action100m_tiny_subset
收藏Hugging Face2026-02-12 更新2026-02-13 收录
下载链接:
https://huggingface.co/datasets/harpreetsahota/action100m_tiny_subset
下载链接
链接失效反馈官方服务:
资源简介:
action100m 是一个包含 1144 个样本的 FiftyOne 视频数据集,数据规模介于 1K 到 10K 之间。数据集使用英语作为主要语言,但缺乏关于具体内容、采集方式、标注信息、适用任务等详细说明。用户需要通过 FiftyOne 工具加载和使用该数据集。
创建时间:
2026-02-12
原始信息汇总
数据集概述:action100m
基本信息
- 数据集名称:action100m
- 数据集标识:harpreetsahota/action100m_tiny_subset
- 样本数量:1144
- 语言:英文 (en)
- 数据规模:1K < n < 10K
- 标签:fiftyone, video
数据集描述
这是一个基于 FiftyOne 平台的数据集,包含1144个样本。
安装与使用
安装依赖
需预先安装 FiftyOne: bash pip install -U fiftyone
加载数据集
通过 FiftyOne 提供的工具从 Hub 加载: python import fiftyone as fo from fiftyone.utils.huggingface import load_from_hub
dataset = load_from_hub("harpreetsahota/action100m_tiny_subset") session = fo.launch_app(dataset)
注:加载时可使用 max_samples 等参数。
数据集详情
数据集描述
- 策划方:[信息缺失]
- 资助方:[信息缺失]
- 共享方:[信息缺失]
- 语言:英文 (en)
- 许可证:[信息缺失]
数据来源
- 代码库:[信息缺失]
- 论文:[信息缺失]
- 演示:[信息缺失]
使用范围
直接用途
[信息缺失]
超范围用途
[信息缺失]
数据结构
[信息缺失]
数据创建
创建缘由
[信息缺失]
源数据
数据收集与处理
[信息缺失]
数据生产者
[信息缺失]
标注信息
标注流程
[信息缺失]
标注者
[信息缺失]
个人与敏感信息
[信息缺失]
偏见、风险与限制
[信息缺失]
建议
用户应了解该数据集的风险、偏见和局限性。需更多信息以提供进一步建议。
引用
BibTeX: [信息缺失]
APA: [信息缺失]
术语表
[信息缺失]
更多信息
[信息缺失]
数据集卡片作者
[信息缺失]
数据集卡片联系人
[信息缺失]
搜集汇总
数据集介绍
构建方式
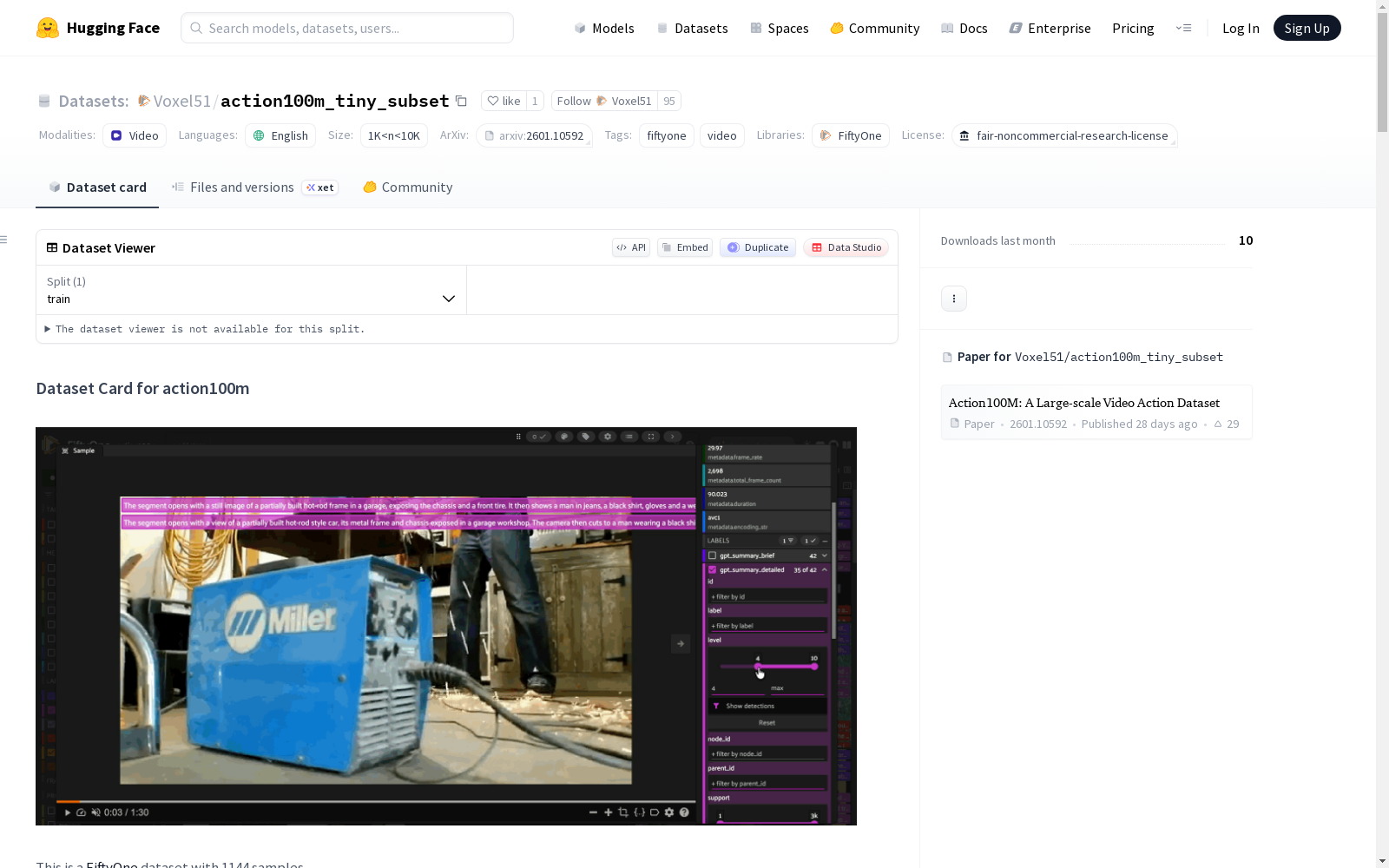
在计算机视觉领域,视频数据集对于动作识别等任务至关重要。action100m_tiny_subset作为FiftyOne平台上的一个精选子集,其构建方式体现了高效的数据管理理念。该数据集从原始action100m数据集中抽取了1144个样本,通过FiftyOne工具进行结构化整理,确保了数据的可访问性和一致性。这种构建方法不仅优化了存储和加载效率,还为研究人员提供了即用型的视频分析资源,支持快速实验和模型验证。
使用方法
使用该数据集时,用户需首先安装FiftyOne库,通过简单的Python代码即可从HuggingFace中心加载数据。导入后,可以利用FiftyOne的应用程序接口启动交互式界面,实时浏览样本内容并执行初步分析。数据集支持自定义参数,如最大样本数调整,以适应不同的实验需求。这种集成化的使用方法不仅简化了数据预处理流程,还促进了可视化探索与模型开发的紧密结合,为视频理解研究提供了便捷的工具链。
背景与挑战
背景概述
视频理解作为计算机视觉领域的重要分支,致力于从动态视觉数据中解析人类行为与场景交互。action100m_tiny_subset作为该领域的一个子集,源自FiftyOne平台,由harpreetsahota等研究人员构建,旨在为行为识别模型提供轻量化的训练与评估资源。尽管其具体创建时间与核心研究团队信息在现有文档中尚未明确,但该数据集通过精选1144个样本,聚焦于解决大规模视频数据中行为分类的复杂性问题,为模型效率优化与泛化能力提升提供了实验基础,对推动实时视频分析技术的发展具有潜在影响力。
当前挑战
在视频行为识别领域,模型需应对动态场景中动作的时空变化、遮挡干扰以及多视角差异等固有挑战,而action100m_tiny_subset作为子集,其规模有限可能难以充分覆盖真实世界行为的多样性,导致模型泛化能力受限。构建过程中,数据采集面临视频质量参差不齐、标注一致性难以保证以及隐私信息处理等难题,同时数据集的元信息缺失,如创建动机、标注流程与许可协议不明,进一步增加了其可靠性与可复现性的评估难度。
常用场景
经典使用场景
在计算机视觉领域,视频动作识别是理解动态场景的核心任务之一。action100m_tiny_subset数据集作为动作识别研究的一个精简子集,常被用于模型原型验证与快速迭代。研究者利用该数据集中的1144个样本,通过FiftyOne平台加载和可视化,能够高效评估算法在有限数据下的泛化能力,为大规模视频分析提供初步基准。
解决学术问题
该数据集主要应对视频动作识别中数据稀缺与计算资源受限的学术挑战。通过提供结构化的视频样本,它支持研究者探索小样本学习、迁移学习以及轻量级模型设计等方向,从而缓解大规模视频数据集带来的存储与处理压力。其意义在于为动作识别领域的算法创新提供了可访问的实验基础,推动了高效模型的发展。
实际应用
在实际应用中,action100m_tiny_subset数据集可用于智能监控、人机交互和内容推荐等场景。例如,在安防领域,基于该数据集训练的模型能够识别视频中的异常行为;在娱乐产业,它可辅助自动生成视频标签以优化内容分发。这些应用体现了数据集在现实世界中的实用价值,促进了视频分析技术的落地。
数据集最近研究
最新研究方向
在视频理解领域,基于FiftyOne框架构建的数据集如action100m_tiny_subset正推动着高效数据管理与可视化分析的前沿探索。当前研究聚焦于利用此类轻量化子集优化动作识别模型的训练流程,通过集成先进的多模态学习技术,提升模型在复杂场景下的泛化能力。热点事件包括结合自监督学习与弱监督标注方法,以降低对大规模标注数据的依赖,同时促进跨领域动作迁移学习的发展。这些进展不仅加速了智能监控、人机交互等应用的落地,也为视频内容分析提供了更灵活、可扩展的解决方案,具有重要的实践意义。
以上内容由遇见数据集搜集并总结生成


