Multi-Text CIR (MTCIR)
收藏arXiv2025-03-26 更新2025-03-28 收录
下载链接:
https://collm-cvpr25.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
MTCIR是一个大规模的合成数据集,包含340万图像对和1770万修改文本。该数据集由亚马逊公司收集,旨在解决组合图像检索领域数据不足的问题,通过多模态大型语言模型生成图像对的修改文本,并提供了多个简短的修改文本,以覆盖各种属性,更好地反映人类查询构建方式,为CIR模型提供更真实、全面的训练基础。
MTCIR is a large-scale synthetic dataset consisting of 3.4 million image pairs and 17.7 million modified text captions. Collected by Amazon, this dataset was developed to address the shortage of training data in the field of compositional image retrieval (CIR). Modified text captions for the image pairs are generated via multimodal large language models, and multiple short modified captions are provided to cover diverse attributes, which better reflects how humans formulate their queries, thereby providing a more realistic and comprehensive training foundation for CIR models.
提供机构:
马里兰大学帕克分校, 亚马逊, 中心计算机视觉研究, University of Central Florida
创建时间:
2025-03-26
搜集汇总
数据集介绍
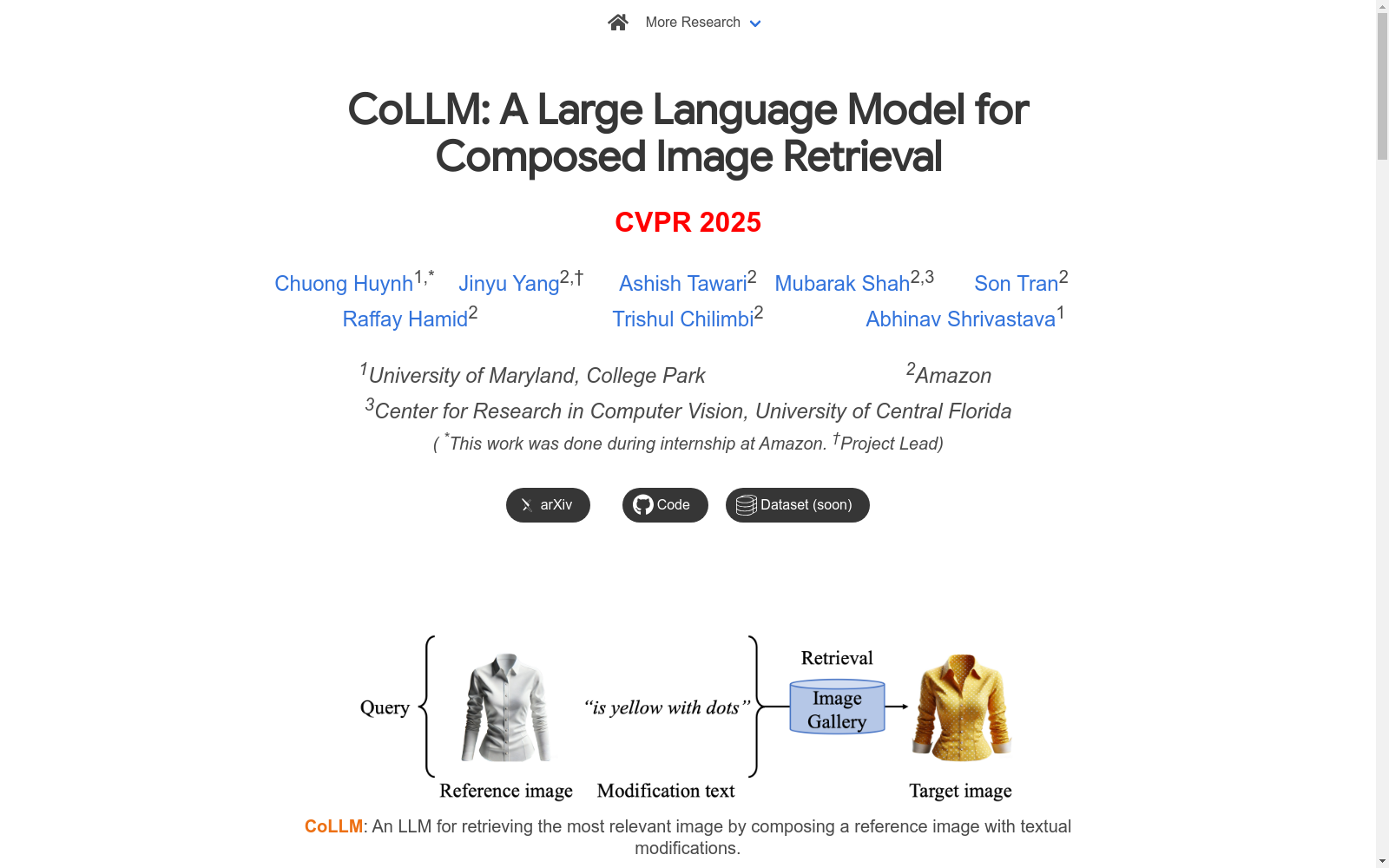
构建方式
Multi-Text CIR (MTCIR)数据集的构建采用了创新的两阶段方法,旨在解决现有数据集在多样性和自然语言描述上的不足。首先,从LLaVA-558k数据集中筛选图像,基于名词短语频率确保广泛的概念覆盖。随后,利用CLIP视觉相似性度量对图像进行配对,形成340万对图像。在修改文本生成阶段,采用多模态大型语言模型(MLLM)进行详细标注,再通过大型语言模型(LLM)描述图像间的差异。独特之处在于,MTCIR为每对图像提供多个简短的修改文本,覆盖不同属性,更贴近人类查询习惯。
特点
MTCIR数据集以其规模和多样性脱颖而出,包含340万图像对和1770万修改文本,平均每对图像提供5.18个描述。该数据集特别关注图像多样性和自然语言修改文本的生成,通过多类别修改文本(如属性变更、对象增减等)全面捕捉图像间的差异。此外,MTCIR采用真实图像而非合成图像,确保了数据的真实性和广泛的应用场景。数据集的另一个显著特点是其开放性和规模,是目前最大的开源合成CIR数据集,为研究社区提供了宝贵的资源。
使用方法
MTCIR数据集的使用方法灵活多样,适用于训练和评估 composed image retrieval (CIR) 模型。研究人员可以利用该数据集进行监督训练,通过参考图像、修改文本和目标图像的三元组学习多模态查询的联合嵌入。数据集提供的多个修改文本可用于增强模型的泛化能力,模拟真实场景中的多样化查询。此外,MTCIR还可用于零样本学习场景,通过合成三元组或结合视觉语言模型(VLMs)进行训练。数据集的多样性使其能够有效提升模型在复杂和细致修改文本下的表现,适用于电子商务、时尚和设计等多个领域。
背景与挑战
背景概述
Multi-Text CIR (MTCIR) 数据集由亚马逊与马里兰大学的研究团队于2025年提出,旨在解决组合图像检索(Composed Image Retrieval, CIR)任务中多模态查询的复杂需求。该数据集包含340万图像对和1770万修改文本,通过大语言模型(LLM)生成多样化的属性描述,弥补了传统CIR数据标注成本高昂且规模有限的缺陷。其创新性体现在利用视觉-语言模型(如LLaVA-Next-34B)自动生成细粒度文本修改指令,推动了电商、时尚设计等领域的精准图像搜索技术发展。
当前挑战
MTCIR面临的挑战主要体现在三方面:其一,领域问题层面,传统CIR方法难以处理复杂语义修改文本与图像的深层关联,需解决多模态融合的精度问题;其二,数据构建过程中,合成文本的多样性与自然性不足,且图像对需覆盖广泛场景以避免偏差;其三,评估环节存在标注模糊性,例如单一查询可能对应多个合理目标图像,需通过基准优化(如重构CIRR和Fashion-IQ数据集)提升评测可靠性。
常用场景
经典使用场景
Multi-Text CIR (MTCIR) 数据集在组合图像检索(Composed Image Retrieval, CIR)领域具有广泛的应用场景。该数据集通过提供大规模的图像对和多样化的修改文本,支持模型在零样本或少样本条件下进行高效训练。其经典使用场景包括电子商务中的视觉搜索系统,用户可以通过参考图像和自然语言描述来检索符合特定修改需求的目标图像。例如,在时尚推荐系统中,用户上传一件衬衫的图片并描述“将颜色改为蓝色并添加条纹”,系统即可返回符合要求的商品图像。
实际应用
在实际应用层面,MTCIR 数据集显著提升了组合图像检索系统的性能。基于该数据集训练的模型可应用于智能设计辅助系统,设计师通过草图结合文字描述即可快速检索参考素材;在医疗影像分析中,医生可通过描述病灶变化特征检索相似病例。数据集还支持跨模态对话系统的开发,如家居场景中用户用“类似这个沙发但换成米色皮质”的指令检索商品。实验表明,使用MTCIR训练的模型在CIRR和Fashion-IQ等基准测试中实现了最高15%的性能提升。
衍生相关工作
MTCIR 数据集催生了一系列创新性研究工作。以CoLLM为代表的框架首次将大语言模型嵌入组合查询理解流程,通过球形线性插值生成参考图像表征。基于该数据集,Slerp-TAT提出了文本编码器重对齐方法,CIReVL探索了视觉-语言模型的联合嵌入生成。数据集还推动了评估体系的革新,如CIRCO引入的模糊样本检测机制。在应用层面,MagicLens和CoVR2等系统利用MTCIR实现了基于开放指令的图像检索,而WebCoVR则将其扩展至视频检索领域,形成了跨模态检索的技术生态。
以上内容由遇见数据集搜集并总结生成


