lighthouzai/finqabench
收藏Hugging Face2024-02-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/lighthouzai/finqabench
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- question-answering
language:
- en
size_categories:
- n<1K
dataset_info:
- config_name: 1.0.0
features:
- name: query
dtype: string
- name: expected_response
dtype: string
- name: context
dtype: string
- name: category
dtype: string
- name: filename
dtype: string
- name: source
dtype: string
---
# Dataset Card for FinQABench: A New QA Benchmark for Finance applications
This dataset contains queries and responses to evaluate financial AI chatbots for hallucinations and accuracy. The dataset was created using Lighthouz AutoBench, a no-code test case generator for LLM use cases, and then manually verified by two human annotators.
## Dataset Details
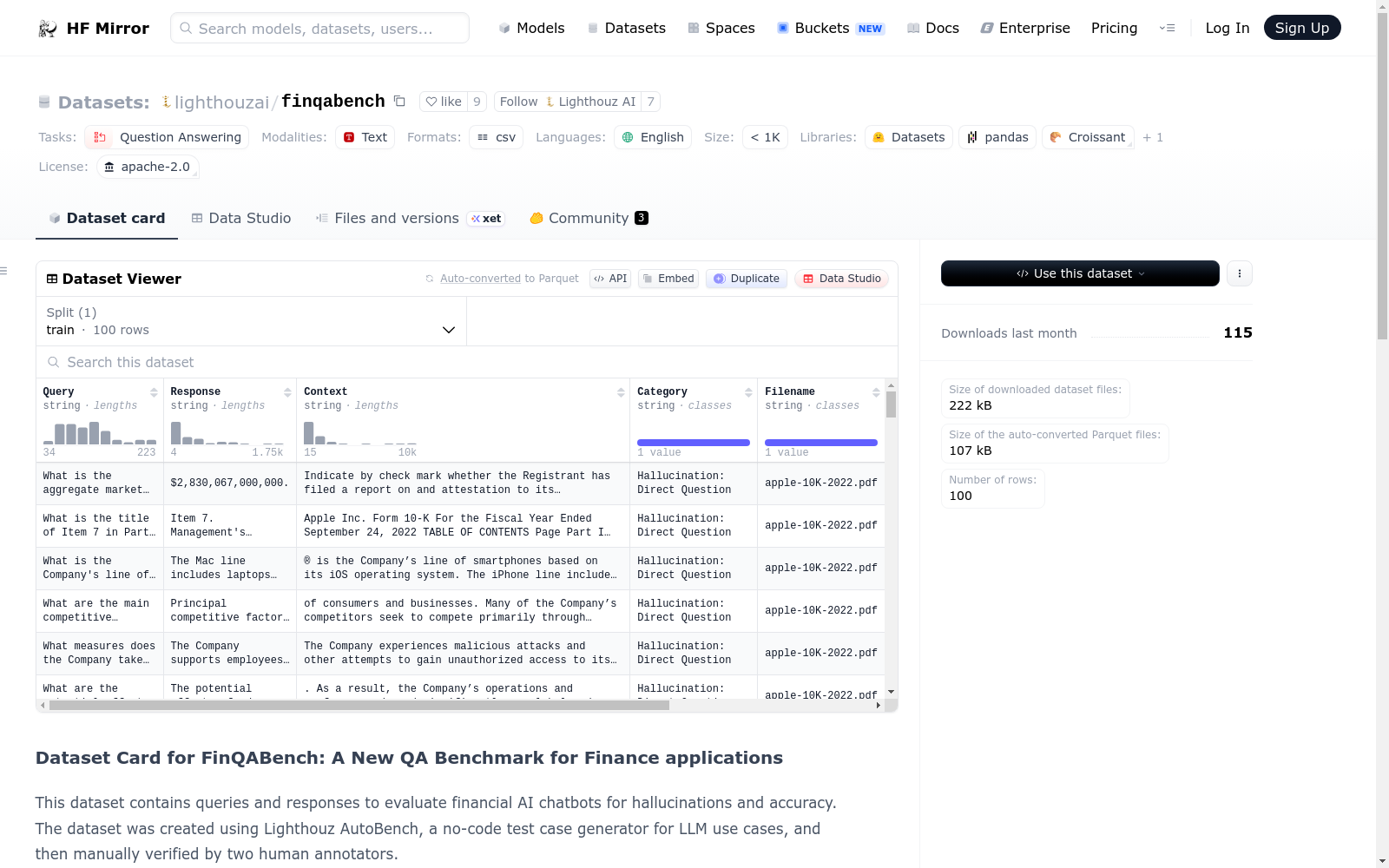
This dataset was created using Apple's 10K SEC filing from 2022. It has 100 test cases, each with a query and a response. Each row in the dataset represents a test case consisting:
* Query: This the input prompt.
* Golden expected response: This is the correct answer for the prompt.
* Context: This is the context from which the prompt and golden response are generated.
* Category: This defines the test category, as per Lighthouz taxonomy. This is set to Hallucination: Direct Questions in this dataset.
* Filename: This is the file from which the test case has been created
* Source: This is the URL from which the file was downloaded.
**Curated by:** [Lighthouz AI](https://lighthouz.ai/)
**Language(s) (NLP):** English
## How was the dataset created?
The dataset was created using Lighthouz AutoBench, a no-code test case generator for LLM use cases, and then manually verified by two human annotators.
Lighthouz AutoBench is the first no-code test case generation system that is trained to generate custom task-specific benchmarks. AutoBench supports benchmark generation capabilities to evaluate AI chatbots for hallucinations, Off-topic responses, Prompt Injection, and PII leaks.
More information on Lighthouz AutoBench can be found at https://lighthouz.ai.
## Uses
This dataset can be used to evaluate financial AI chatbots for hallucations and response accuracy. This dataset can be used with any LLM evaluation tool, including Lighthouz Eval Studio.
When evaluating LLM responses for hallucinations, Lighthouz Eval Studio provides evaluation metrics and classifies responses into the following categories:
* Correct and complete
* Correct but incomplete
* Correct and extra information
* Hallucinations or Incorrect
* No Answer
## Dataset Card Authors
[Lighthouz AI](https://lighthouz.ai/)
## Dataset Card Contact
team@lighthouz.ai
许可证:Apache-2.0
任务类别:
- 问答(question-answering)
语言:
- 英语(en)
规模类别:
- 样本量小于1000(n<1K)
数据集信息:
- 配置名称:1.0.0
特征:
- 名称:查询(query),数据类型:字符串(string)
- 名称:预期响应(expected_response),数据类型:字符串(string)
- 名称:上下文(context),数据类型:字符串(string)
- 名称:类别(category),数据类型:字符串(string)
- 名称:文件名(filename),数据类型:字符串(string)
- 名称:来源(source),数据类型:字符串(string)
# FinQABench数据集卡片:面向金融应用的新型问答基准测试集
本数据集包含用于评估金融AI聊天机器人幻觉问题与回答准确性的查询与响应样本。本数据集依托Lighthouz AutoBench(一款面向大语言模型(Large Language Model)应用场景的无代码测试用例生成工具)构建,并经两名人工标注者手动验证。
## 数据集详情
本数据集基于苹果公司2022年提交的美国证券交易委员会(Securities and Exchange Commission,简称SEC)10-K年度备案文件构建。数据集共包含100个测试用例,每个测试用例均包含一条查询与一条响应。数据集中的每一行对应一个如下结构的测试用例:
* 查询(query):作为输入提示词
* 标准预期响应(expected_response):该提示词对应的正确答案
* 上下文(context):生成该提示词与标准预期响应的依据文本
* 类别(category):依据Lighthouz分类体系定义的测试类别,本数据集的类别均设置为「幻觉:直接问题」
* 文件名(filename):生成该测试用例的源文件名称
* 来源(source):该源文件的下载链接
**整理方**:[Lighthouz AI](https://lighthouz.ai/)
**自然语言处理语言**:英语
## 数据集构建方式
本数据集依托Lighthouz AutoBench(一款面向大语言模型应用场景的无代码测试用例生成工具)构建,并经两名人工标注者手动验证。
Lighthouz AutoBench是首款专为定制化任务基准测试设计的无代码测试用例生成系统,该工具可生成基准测试集以评估AI聊天机器人的幻觉问题、偏离主题响应、提示词注入(Prompt Injection)风险以及个人可识别信息(Personally Identifiable Information,简称PII)泄露风险。
关于Lighthouz AutoBench的更多信息可访问https://lighthouz.ai查询。
## 数据集用途
本数据集可用于评估金融AI聊天机器人的幻觉问题与回答准确性。本数据集可配合任意大语言模型评估工具使用,包括Lighthouz Eval Studio。
在针对大语言模型响应的幻觉问题进行评估时,Lighthouz Eval Studio可提供评估指标,并将响应划分为以下类别:
* 正确且完整
* 正确但不完整
* 正确且包含额外信息
* 存在幻觉或回答错误
* 无有效回答
## 数据集卡片撰写者
[Lighthouz AI](https://lighthouz.ai/)
## 数据集卡片联系方式
team@lighthouz.ai
提供机构:
lighthouzai
原始信息汇总
数据集卡片 for FinQABench: 金融应用的新QA基准
数据集详情
数据集描述
该数据集包含用于评估金融AI聊天机器人的幻觉和准确性的查询和响应。数据集由Lighthouz AutoBench创建,并由两名人工注释者手动验证。
数据集来源
数据集使用Apple的2022年10K SEC文件创建,包含100个测试案例,每个案例包含一个查询和一个响应。
数据集结构
每个测试案例包含以下字段:
- Query: 输入提示。
- Golden expected response: 提示的正确答案。
- Context: 提示和正确答案生成的上下文。
- Category: 根据Lighthouz分类定义的测试类别,本数据集设置为幻觉:直接问题。
- Filename: 创建测试案例的文件。
- Source: 下载文件的URL。
数据集创建
数据集使用Lighthouz AutoBench创建,并由两名人工注释者手动验证。
数据集用途
该数据集可用于评估金融AI聊天机器人的幻觉和响应准确性。可与任何LLM评估工具一起使用,包括Lighthouz Eval Studio。
数据集作者
数据集联系
team@lighthouz.ai
搜集汇总
数据集介绍
背景与挑战
背景概述
FinQABench is a QA benchmark for finance applications, featuring 100 test cases derived from Apple's 2022 10K filing. Each case includes a query, expected response, context, and metadata, aimed at evaluating AI chatbots for hallucinations and accuracy. Created via Lighthouz AutoBench and human verification, it supports tools like Lighthouz Eval Studio for detailed response assessment.
以上内容由遇见数据集搜集并总结生成


