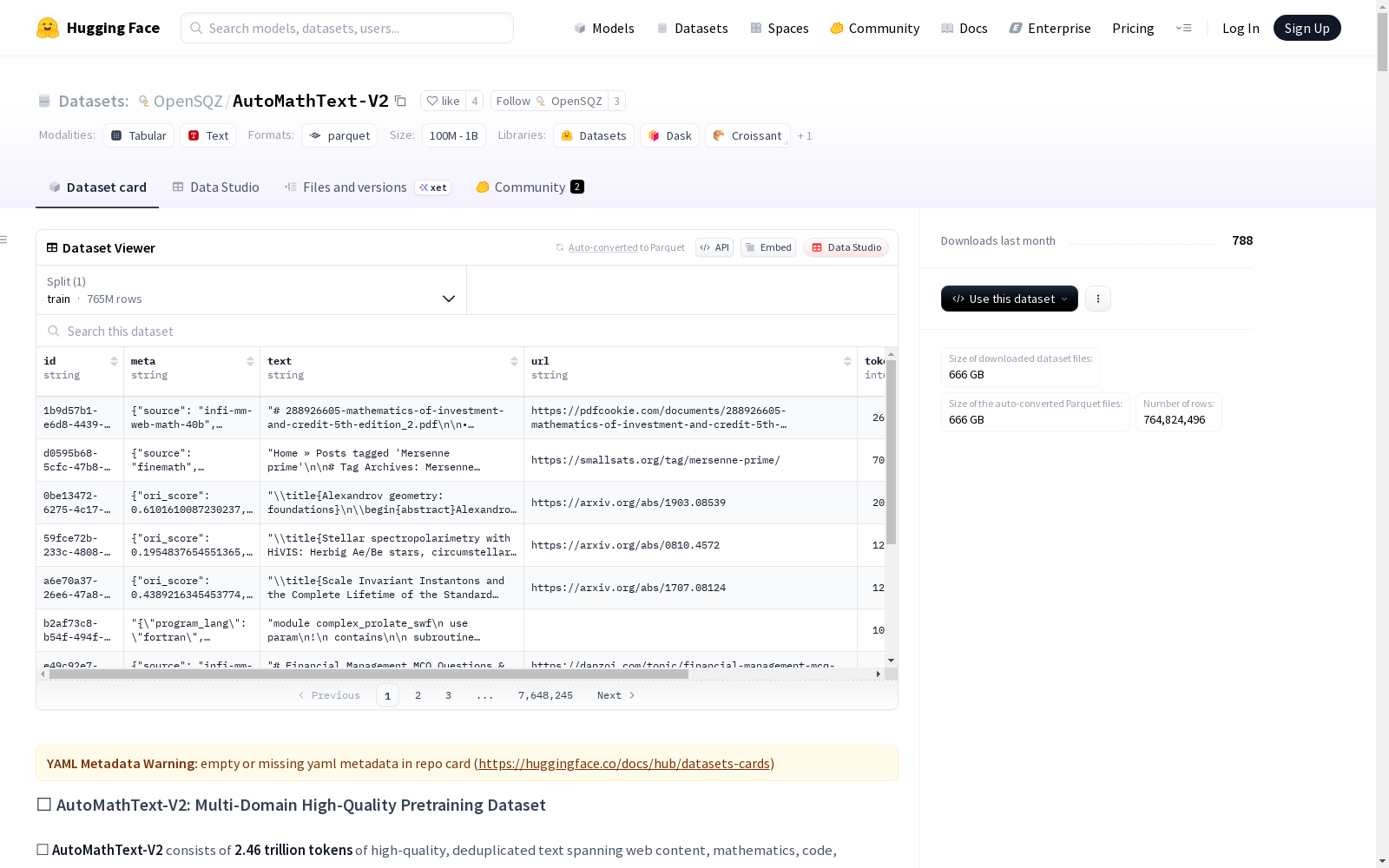
AutoMathText-V2
收藏AutoMathText-V2 数据集概述
数据集基本信息
- 名称:AutoMathText-V2
- 总规模:2.46万亿个token
- 核心特征:高质量、去重文本数据,涵盖网页内容、数学、代码、推理和双语数据
- 处理技术:三重去重流水线、AI驱动的质量评估
数据集组成
领域分布
| 领域 | Token数量 | 占比 | 描述 |
|---|---|---|---|
| Nemotron CC High | 1,468.3B | 59.7% | 高质量CommonCrawl数据 |
| DCLM | 314.2B | 12.8% | DCLM基线网页内容 |
| RefineCode | 279.4B | 11.4% | GitHub仓库(仅学术使用) |
| Nemotron CC Medium-High | 254.5B | 10.3% | 中高质量CommonCrawl数据 |
| FineWeb Edu | 117.4B | 4.8% | 教育网页内容 |
| Chinese | 112.18B | 4.6% | 中文通用内容 |
| Reasoning QA | 86.2B | 3.5% | 指令遵循和复杂推理任务 |
| Math Web | 68.3B | 2.8% | 数学和科学内容 |
| MegaMath | 28.5B | 1.2% | 专业数学集合 |
| Translation | 1.61B | 0.1% | 英中翻译对 |
数据来源
共包含52个优质数据源,按领域分类:
DCLM领域
- DCLM-Baseline:高质量网页内容
FineWeb Edu领域
- FineWeb-Edu:教育网页内容(0-5质量评分)
FineWeb Edu中文领域
- FineWeb-Edu-Chinese:中文教育内容(3.4-5.0评分)
Math Web领域
- AutoMathText:数学/代码/ArXiv内容
- FineMath:高质量数学内容
- Open-Web-Math-Pro:数学网页
- InfiMM-WebMath-40B:多模态数学内容
Nemotron CC High领域
- Nemotron-CC (High):高质量CommonCrawl子集
Nemotron CC Medium-High领域
- Nemotron-CC (Medium-High):中高质量CommonCrawl子集
RefineCode领域
- RefineCode:GitHub仓库(仅学术使用)
Reasoning QA领域
- 包含35个推理相关数据集,涵盖代码训练、指令遵循、思维链推理、数学问题求解等
Translation领域
- UN-PC:英中翻译对
- UN-PC-Reverse:中英翻译对
MegaMath领域
- MegaMath-QA:大规模数学QA
- MegaMath-Translated-Code:数学代码翻译
- MegaMath-Text-Code-Block:混合数学文本和代码块
处理流程
数据提取与标准化
采用标准化JSON格式,包含域前缀、ID、元数据、文本、token计数、URL和质量评分
三重去重
- 精确去重:SHA256内容哈希,移除约30%精确重复
- 模糊去重:MinHash LSH,Jaccard相似度阈值0.9,移除约20%近似重复
- 语义去重:GTE多语言嵌入,余弦相似度阈值0.007,移除约10%语义重复
AI质量评估
基于Qwen2的分类器架构,微调回归头进行质量评分,多源分数归一化和融合
高级文本清理
- 编码修复和损坏过滤
- LaTeX和代码保护
- 智能社交媒体过滤
- URL规范化
- 文档伪影移除
- 双语支持
污染检测
自动测试集泄露检测和移除,保护数学数据集测试问题和GSM8K评估问题
使用方式
加载数据集
python from datasets import load_dataset
加载完整数据集
dataset = load_dataset("OpenSQZ/AutoMathText-V2", streaming=True)
加载特定领域
math_data = load_dataset("OpenSQZ/AutoMathText-V2", name="math_web", streaming=True)
RefineCode内容下载
RefineCode域仅包含元数据,需使用blob_id从AWS S3下载实际代码内容
数据集结构
目录结构
按领域和质量百分位组织:
- 10个质量百分位(0-10, 10-20, ..., 90-100)
- 每个百分位包含等量token
- 基于AI分类器质量评分进行百分位排名
可用配置
- 领域特定配置
- 质量过滤配置
- Nemotron变体
- 组合配置
- 自定义采样
语言分布
- 英语:约70-80%
- 中文:约15-20%
使用注意事项
社会影响
旨在为ML社区提供高质量训练数据的民主化访问,通过透明处理方法和全面文档,使研究人员能够构建更好的语言模型
已知限制
- 代码内容可能少于专业代码数据集
- RefineCode仅限于学术研究使用
- 部分内容格式可能不如精选源优化
- 网页来源内容可能包含在线文本中的偏见
- 某些专业领域覆盖有限
偏见考虑
- 过滤方法避免过度依赖与"黄金"源的相似性
- URL级过滤减少NSFW内容但不完全消除
- 地理和语言偏见可能反映网页内容分布
- 质量分类器在多样化代表性样本上训练
许可与引用
许可证
基于Apache 2.0许可证发布,最大限度实现可访问性和研究使用
重要说明:RefineCode组件(GitHub仓库)仅限于学术研究使用,禁止商业使用
引用
bibtex @dataset{automath_text_v2_2025, title = {AutoMathText-V2: Multi-Domain High-Quality Pretraining Dataset}, author = {Chao Li, Yifan Zhang}, year = {2025}, url = {OpenSQZ/AutoMathText-V2}, publisher = {Hugging Face}, note = {A comprehensive pretraining dataset with advanced deduplication and quality assessment} }