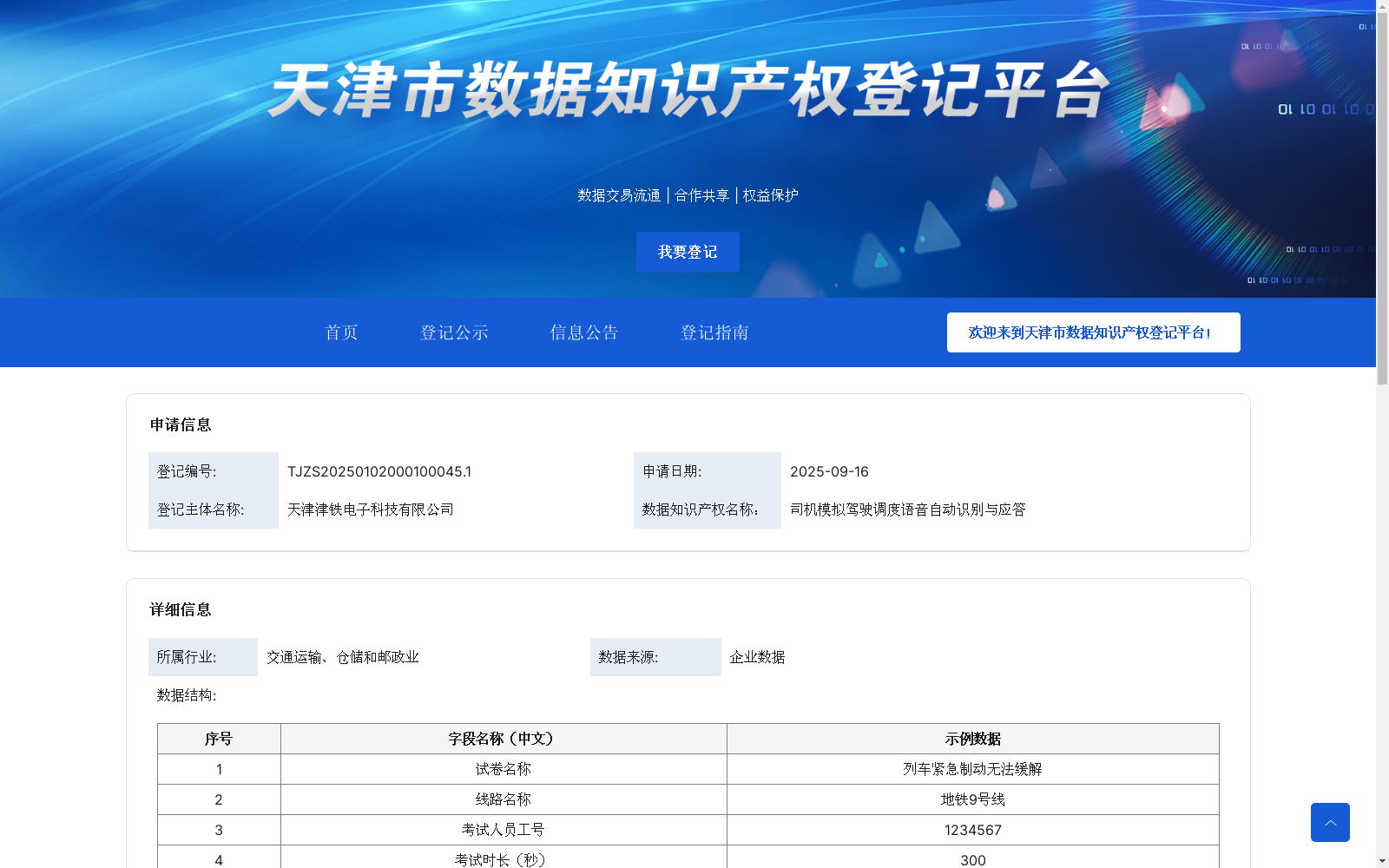
司机模拟驾驶调度语音自动识别与应答
收藏天津市数据知识产权登记平台2025-09-19 更新2025-09-29 收录
下载链接:
https://dengji.tjippc.cn/xxgg_nr?id=0286370d-b4c3-4430-8a54-e03834bb65f6
下载链接
链接失效反馈官方服务:
资源简介:
深度学习语音识别算法的核心思想是将语音信号的声学特征与相应的结果进行对齐,然后利用深度神经网络对其进行训练识别。这一过程主要包括语音信号采集、预处理、特征提取、模型训练和识别等步骤。
1.语音信号采集:通过麦克风等设备将人类语音信号采集到计算机中。
2.预处理:对采集到的语音信号进行滤波、降噪、分帧等处理,以提高识别准确率。预处理步骤有助于去除噪声和干扰,使语音信号更适合后续的特征提取和模型训练。
3.特征提取:从预处理后的语音信号中提取有意义的特征。常用的声学特征包括梅尔倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC)、线性预测倒谱系数(Linear Predictive Cepstral Coefficients,LPCC)等。这些特征能够反映语音信号的重要信息,有助于模型的训练和识别。
4.模型训练:使用特征向量训练语音识别模型。卷积神经网络(CNN)在语音识别中表现出色。模型通过自动学习特征和模式,能够构建出高效的声学模型。在训练过程中,需要使用大量的标记数据进行训练,并通过反向传播算法调整模型参数以优化模型性能。
识别:将数据通过训练好的模型进行识别,得到结果。
提供机构:
天津津铁电子科技有限公司
创建时间:
2025-09-16
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集名为'司机模拟驾驶调度语音自动识别与应答',由天津津铁电子科技有限公司提供,专注于交通运输行业的地铁司机模拟驾驶培训。数据集包含1000条结构化数据,涵盖语义识别标志和关键字等字段,用于通过深度学习算法自动识别和应答司机语音,解决培训中的语音交互问题,提升真实体验。
以上内容由遇见数据集搜集并总结生成


