timeomni-1-testbed
收藏Hugging Face2026-02-13 更新2026-02-14 收录
下载链接:
https://huggingface.co/datasets/anton-hugging/timeomni-1-testbed
下载链接
链接失效反馈官方服务:
资源简介:
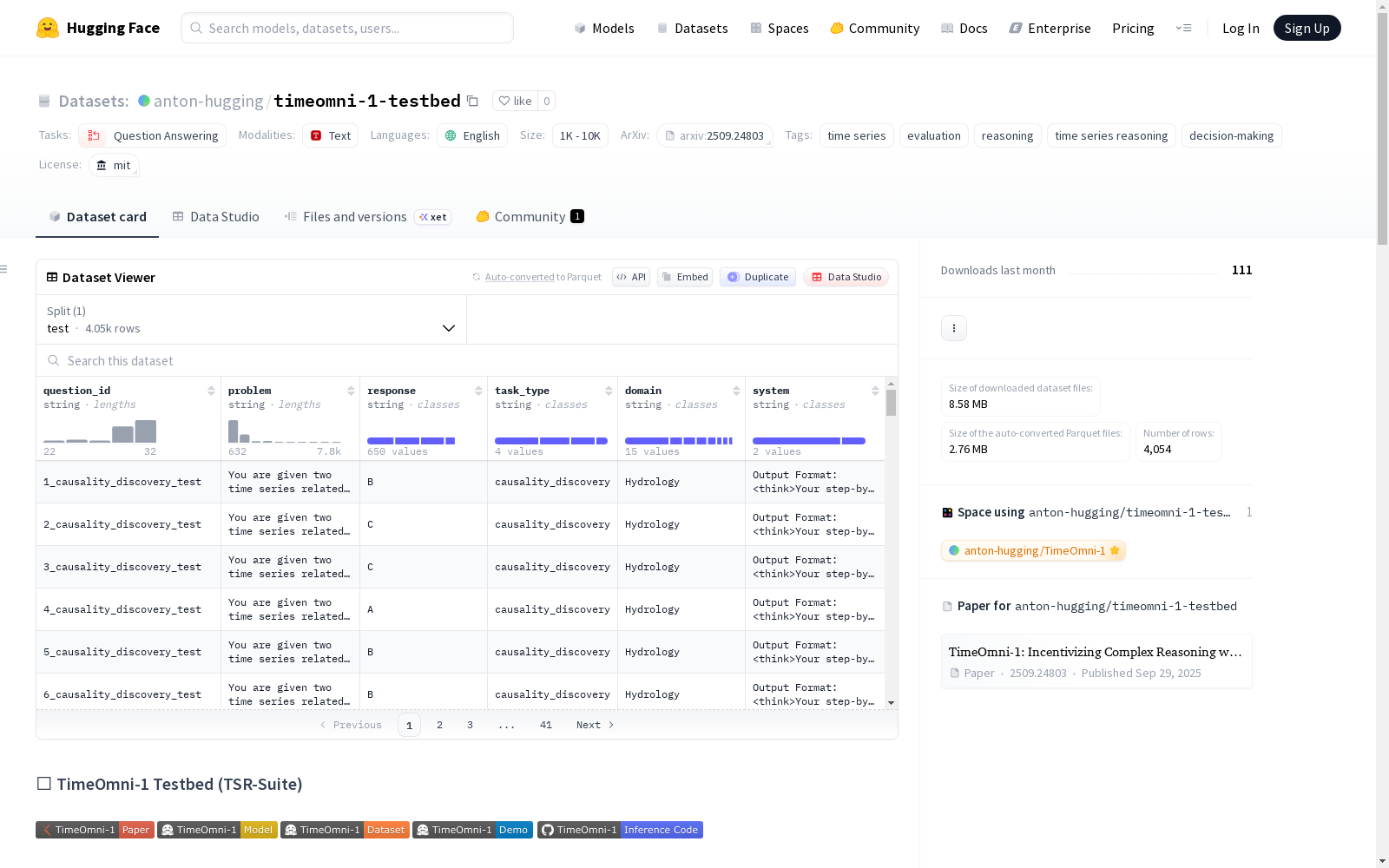
TimeOmni-1 Testbed (TSR-Suite) 是一个专注于时间序列推理的数据集,旨在评估模型在感知、外推和决策制定等核心能力上的表现。数据集包含四种任务类型:场景理解、因果关系发现、事件感知预测和决策制定。数据分为分布内测试集(id_test,1,606个样本)和分布外测试集(ood_test,2,448个样本),总计4,054个样本。每个样本包含以下字段:question_id(唯一标识符,格式为{number}_{task_type}_test)、problem(问题陈述,包含时间序列和辅助上下文)、response(真实答案,通常为单个大写字母或预测序列)、task_type(任务类型)、domain(时间序列的来源领域,如水文、能源电池套利)和system(模型输出格式的系统提示)。数据集适用于问答任务,主要用于时间序列推理和决策制定的评估。
创建时间:
2026-02-08
原始信息汇总
TimeOmni-1 Testbed (TSR-Suite) 数据集概述
数据集基本信息
- 许可证: MIT
- 任务类别: 问答
- 标签: 时间序列、评估、推理、时间序列推理、决策制定
- 语言: 英语
- 数据规模: 1K<n<10K
核心能力与任务类型
该数据集旨在评估时间序列推理的三个核心能力,涵盖以下四种任务类型:
- 感知能力
- 任务1:场景理解:识别生成给定时间序列的场景。
- 任务2:因果发现:发现时间序列之间的因果关系。
- 外推能力
- 任务3:事件感知预测:在考虑外部事件的情况下进行预测。
- 决策制定能力
- 任务4:决策制定:做出最大化下游效用(例如利润)的最优行动。
数据集信息
1. 数据集划分
- id_test: 分布内测试集(1,606个样本)
- ood_test: 分布外测试集(2,448个样本)
2. 数据集统计
| 任务类型 | ID 测试集 | OOD 测试集 | 总计 |
|---|---|---|---|
| 场景理解 | 200 | 899 | 1,099 |
| 因果发现 | 800 | 800 | 1,600 |
| 事件感知预测 | 418 | 476 | 894 |
| 决策制定 | 188 | 273 | 461 |
| 总计 | 1,606 | 2,448 | 4,054 |
3. 数据字段
question_id: 唯一标识符,格式为{数字}_{任务类型}_testproblem: 问题陈述,包含时间序列(及任何辅助上下文)和问题。response: 真实答案(通常为单个大写字母或预测序列)task_type: 上述四种任务类型之一domain: 时间序列的源领域(例如,水文学、能源电池套利)system: 模型输出格式的系统提示
使用方法
python from datasets import load_dataset
dataset = load_dataset("anton-hugging/timeomni-1-testbed") id_test = dataset["id_test"] ood_test = dataset["ood_test"]
评估方法
报告成功率(SR),即模型输出产生有效且可提取答案的比例。所有后续评估指标仅在这些有效案例上计算,以确保性能反映时间序列推理能力而非指令遵循合规性。
- 对于任务1、2和4:模型输出单个大写字母(A、B、C或D)。准确率(ACC)为正确预测的百分比。
- 对于任务3:模型输出预测序列(例如,[2, 20, 21, ..., 83])。准确率通过平均绝对误差(MAE)衡量。
引用
bibtex @inproceedings{ guan2026timeomni, title={TimeOmni-1: Incentivizing Complex Reasoning with Time Series in Large Language Models}, author={Tong Guan and Zijie Meng and Dianqi Li and Shiyu Wang and Chao-Han Huck Yang and Qingsong Wen and Zuozhu Liu and Sabato Marco Siniscalchi and Ming Jin and Shirui Pan}, booktitle={The Fourteenth International Conference on Learning Representations}, year={2026}, url={https://openreview.net/forum?id=kOIclg7muL} }
搜集汇总
数据集介绍
构建方式
在时间序列分析领域,构建一个能够全面评估模型推理能力的数据集至关重要。TimeOmni-1 Testbed(TSR-Suite)的构建过程精心设计了四种任务类型,以覆盖时间序列推理的三个核心能力:感知、外推和决策。数据集通过模拟真实世界场景生成,涵盖水文、能源电池套利等多个领域,并严格划分为分布内测试集(1,606个样本)和分布外测试集(2,448个样本),总计4,054个样本。每个样本均包含唯一的问题标识、问题陈述、真实答案、任务类型及领域信息,确保了数据的多样性和评估的严谨性。
特点
该数据集的特点在于其多维度的任务设计,能够系统性地检验模型在时间序列上的综合推理能力。它不仅包含了场景理解和因果关系发现等感知任务,还融入了事件感知预测和决策制定等高级推理环节。数据集的样本规模适中,介于1K到10K之间,且提供了清晰的领域标注和任务分类,便于研究者进行针对性分析。此外,数据集严格区分了分布内与分布外测试,有助于评估模型的泛化性能和鲁棒性,为时间序列推理研究提供了一个标准化的评估平台。
使用方法
使用TimeOmni-1 Testbed时,研究者可通过Hugging Face的datasets库便捷加载数据,具体分为id_test和ood_test两个子集。评估过程强调成功率的计算,仅对有效输出进行准确性度量,以确保结果真实反映模型的时间序列推理能力而非指令遵循程度。对于分类任务,采用准确率作为指标;对于序列预测任务,则使用平均绝对误差进行评估。这种使用方法既简化了数据接入流程,又保证了评估的科学性和一致性,助力于推动时间序列推理模型的快速发展。
背景与挑战
背景概述
在时间序列分析与人工智能交叉领域,传统模型往往局限于单一预测任务,缺乏对复杂时序场景的深度理解与推理能力。TimeOmni-1 Testbed(TSR-Suite)由相关研究团队于2026年提出,旨在构建一个综合性评估基准,以推动大型语言模型在时间序列复杂推理方面的发展。该数据集聚焦于三大核心能力——感知、外推与决策制定,涵盖了场景理解、因果发现、事件感知预测及决策制定四类任务,其设计初衷在于激励模型超越表面模式识别,实现深层次的时序逻辑推断与情境化决策,从而为金融、能源、水文等多领域应用提供更为可靠的智能分析工具。
当前挑战
TimeOmni-1 Testbed所针对的领域挑战在于时间序列复杂推理的综合性评估,传统时间序列分析常孤立处理预测或分类问题,难以整合感知、因果推断与决策制定等多层次认知任务。构建过程中的挑战则体现在数据合成与标注的复杂性上,需确保生成的时间序列既符合真实世界动力学规律,又能嵌入可解释的因果结构与事件上下文,同时维持任务间难度平衡与分布内外样本的多样性,以有效检验模型的泛化与推理鲁棒性。
常用场景
经典使用场景
在时间序列分析领域,TimeOmni-1 Testbed作为一个综合性评估套件,其经典使用场景集中于对大型语言模型在复杂时序推理能力上的系统性评测。该数据集通过涵盖感知、外推与决策制定三大核心能力的四项任务类型,为研究者提供了一个标准化的基准平台,用以检验模型在场景理解、因果发现、事件感知预测及优化决策等多维度任务上的表现。这种结构化的评估框架,使得学术界能够深入探究模型在处理真实世界时序数据时的泛化性与鲁棒性,尤其在面对分布外样本时,其评测结果更具参考价值。
实际应用
在实际应用层面,TimeOmni-1 Testbed所评测的能力直接关联于多个关键行业场景。例如,在水文或能源电池套利等领域,模型对时序场景的精准理解与因果发现能力,可辅助进行系统状态诊断与根因分析;其事件感知预测功能,能够提升在突发事件影响下的需求或价格走势预测准确性;而基于时序的决策制定能力,则可用于优化实时调度策略以最大化经济效益。该数据集为将先进的语言模型推理能力落地到金融、物联网、供应链管理等依赖时序决策的实际业务中,提供了可靠的能力验证桥梁与改进方向指引。
衍生相关工作
围绕TimeOmni-1 Testbed,已衍生出一系列相关的经典研究工作。其核心论文《TimeOmni-1: Incentivizing Complex Reasoning with Time Series in Large Language Models》本身便确立了该基准的学术地位。以此为基础,后续研究一方面致力于开发如TimeOmni-1-7B等专为时序推理优化的模型,探索如何将领域知识更有效地注入大型语言模型;另一方面,研究工作也聚焦于利用该测试床的评估结果,深入分析模型在不同任务类型和领域上的能力边界与失败模式,从而启发新的模型架构设计、训练策略改进以及更具挑战性的时序推理任务构建,持续推动该子领域的前沿探索。
以上内容由遇见数据集搜集并总结生成


