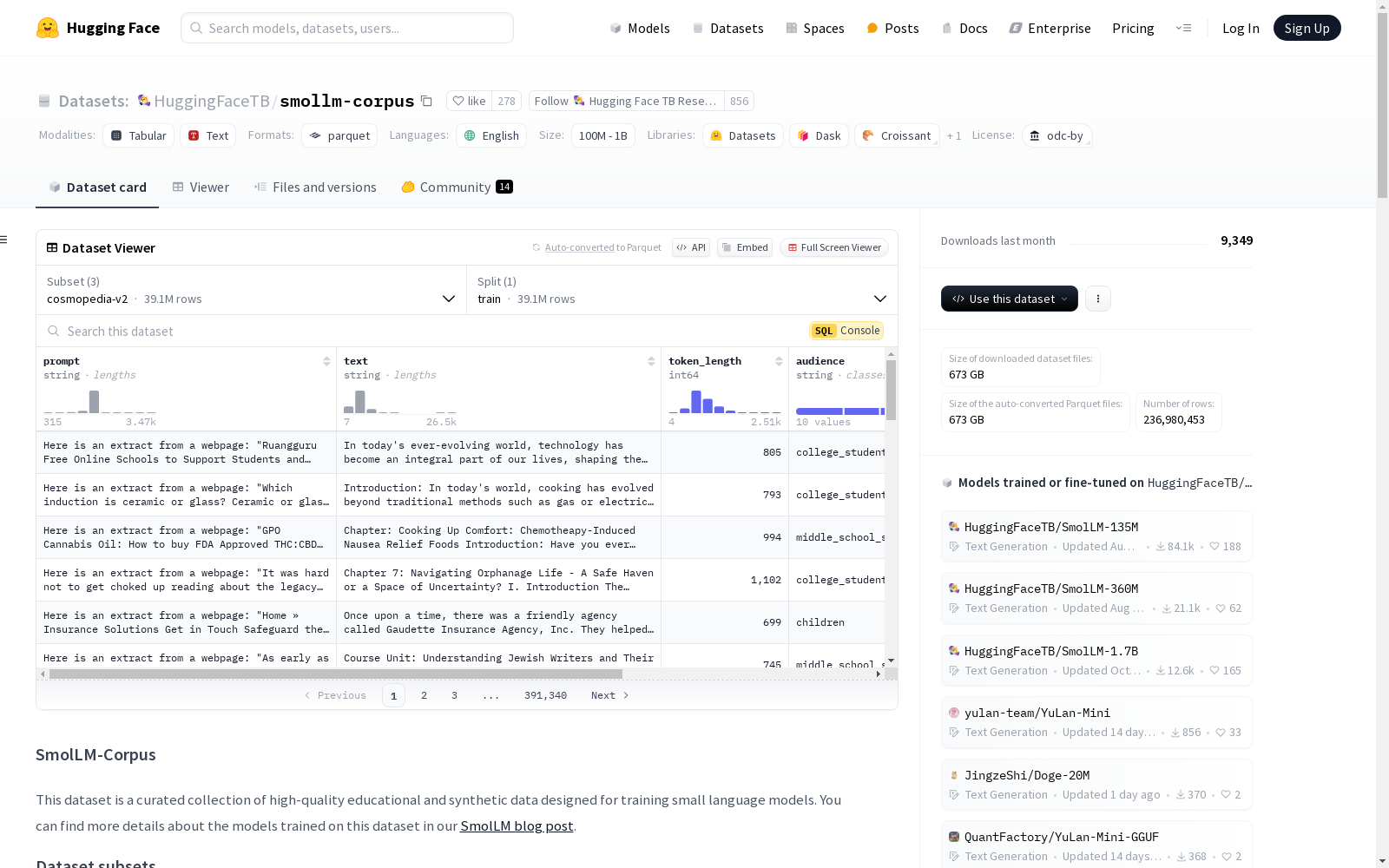
smollm-corpus
收藏SmolLM-Corpus 数据集概述
数据集子集
Cosmopedia v2
- 配置名称: cosmopedia-v2
- 特征:
prompt (string): 用于生成文本的输入提示。text (string): 生成的文本内容。token_length (int64): 文本的标记长度(使用 Mistral-7B 分词器)。audience (string): 内容的预期受众。format (string): 内容的格式(例如,教科书、故事)。seed_data (string): 用于生成文本的种子样本。
- 分割:
train: 包含 39,134,000 个样本,总字节数为 212,503,640,747。
- 下载大小: 122,361,137,711 字节
- 数据集大小: 212,503,640,747 字节
Python-Edu
- 配置名称: python-edu
- 特征:
blob_id (string): 文件在 AWS S3 上的 Software Heritage (SWH) ID。repo_name (string): GitHub 上的仓库名称。path (string): 仓库内的文件路径。length_bytes (int64): 文件内容的 UTF-8 字节长度。score (float32): 教育评分模型的输出。int_score (uint8): 四舍五入的教育评分。
- 分割:
train: 包含 7,678,448 个样本,总字节数为 989,334,135。
- 下载大小: 643,903,049 字节
- 数据集大小: 989,334,135 字节
FineWeb-Edu (去重)
- 配置名称: fineweb-edu-dedup
- 特征:
text (string): 网页的文本内容。id (string): 网页的唯一 ID。metadata (struct): 网页的元数据,包括:dump (string): 源 CommonCrawl 转储。url (string): 网页的 URL。date (timestamp[s]): 网页被捕获的日期。file_path (string): commoncrawl 快照的文件路径。language (string): 网页的语言。language_score (float64): 语言概率。token_count (int64): 网页的标记计数(使用 gpt2 分词器)。score (float64): 教育质量评分。int_score (int64): 四舍五入的教育质量评分。
- 分割:
train: 包含 190,168,005 个样本,总字节数为 957,570,164,451。
- 下载大小: 550,069,279,849 字节
- 数据集大小: 957,570,164,451 字节
加载数据集
Cosmopedia v2
python from datasets import load_dataset
ds = load_dataset("HuggingFaceTB/smollm-corpus", "cosmopedia-v2", split="train", num_proc=16) print(ds[0])
Python-Edu
python import boto3 import gzip from datasets import load_dataset
num_proc = 16 s3 = boto3.client(s3) bucket_name = "softwareheritage"
def download_contents(blob_id): key = f"content/{blob_id}" obj = s3.get_object(Bucket=bucket_name, Key=key) with gzip.GzipFile(fileobj=obj[Body]) as fin: content = fin.read().decode("utf-8", errors="ignore") return {"text": content}
ds = load_dataset("HuggingFaceTB/smollm-corpus", "python-edu", split="train", num_proc=num_proc) ds = ds.map(download_contents, input_columns="blob_id", num_proc=num_proc) print(ds[0])
FineWeb-Edu (去重)
python from datasets import load_dataset
ds = load_dataset("HuggingFaceTB/smollm-corpus", "fineweb-edu-dedup", split="train", num_proc=16) print(ds[0])
引用
@software{benallal2024smollmcorpus, author = {Ben Allal, Loubna and Lozhkov, Anton and Penedo, Guilherme and Wolf, Thomas and von Werra, Leandro}, title = {SmolLM-Corpus}, month = July, year = 2024, url = {https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus} }