DisfluencySpeech
收藏arXiv2024-06-13 更新2024-06-21 收录
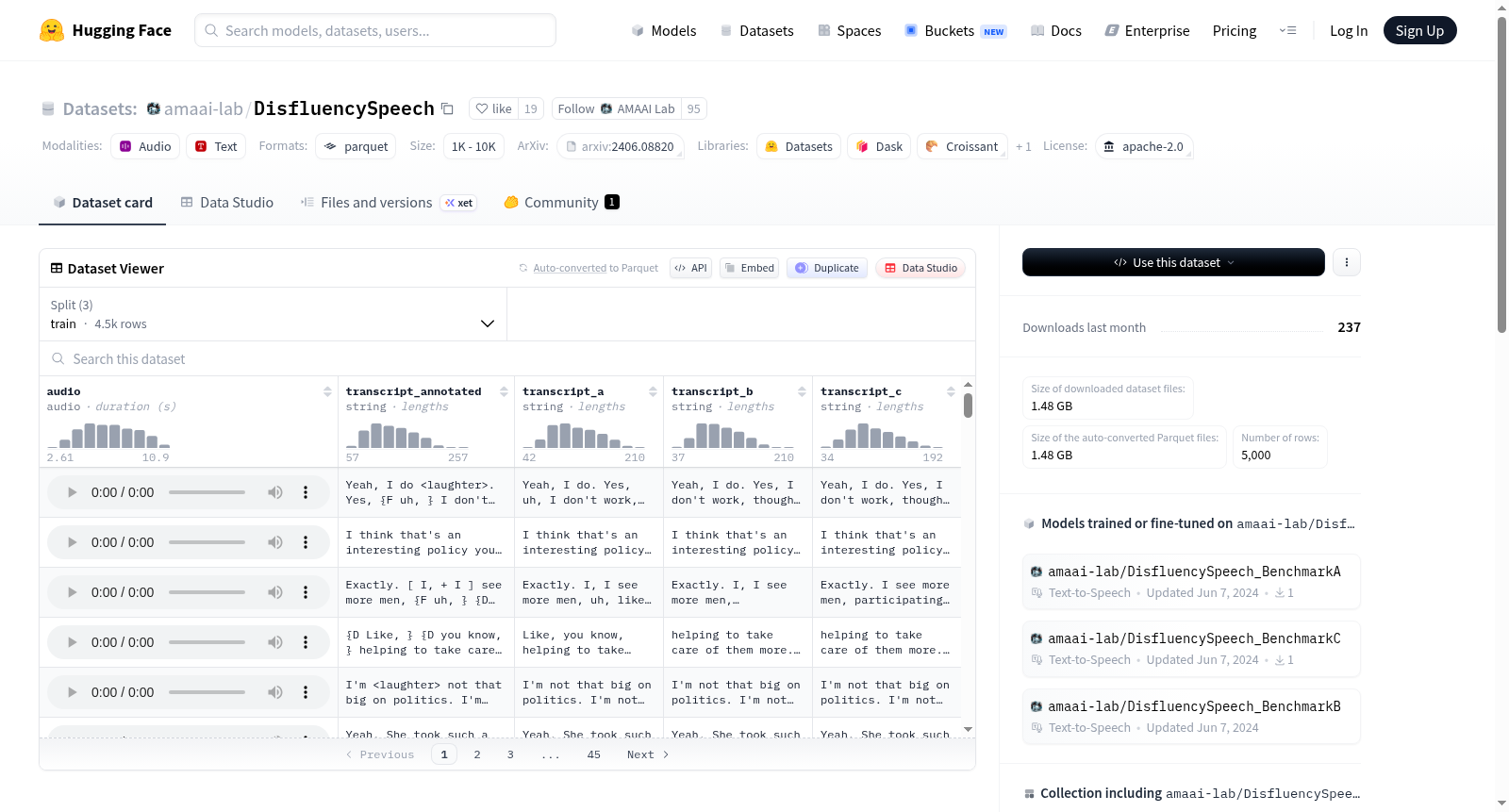
下载链接:
https://huggingface.co/datasets/amaai-lab/DisfluencySpeech
下载链接
链接失效反馈官方服务:
资源简介:
DisfluencySpeech是由新加坡科技设计大学信息系统技术与设计部门创建的单人英语口语数据集,包含近10小时的表达性语音数据,源自Switchboard电话语音语料库。该数据集专注于非词汇语音特征,如笑声和叹息,以及言语不流畅性,旨在帮助开发能够从文本中预测性合成具有语义意义的副语言的TTS模型。数据集创建过程中,通过专业录音室录制,并提供了三种不同信息级别的转录文本,以支持TTS模型的训练。该数据集适用于提升人机交互中语音合成的自然度和表达性。
DisfluencySpeech is a single-speaker English spoken dataset developed by the Department of Information Systems Technology and Design, Singapore University of Technology and Design. It contains nearly 10 hours of expressive speech data sourced from the Switchboard telephone speech corpus. This dataset focuses on non-lexical speech features such as laughter and sighs, as well as speech disfluencies, with the goal of facilitating the development of TTS models capable of predictively synthesizing semantically meaningful paralinguistic elements from text. During its creation, the dataset was recorded in professional recording studios, and three transcriptions with different levels of informational detail are provided to support the training of TTS models. This dataset can be used to enhance the naturalness and expressiveness of speech synthesis in human-computer interaction scenarios.
提供机构:
新加坡科技设计大学信息系统技术与设计
创建时间:
2024-06-13
搜集汇总
数据集介绍
构建方式
在语音合成领域,构建能够模拟真实对话中非语言成分的数据集对提升人工智能社交代理的自然度至关重要。DisfluencySpeech数据集的构建过程始于从Switchboard对话行为语料库中提取原始文本,通过合并子话语并筛选出15至35个单词的语句,确保每个话语既包含足够的语义信息又便于模型处理。随后,在专业录音棚中,由一位以英语为母语的新加坡籍说话者以对话方式朗读包含所有非语言事件标注的文本,模拟真实对话场景。录音采用标准化设备与环境控制,最终生成约10小时的高质量单说话者语音数据,并经过后处理提供强制对齐资源,确保数据的一致性与可用性。
特点
该数据集的显著特点在于其全面覆盖了对话语音中的非语言成分,包括填充停顿、明确编辑词、话语标记以及笑声和叹息等非语音事件。与现有数据集相比,DisfluencySpeech不仅提供了详细的非语言成分标注,还创新性地提供了三种不同信息移除级别的转录文本,从保留所有非句子元素到仅保留核心语义内容,为研究语音合成模型如何从文本中预测性生成语义相关的非语言成分提供了多层次实验基础。此外,数据集采用与LJSpeech兼容的格式,确保了与现有语音合成流程的无缝集成,并附带了基准模型权重和定制化的声学资源,极大便利了后续研究工作的开展。
使用方法
在语音合成研究中,DisfluencySpeech数据集主要用于训练能够理解和生成语义相关非语言成分的对话式文本转语音模型。研究人员可利用其提供的三种转录文本,分别探索模型在不同信息完整性下的表现,例如使用转录A训练模型以合成包含非句子元素的自然对话,或使用转录C挑战模型从纯文本中预测性生成非语言事件的能力。数据集附带的基准Transformer模型权重和微调后的HiFiGAN声码器可作为性能比较的基线,而Montreal Forced Aligner资源则支持非自回归模型的强制对齐需求。通过结合客观评估指标如梅尔倒谱失真和字符错误率,研究者能够系统评估模型在合成自然度和语义准确性方面的表现。
背景与挑战
背景概述
在非正式口语交流中,副语言如笑声、叹息、口吃等非词汇性成分虽不直接传递语义信息,却对语境理解与情感表达具有关键作用。为推进具备副语言生成能力的对话式语音合成技术,新加坡科技设计大学的研究团队于近年创建了DisfluencySpeech数据集。该数据集基于Switchboard电话语音语料库,由单一说话者模拟真实对话录制近10小时高质量音频,并提供了包含不同信息层级的转录文本。其核心研究在于探索如何使文本到语音模型能够从纯文本中预测并合成语义恰当的副语言,从而增强人工智能社交代理的自然交互能力,对语音合成领域向更富表现力的方向发展产生了积极影响。
当前挑战
DisfluencySpeech数据集旨在解决对话式语音合成中副语言建模的挑战,即如何使模型从文本中预测并生成如笑声、叹息等非词汇性声音以及口吃等不流利现象,以提升合成语音的自然度与情感表现力。在构建过程中,研究团队面临多重困难:现有语音数据集大多缺乏副语言的详细标注,且多说话者数据集中每个说话者的音频量有限,难以训练高质量的单说话者模型;数据集录制需模拟真实对话的副语言特征,对说话者的表演能力与录音环境的一致性提出较高要求;此外,为支持模型从不同信息层级的文本中学习副语言生成,需设计并验证多种转录方案,这增加了数据标注与后期处理的复杂性。
常用场景
经典使用场景
在语音合成领域,自然对话的生成常因缺乏副语言元素而显得生硬。DisfluencySpeech数据集通过提供包含填充停顿、笑声、叹息等副语言标注的单一说话者语音,为训练具备副语言生成能力的对话式文本到语音模型提供了关键资源。其经典使用场景在于,研究者可利用该数据集训练能够从文本中预测并合成语义相关副语言的TTS系统,从而生成更自然、富有表现力的对话语音。
实际应用
在实际应用中,DisfluencySpeech可用于开发更人性化的语音助手、虚拟角色或教育工具。例如,在客户服务或陪伴型机器人中,合成带有自然犹豫或笑声的语音能增强交互的真实感与亲和力。此外,该数据集也有助于改进自动语音识别系统对非流畅语音的处理能力,提升其在真实对话环境中的鲁棒性,为多模态人机交互系统的设计提供语音层面的支持。
衍生相关工作
基于DisfluencySpeech,研究者可开展多项衍生工作。例如,探索使用Transformer等先进架构训练能够从简化文本中预测副语言的TTS模型,或结合强制单调对齐技术以改善长语句的合成质量。该数据集还可用于副语言生成的控制研究,如通过调节输入文本的语义特征来触发特定的非词汇声音。此外,其多层级转录本为研究文本信息缺失下的语音合成对齐问题提供了基准,促进了对话语音合成领域的算法创新。
以上内容由遇见数据集搜集并总结生成


