libritts-mimi-tokens
收藏Hugging Face2026-05-15 更新2026-05-16 收录
下载链接:
https://huggingface.co/datasets/Trelis/libritts-mimi-tokens
下载链接
链接失效反馈官方服务:
资源简介:
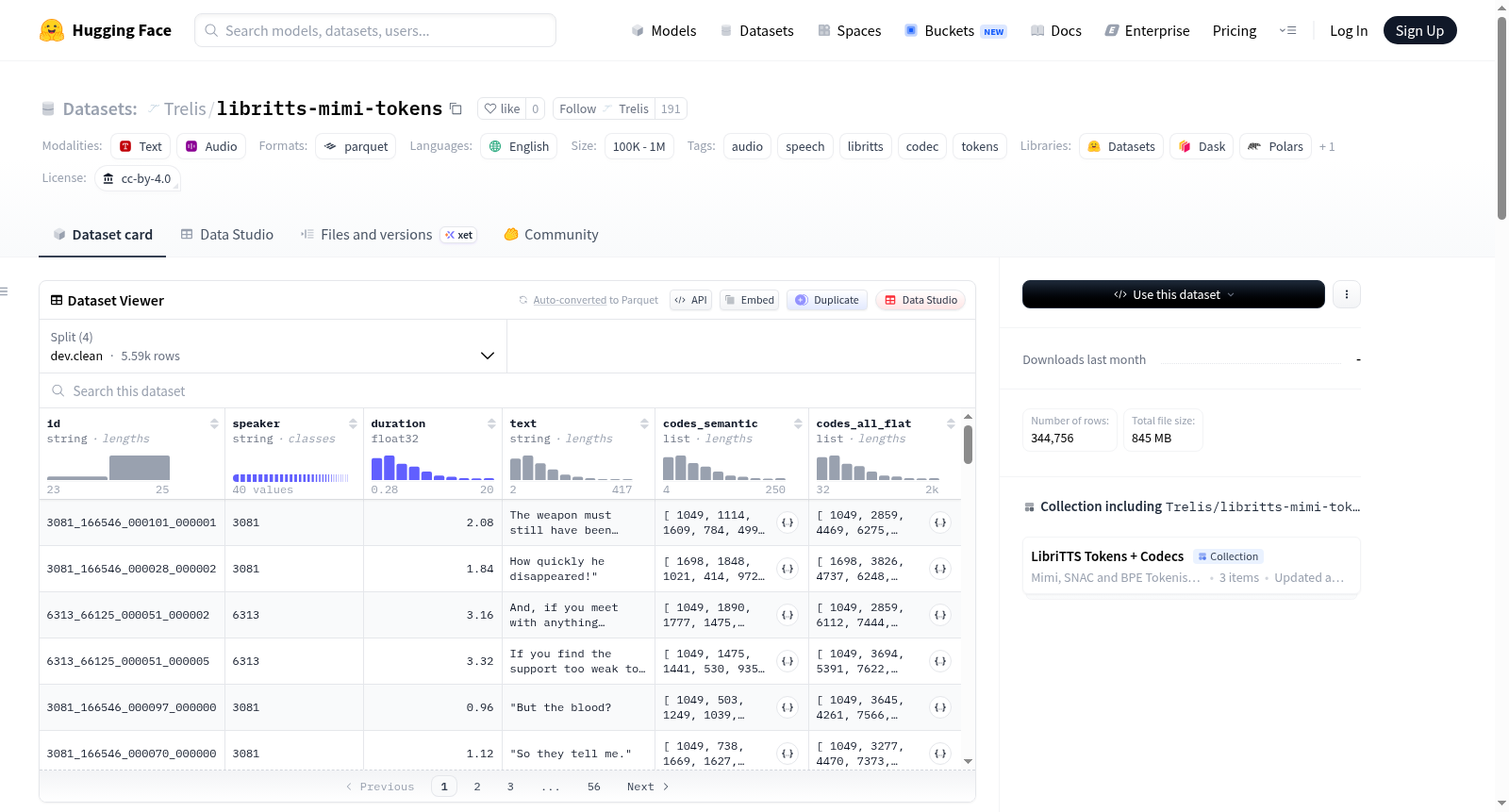
libritts-mimi-tokens是一个基于LibriTTS-R语音库构建的音频token数据集,使用kyutai/mimi模型(一种RVQ编解码器,包含8个码本,每个码本2048个条目)对原始音频进行编码,生成了两种时间分辨率不同的离散token序列。核心数据内容包括:1) `codes_semantic`:仅包含第0码本(基于WavLM蒸馏、内容对齐)的语义token序列,采样率为12.5帧/秒,词汇表大小为2048;2) `codes_all_flat`:将所有8个码本的token按帧交错排列并进行了偏移映射的扁平化序列,采样率为100帧/秒,有效词汇表大小为16384(偏移后),便于扁平语言模型区分不同码本。数据集遵循原始LibriTTS-R经过过滤后的划分,包含四个互不重叠(无说话人重叠)的子集:`train.clean.100`(约3.2万语句,53小时)、`train.clean.360`(约11.2万语句,218小时)、`train.other.500`(约25万语句,258小时)和`dev.clean`(约5600语句,9小时),总计约538小时。每条数据样本对应一个话语(utterance),包含以下字段:唯一标识符`id`、说话人ID`speaker`、音频时长`duration`(秒)、归一化文本`text`以及上述两个token序列。该数据集适用于语音语言建模、神经编解码器建模、语音合成等任务。音频预处理方面,原始24 kHz音频被直接用于Mimi编码,超过20秒的话语被截断(但文本保留完整)。数据集采用CC-BY-4.0许可协议。
提供机构:
Trelis创建时间:
2026-05-15
原始信息汇总
数据集概述
数据集名称:libritts-mimi-tokens
许可证:CC-BY-4.0
语言:英语
数据集大小:100K < 样本数 < 1M(总计约538小时)
标签:音频、语音、LibriTTS、编解码器、令牌
数据集描述
该数据集是使用kyutai/mimi编解码器(RVQ编解码器,8个码本 × 2048个条目,12.5帧/秒)对LibriTTS-R音频进行编码后生成的令牌序列数据集。每行数据包含两种令牌流:
codes_semantic(list[uint32],12.5 fps,词汇表大小2048):仅使用码本0(基于WavLM蒸馏,内容对齐)。codes_all_flat(list[uint32],100 fps,偏移词汇表16384):将所有8个码本按帧交错排列,码本k映射到[k*2048, (k+1)*2048)范围,便于平面语言模型区分。
数据集划分
数据集镜像自原始LibriTTS-R划分(经parler-tts过滤):
| 划分 | 语句数 | 时长 |
|---|---|---|
train.clean.100 |
约3.2万 | 约53小时 |
train.clean.360 |
约11.2万 | 约218小时 |
train.other.500 |
约25万 | 约258小时 |
dev.clean |
约0.56万 | 约9小时 |
划分之间无说话人重叠(结构上保证训练集与开发集不共享说话人)。
数据模式(每行)
| 列名 | 类型 | 描述 |
|---|---|---|
id |
string | 源语句ID(LibriTTS格式:说话人_章节_片段) |
speaker |
string | LibriTTS说话人ID |
duration |
float32 | 音频时长(秒) |
text |
string | 源数据中的标准化文本 |
codes_semantic |
list[uint32] | Mimi码本0令牌,12.5 fps |
codes_all_flat |
list[uint32] | 所有8个码本交错令牌,100 fps,偏移词汇表 |
加载方式
使用Hugging Face datasets 库加载:
python from datasets import load_dataset
加载整个数据集(所有4个划分)
ds = load_dataset("Trelis/libritts-mimi-tokens")
仅加载某个划分
clean_360 = load_dataset("Trelis/libritts-mimi-tokens", split="train.clean.360")
合并所有训练集划分
all_train = load_dataset("Trelis/libritts-mimi-tokens", split="train.clean.100+train.clean.360+train.other.500")
相关数据集
与以下数据集共享相同的音频内容,但使用不同的令牌化方式:
Trelis/libritts-bpe-tokensTrelis/libritts-snac-tokensTrelis/libritts-neucodec-tokens
复现说明
- 编码器代码:参见 TrelisResearch/audio-bits 中的
scripts/encode_codec.py和scripts/tokenize_text.py。 - 音频预处理:源LibriTTS-R音频为24 kHz。NeuCodec(16 kHz)需使用多相抗混叠重采样降采样;Mimi和SNAC直接使用24 kHz。长度超过20秒的语句截断至20秒音频(文本保留完整)。
- 每行令牌数量:计算公式为
min(ceil(n_audio_samples * T / max_padded_samples), T),其中T是编解码器的每批输出长度,确保与编解码器自身时间网格对齐。
搜集汇总
数据集介绍
构建方式
本数据集基于LibriTTS-R语料库,利用kyutai/mimi RVQ编解码器对原始音频进行编码处理,生成离散化的语音令牌序列。编码过程采用了8个码本、每个码本包含2048个条目的配置,帧率为12.5帧/秒。数据集保留了原始LibriTTS-R的语料划分结构,包含train.clean.100、train.clean.360、train.other.500以及dev.clean四个子集,总计约538小时的语音数据。每个语音片段均提供两种令牌序列:codes_semantic仅包含码本0的内容对齐语义令牌,codes_all_flat则将全部8个码本的令牌交错排列,并对不同码本施加独立的词汇偏移量,以支持扁平化语言模型的训练。
特点
该数据集最显著的特点在于其双通道令牌表示机制,能够同时服务于语义理解和多码本建模两种任务需求。codes_semantic字段提供了经WavLM蒸馏的纯语义令牌,适用于内容分析与识别场景;codes_all_flat字段通过码本偏移策略将8个码本在统一词汇空间中区分开来,为神经编解码语言模型的训练提供了理想的输入格式。数据集在划分上保证了训练集与开发集之间说话人不重叠,有效避免了数据泄漏问题。此外,所有语音片段超过20秒即被截断,确保了序列长度的可控性,便于批处理训练。
使用方法
用户可通过HuggingFace Datasets库便捷加载本数据集,调用load_dataset('Trelis/libritts-mimi-tokens')即可获取全部子集。支持按需选取特定划分,例如load_dataset('Trelis/libritts-mimi-tokens', split='train.clean.360')。对于需要合并训练集的场景,可直接使用split参数组合多个子集。由于codes_semantic和codes_all_flat均为uint32列表类型,研究人员可直接将其作为神经网络模型的输入特征,结合配套的文本标注字段text进行语音合成或表征学习的实验。该数据集亦提供了完整的复现代码,包含音频预处理与令牌编码脚本,便于用户扩展至其他语音数据。
背景与挑战
背景概述
libritts-mimi-tokens数据集由Trelis Research于近期创建,旨在为语音合成与音频编码领域提供高质量、结构化的神经音频令牌表示。该数据集基于LibriTTS-R语料库,采用kyutai/mimi残差向量量化(RVQ)编解码器进行编码,生成8个码本、每个码本包含2,048个条目、帧率为12.5帧/秒的令牌序列。核心研究问题在于如何通过语义对齐的码本0(codes_semantic)与扁平化多码本表示(codes_all_flat)分离内容与声学细节,从而支持基于语言模型的语音生成与下游任务。数据集总时长约538小时,分为clean.100、clean.360、other.500及开发集,其结构化的令牌设计为语音建模研究提供了标准化基准,对推动神经编解码与文本到语音合成的跨学科融合具有重要影响。
当前挑战
该数据集所解决的领域挑战首先在于神经音频编解码的语义与声学特征解耦问题,传统令牌表示常混合内容与音色信息,难以灵活适应语音编辑与零样本合成。libritts-mimi-tokens通过单独提供码本0的语义令牌(12.5帧/秒)与包含偏移词汇的八码本扁平序列(100帧/秒),使得语言模型能够区分不同码本的角色。其次,构建过程中面临两大挑战:一是原始LibriTTS-R音频采样率不一(部分为24 kHz,NeuCodec需重采样至16 kHz),需采用sinc_interp_kaiser抗混叠方法保持信号保真度;二是超长话语截断策略的设计,即限定音频时长不超过20秒以适配编解码器的批量处理网格,并确保令牌计数精确对应模型时间步,这对保持数据一致性与后续模型训练稳定性提出了严格要求。
常用场景
经典使用场景
LibriTTS-Mimi-Tokens数据集是语音领域一项极具价值的资源,它将经典的LibriTTS-R语料库与kyutai/Mimi残差矢量量化编解码器巧妙结合,为语音离散表征研究提供了标准化的数据基础。该数据集最核心的使用场景在于训练和评估基于神经编解码的语音生成模型,尤其是那些采用离散token序列进行语音建模的架构。凭借其提供的语义token(codes_semantic)和全扁平化token(codes_all_flat)两种流,研究人员能够灵活地探索从内容对齐表示到细粒度声学重建的多层次语音信息提取。无论是面向文本到语音合成的语言模型预训练,还是语音编解码领域的表征学习实验,该数据集均提供了高质量、大规模且结构统一的基准数据,显著降低研究者预处理数据的门槛。
衍生相关工作
该数据集催生了一系列富有影响力的衍生研究工作。在语音编解码领域,基于Mimi的离散token结构,研究人员得以深入探讨多码本残差矢量量化的信息分配机制,从而改进编解码器的层级设计与量化策略。在语音合成方面,该数据集为基于语言模型的TTS系统提供了标准化输入格式,促进了如VALL-E、AudioLM等开创性工作的复现与扩展,研究者通过调整语义与声学token的比例关系,探索更高效的条件生成框架。此外,该数据集还推动了跨模态对比研究的兴起,与配套的BPE、SNAC及NeuCodec token数据集共同构成了完整的离散表征实验平台,使学者能够系统评估不同编解码器对语音重建质量和下游任务性能的差异化影响。
数据集最近研究
最新研究方向
libritts-mimi-tokens数据集聚焦于基于残差向量量化(RVQ)编解码器的语音表示学习,当前前沿方向是利用其双层令牌结构——语义令牌(12.5fps)与扁平化交插令牌(100fps)——推动神经语音编解码与语言模型的深度融合。该数据集通过Kyutai Mimi模型将LibriTTS-R语料库转化为离散令牌序列,直接服务于语音生成领域的热点:零样本语音克隆、低比特率语音压缩及多说话人文本到语音合成。与BPE、SNAC等共轭令牌数据集配合,该资源支持对比研究不同编码空间对语音自然度与内容保真度的影响,为构建统一语音-文本理解与生成的多模态大模型提供了关键中间表示层,其结构设计契合语音语言模型(如VALL-E、SoundStorm)的序列建模范式,有望突破语音任务数据碎片化瓶颈。
以上内容由遇见数据集搜集并总结生成


