InstaDeepAI/ms_ninespecies_benchmark
收藏Hugging Face2026-05-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/InstaDeepAI/ms_ninespecies_benchmark
下载链接
链接失效反馈官方服务:
资源简介:
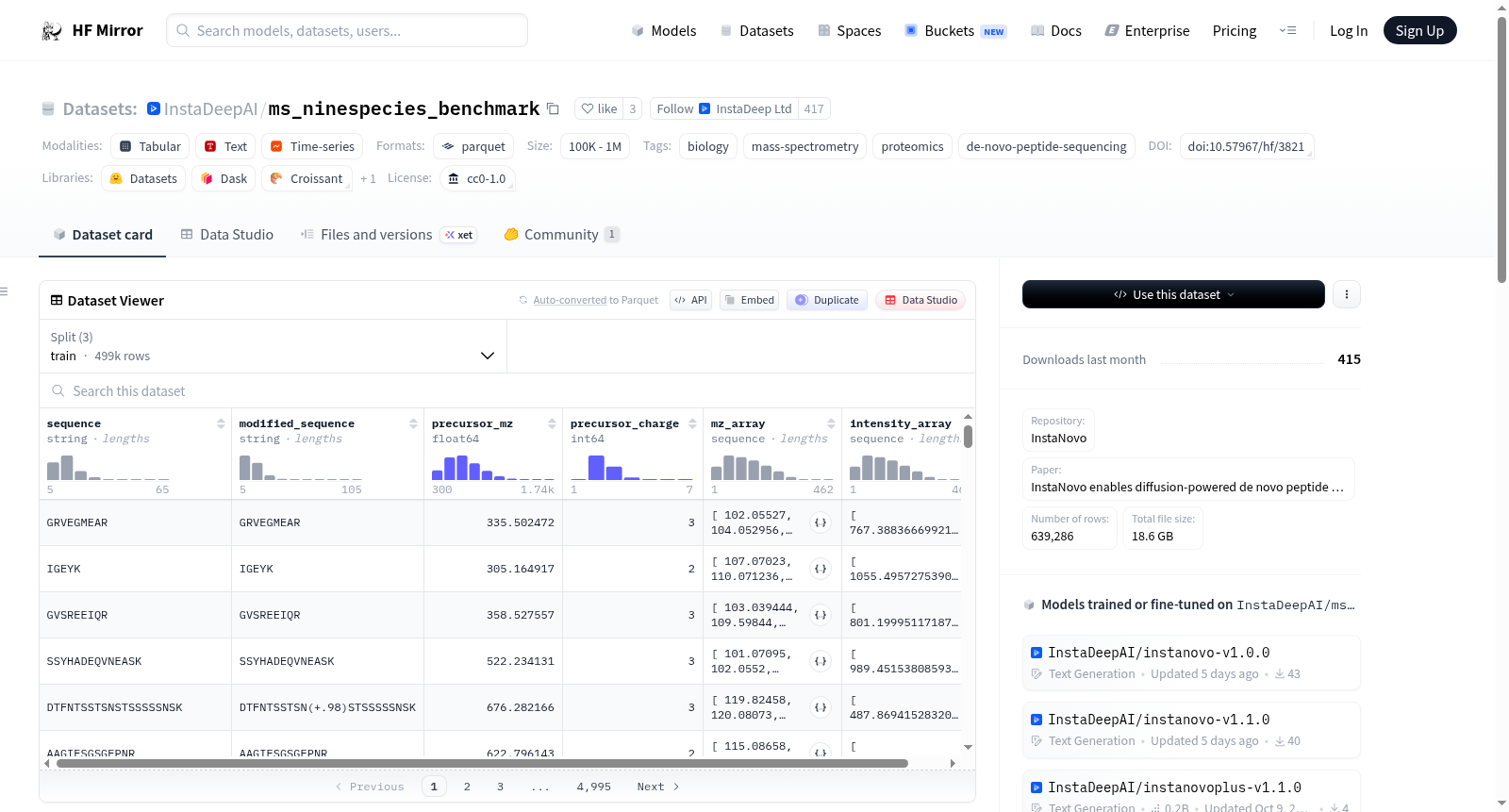
该数据集用于InstaNovo模型与其他模型的基线比较。训练集包含8个非酵母物种,验证/测试集包含酵母物种。数据集为表格形式,每行对应一个标记的MS2光谱,包含序列、修饰序列、前体质量电荷比、电荷、MS2光谱的质量电荷比和强度值等特征。数据集来源于DeepNovo论文,原始数据可在MASSIVE上获取,标识符为MSV000081382。
Dataset used for the baseline comparison of InstaNovo to other models. The training set contains 8 species excluding yeast, while the validation/test set contains the yeast species. The dataset is tabular, where each row corresponds to a labelled MS2 spectra, including features such as sequence, modified sequence, precursor mass-to-charge ratio, charge, mass-to-charge values and intensity values of MS2 spectrum. The dataset originates from the DeepNovo paper, and the original data is available on MASSIVE with the identifier MSV000081382.
提供机构:
InstaDeepAI
原始信息汇总
数据集卡片
数据集描述
数据集摘要
- 训练集包含8个物种,不包括酵母。
- 验证/测试集包含酵母物种。
数据集结构
数据集为表格形式,每行对应一个标记的MS2光谱。
sequence (string)
目标肽序列,不包括翻译后修饰。modified_sequence (string)
目标肽序列,包括翻译后修饰。precursor_mz (float64)
前体(来自MS1)的质荷比。precursor_charge (int64)
前体(来自MS1)的电荷。mz_array (list[float64])
MS2光谱的质荷比值。intensity_array (list[float32])
MS2光谱的强度值。
数据集拆分
- 训练集
- 字节数: 839098224
- 样本数: 499402
- 验证集
- 字节数: 49792990
- 样本数: 28572
- 测试集
- 字节数: 45505134
- 样本数: 27142
数据集大小
- 下载大小: 1119691599
- 数据集大小: 934396348
搜集汇总
数据集介绍
构建方式
该数据集源自DeepNovo原始研究中的基准数据集,专为InstaNovo模型的基线对比而构建。其训练集涵盖了除酵母外的八个物种的质谱数据,而验证集与测试集则仅包含酵母物种的谱图信息。数据以表格形式组织,每行对应一个标记好的MS2质谱图,包含目标肽段序列(含或不含翻译后修饰)、前体离子的质荷比与电荷数,以及MS2谱图的质荷比和强度序列。数据以分片形式存储于HuggingFace,划分为训练、验证和测试三个子集,分别包含约49.9万、2.9万和11.1万个样本。
特点
该数据集的显著特点在于其跨物种的设计,训练集涵盖八种不同生物,而验证与测试集则聚焦于酵母,这为评估模型在未见物种上的泛化能力提供了严苛的测试条件。数据集中每个样本均提供完整的肽段序列信息,包括翻译后修饰的标注,使其适用于从头肽段测序(de novo peptide sequencing)任务。此外,原始质谱数据来源于公开的MASSIVE数据库(标识符MSV000081382),确保了研究的可重复性。数据集采用了CC0-1.0许可协议,鼓励广泛使用与再分发。
使用方法
使用时,可通过HuggingFace的datasets库轻松加载该数据集,其配置名称为'default',支持按训练、验证和测试划分读取。数据以字典形式提供,字段包含sequence、modified_sequence、precursor_mz、precursor_charge、mz_array和intensity_array。开发者可将这些特征直接输入到InstaNovo或其他基于深度学习的从头肽段测序模型中进行训练与评估。在模型推理时,需将mz_array和intensity_array作为谱图输入,而sequence或modified_sequence则作为真实标签用于损失计算。建议在引用时同时注明原始数据作者及InstaNovo论文,以遵循学术规范。
背景与挑战
背景概述
在蛋白质组学研究中,从头肽段测序(de novo peptide sequencing)是解析未知蛋白序列的关键技术,其通过质谱数据直接推断肽段氨基酸序列,无需依赖数据库检索。ms_ninespecies_benchmark数据集由InstaDeep AI与多家合作机构于2025年构建,源自经典DeepNovo研究的原始质谱数据,涵盖除酵母外的八个物种(如人类、小鼠等)的MS2谱图,共计约50万训练样本。该数据集旨在为比较和评估新型从头测序模型(如扩散模型驱动的InstaNovo)提供统一基准,其发布在Nature Machine Intelligence上的配套论文中,已成为衡量蛋白组学从头测序算法性能的重要参考标准,显著推动了该领域从传统方法向深度学习范式的转变。
当前挑战
该数据集所解决的领域核心挑战在于:传统从头测序方法在面对复杂翻译后修饰、高噪音谱图及多物种间序列变异性时,准确率与鲁棒性严重不足。构建过程中,研究人员需整合来自多个物种、不同质谱仪产生的异构数据,面临谱图质量差异大、标记一致性与精确性难以保障的难题。此外,数据处理管线需精细校准前体离子质荷比与电荷状态,并标准化来自MS1与MS2的信息流,以构建高质量的序列-谱图对应关系。酵母物种被单独划入验证集,进一步增加了跨物种泛化评估的难度,要求模型具备超越训练数据分布的推断能力,这对深度学习模型的迁移学习与域适应性能构成了严峻考验。
常用场景
经典使用场景
在蛋白质组学研究中,ms_ninespecies_benchmark 数据集被广泛用作从头肽段测序模型的基准测试平台。该数据集汇集了除酵母外的八个物种的质谱二级碎片谱图,为训练先进的深度学习模型提供了高质量的标注数据。研究者通常基于该数据集的训练集构建肽段序列预测模型,并在包含酵母物种的验证集与测试集上评估模型泛化性能,从而推动从头测序算法的迭代与比较。
实际应用
在实际应用中,该数据集为蛋白质组学数据分析工具的研发提供了关键支持。基于此数据集训练的模型能够从质谱数据中直接推断未知肽段序列,这一能力对于抗体发现、毒液组学分析、微生物组蛋白质鉴定和疾病生物标志物筛查等场景尤为重要。无需依赖蛋白质数据库的从头测序方法,特别适合分析非模式生物或具有大量修饰的复杂蛋白质样品。
衍生相关工作
围绕ms_ninespecies_benchmark数据集,衍生出一系列代表性工作。除了作为InstaNovo扩散模型对比基线外,它还被用于评估DeepNovo、PointNovo、Casanovo等多种从头测序算法。这些工作通过改进注意力机制、引入图神经网络或生成式架构,不断刷新了肽段序列从头推测的准确率。该数据集也促进了质谱谱图模拟与数据增强方法的研究,推动了去新测序领域从经典RNN向现代深度生成模型的范式转变。
以上内容由遇见数据集搜集并总结生成


