键词组合、场景描述乃至日常用语。正例为权威法律原文及其通俗化改写文本,而负例则从相同法律域中选取表面相关但实际不构成答案的文本片段,极大地提升了模型对细粒度法律语义差异的区分能力。经典使用场景集中于基于三重损失函数的嵌入模型微调,通过Sentence-Transformers等框架加载语料,在批量训练中强化模型对土耳其语法律文本的语义编码能力,最终生成能够精准匹配查询与相应法律条款的高质量嵌入向量。
实际应用
在实际应用层面,tr-legal-triplets最直接的价值在于赋能土耳其法律领域的检索增强生成(RAG)系统构建。法律从业者如律师、法官及法务人员,常需要从浩如烟海的现行法规中快速定位某项具体条款,而该数据集训练出的嵌入模型可无缝嵌入RAG管线,将非结构化的法律语言查询转化为高精度向量检索,从近二十万条法规条款中召回最相关的段落。进一步地,数据集中提供的通俗化正例(positive_human)还可用于训练跨编码器重排序模型,对初筛结果进行语义层级精排,显著提升最终答案的相关性。此外,土耳其政府机构或法律科技公司可利用此数据搭建智能法规助手,使公民能够以日常土耳其语提问方式获取准确的法律依据,降低法律信息获取的门槛。
衍生相关工作
围绕tr-legal-triplets数据集,学术界已经涌现出一系列衍生性工作,进一步拓展了其研究价值。在模型微调方向上,研究者基于该数据集对比了mE5、multilingual-e5及paraphrase-multilingual-mpnet-base-v2等多语言嵌入模型在土耳其法律语料上的域适应效果,揭示了不同预训练策略对法律文本语义对齐能力的影响。在数据增强领域,有工作探索了利用positive_human字段训练生成式法律文本简化模型,使原本晦涩的法规语言自动转化为平实表述,服务于司法领域的可读性提升。此外,该数据集中的难负例构造策略启发了后续针对其他低资源语言(如阿拉伯语、波斯语)法律三元组数据集的构建方案,形成了可迁移的生成流水线方法论,推动了多语言法律检索研究的系统化发展。
以上内容由遇见数据集搜集并总结生成


