TIGER-Lab/Mantis-Eval
收藏Hugging Face2024-11-15 更新2024-06-22 收录
下载链接:
https://hf-mirror.com/datasets/TIGER-Lab/Mantis-Eval
下载链接
链接失效反馈资源简介:
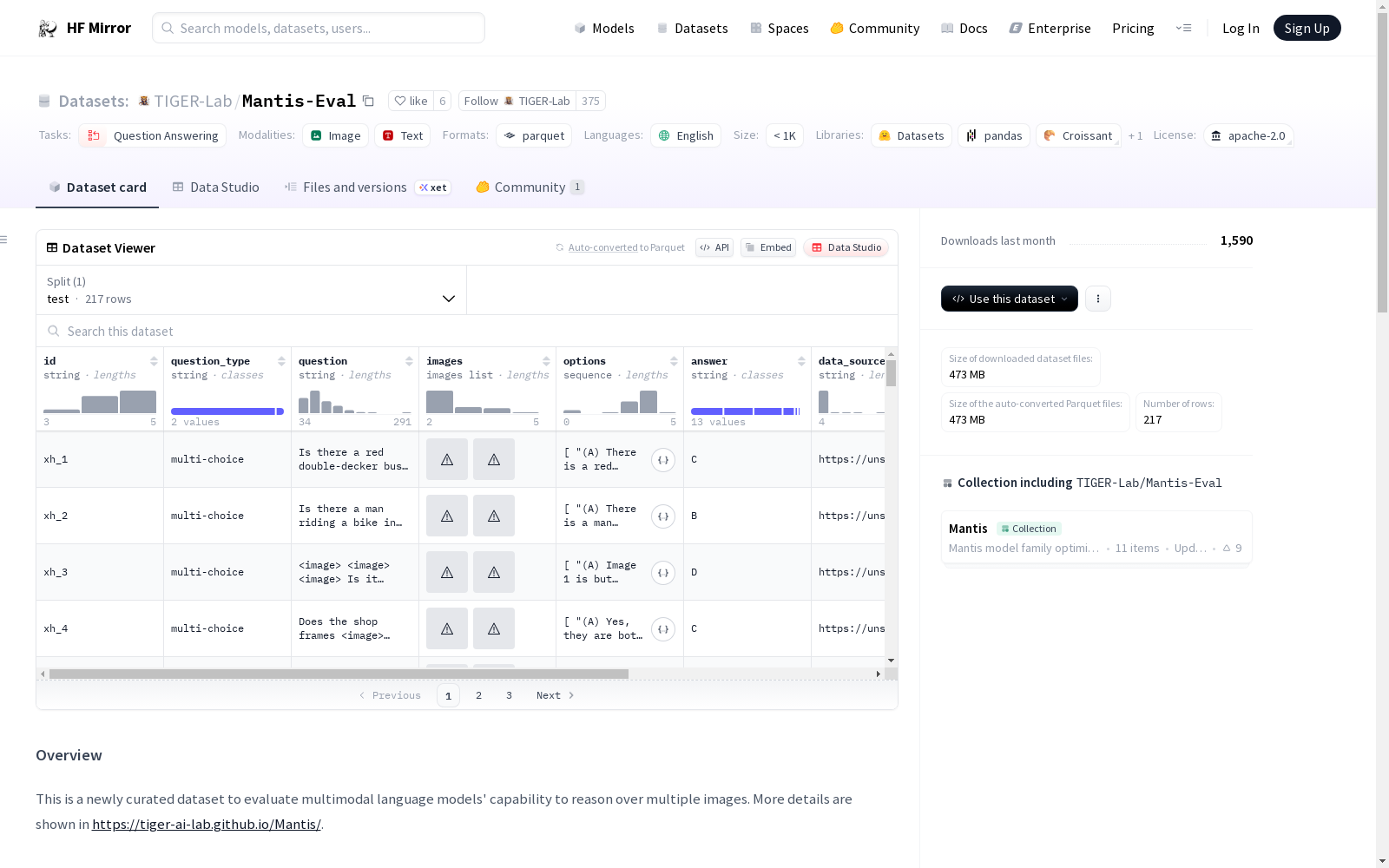
Mantis-Eval是一个新策划的数据集,用于评估多模态语言模型在多图像推理上的能力。该数据集包含200多个由人类注释的挑战性多图像推理问题。数据集的特征包括id、问题类型、问题、图像、选项、答案、数据来源和类别。数据集的分割信息显示,测试集包含217个示例,总字节数为479770102。
Mantis-Eval is a newly curated dataset to evaluate multimodal language models capability to reason over multiple images. This evaluation dataset contains more than 200 human-annotated challenging multi-image reasoning problems. The features of the dataset include id, question type, question, images, options, answer, data source, and category. The split information shows that the test set contains 217 examples with a total of 479770102 bytes.
提供机构:
TIGER-Lab
原始信息汇总
数据集概述
基本信息
- 语言: 英语
- 许可证: Apache 2.0
- 大小分类: n<1K
- 任务分类: 问答
- 美观名称: Mantis-Eval
数据集配置
- 配置名称: mantis_eval
- 特征:
- id: 字符串
- question_type: 字符串
- question: 字符串
- images: 图像序列
- options: 字符串序列
- answer: 字符串
- data_source: 字符串
- category: 字符串
- 分割:
- test:
- 字节数: 479770102
- 示例数: 217
- test:
- 下载大小: 473031413
- 数据集大小: 479770102
数据文件
- 配置名称: mantis_eval
- 数据文件:
- 分割: test
- 路径: mantis_eval/test-*
统计信息
- 包含超过200个人工标注的复杂多图像推理问题。
排行榜
| 模型 | 大小 | Mantis-Eval |
|---|---|---|
| GPT-4V | - | 62.67 |
| Mantis-SigLIP | 8B | 59.45 |
| Mantis-Idefics2 | 8B | 57.14 |
| Mantis-CLIP | 8B | 55.76 |
| VILA | 8B | 51.15 |
| BLIP-2 | 13B | 49.77 |
| Idefics2 | 8B | 48.85 |
| InstructBLIP | 13B | 45.62 |
| LLaVA-V1.6 | 7B | 45.62 |
| CogVLM | 17B | 45.16 |
| Qwen-VL-Chat | 7B | 39.17 |
| Emu2-Chat | 37B | 37.79 |
| VideoLLaVA | 7B | 35.04 |
| Mantis-Flamingo | 9B | 32.72 |
| LLaVA-v1.5 | 7B | 31.34 |
| Kosmos2 | 1.6B | 30.41 |
| Idefics1 | 9B | 28.11 |
| Fuyu | 8B | 27.19 |
| OpenFlamingo | 9B | 12.44 |
| Otter-Image | 9B | 14.29 |
引用
如果使用此数据集,请引用以下工作:
@inproceedings{Jiang2024MANTISIM, title={MANTIS: Interleaved Multi-Image Instruction Tuning}, author={Dongfu Jiang and Xuan He and Huaye Zeng and Cong Wei and Max W.F. Ku and Qian Liu and Wenhu Chen}, publisher={arXiv2405.01483} year={2024}, }
AI搜集汇总
数据集介绍
构建方式
Mantis-Eval数据集的构建,旨在评估多模态语言模型在处理多图像推理问题上的能力。该数据集由217个人工标注的具有挑战性的多图像推理问题组成,每个问题包含问题类型、问题文本、相关图像序列、选项以及正确答案等信息,为模型的评估提供了全面而细致的依据。
特点
Mantis-Eval数据集的特点在于其专注于多图像推理任务,要求模型能够理解并整合多个图像的信息来进行有效的推理。数据集规模虽小,但每个样本都是经过人工精心标注,确保了问题的质量和难度,非常适合作为评估多模态语言模型性能的基准。
使用方法
使用Mantis-Eval数据集时,研究者可以按照数据集提供的测试分割进行模型性能的评估。数据集以Apache-2.0许可证开源,可以通过下载相应配置的文件进行使用。用户需根据数据集的结构,正确解析id、问题类型、问题文本、图像序列、选项和答案等字段,以实现对模型的准确评估。
背景与挑战
背景概述
Mantis-Eval数据集,由TIGER-Lab团队精心策划,旨在评估多模态语言模型在多图像推理任务上的能力。该数据集的创建,标志着对于多模态理解领域的一个重要贡献,其研究背景可追溯至2024年,由Dongfu Jiang等研究人员共同完成。该数据集的核心研究问题是提升模型在处理多图像情景下的推理能力,它不仅提供了217个经过人工标注的挑战性问题,而且通过其 leaderboard展示了不同模型在该任务上的表现,对相关领域的研究产生了显著影响。
当前挑战
Mantis-Eval数据集所面临的挑战主要涉及两个方面:一是如何准确捕捉并处理图像间的复杂关系,这要求模型具备高度的多模态理解能力;二是构建过程中,如何确保问题集的多样性和难度,以及如何有效标注数据,确保数据质量。此外,多图像推理任务的评估标准制定也是一个挑战,需要确保评价体系的公正性和准确性。
常用场景
经典使用场景
在探索多模态语言模型处理多图像推理任务的能力时,Mantis-Eval数据集提供了217个人类注释的复杂问题案例。该数据集的经典使用场景在于评估模型在理解图像序列并据此做出推理决策方面的表现,尤其关注模型如何处理涉及多步骤逻辑推理的复杂问题。
衍生相关工作
Mantis-Eval数据集的发布促进了相关领域的研究工作,如MANTIS: Interleaved Multi-Image Instruction Tuning等。这些工作基于该数据集进一步探索了如何通过指令调整来增强模型在处理多图像推理任务时的性能,推动了多模态学习和理解的发展。
数据集最近研究
最新研究方向
Mantis-Eval数据集的问世,旨在评估多模态语言模型在处理多图像推理任务上的能力。该数据集的构建,紧跟当前人工智能领域对多模态交互理解的深入探索,特别是在多图像情境下的逻辑推理与决策制定。近期研究集中于提升模型在复杂图像序列中的信息抽取、融合及推理能力,以期达到对图像内容更深入的理解和更精准的响应。此数据集的推出,不仅为多模态语言模型的性能评估提供了新的标准,也为相关领域的研究人员提供了一个全新的研究方向,对推动多模态人工智能技术的发展具有重要的意义。
以上内容由AI搜集并总结生成


