ExCap3D Dataset
收藏arXiv2025-03-21 更新2025-03-25 收录
下载链接:
https://cy94.github.io/excap3d/
下载链接
链接失效反馈官方服务:
资源简介:
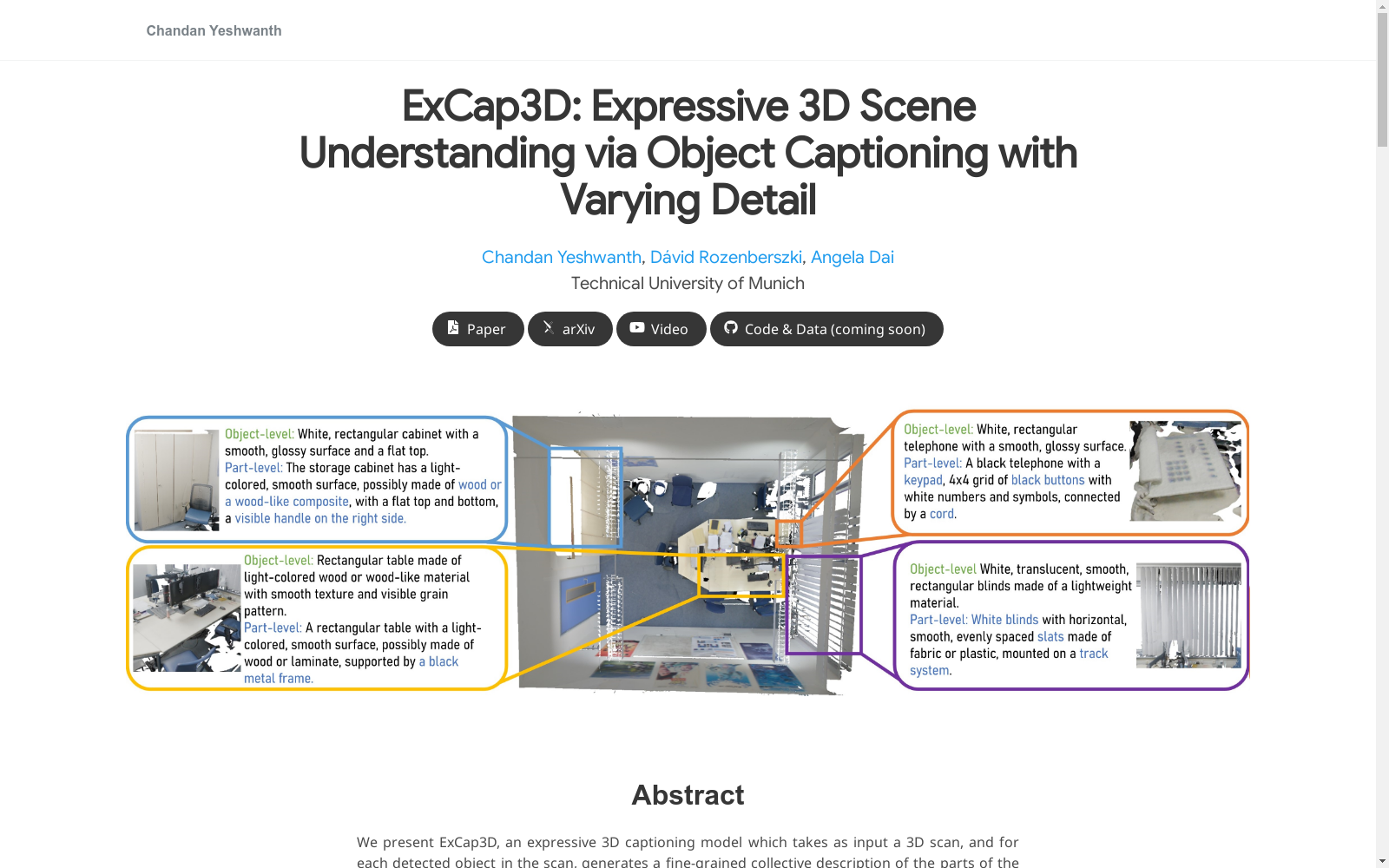
ExCap3D数据集是由慕尼黑工业大学创建的,包含947个室内场景中34k个3D物体的19万个带有不同细节级别的自然语言描述。该数据集通过利用视觉语言模型(VLM)对ScanNet++数据集的多视角进行字幕标注而生成,旨在推动表达性3D字幕任务的研究,即对3D场景中的物体进行多级别细节描述。
The ExCap3D dataset, constructed by the Technical University of Munich, encompasses 190,000 natural language descriptions with varying levels of detail for 34,000 3D objects across 947 indoor scenes. This dataset is generated by conducting multi-view captioning on the ScanNet++ dataset using vision-language models (VLMs), and its core objective is to advance research on the expressive 3D captioning task, which involves generating multi-level detailed descriptions for objects within 3D scenes.
提供机构:
慕尼黑工业大学
创建时间:
2025-03-21
搜集汇总
数据集介绍
构建方式
ExCap3D数据集的构建基于ScanNet++数据集,通过利用视觉语言模型(VLM)对高分辨率DSLR图像进行多视角标注,并结合ScanNet++提供的语义信息,实现了对3D室内场景中对象的细粒度描述。具体而言,该数据集通过投影3D实例注释到DSLR图像上,裁剪出对象区域,并利用VLM生成多视角描述,最终通过大型语言模型(LLM)整合多视角信息,形成对象级和部件级的详细描述。此外,部件级描述通过伪地面真实分割数据(使用MaskClustering和SAM生成)进一步丰富了数据集的细节层次。
特点
ExCap3D数据集的特点在于其多层次的描述能力,不仅包含对象级别的粗粒度描述,还提供了部件级别的细粒度细节。数据集涵盖了190k条文本描述,覆盖了34k个3D对象和947个室内场景,描述的细节包括颜色、纹理、材质和功能属性等。与现有数据集相比,ExCap3D在描述细节和语义类别数量上均有显著提升,且通过多视角推理确保了描述的鲁棒性和一致性。
使用方法
ExCap3D数据集的使用方法主要包括三个步骤:首先,通过3D实例分割模型(如Mask3D)检测场景中的对象实例;其次,利用对象级和部件级描述生成模型(如ExCap3D模型)对每个检测到的对象生成多层次的文本描述;最后,通过语义和文本一致性损失优化生成的描述,确保对象级和部件级描述的一致性。该数据集适用于3D场景理解、机器人导航、增强现实(AR)和虚拟现实(VR)等领域的任务,尤其适合需要细粒度场景描述的应用场景。
背景与挑战
背景概述
ExCap3D数据集由慕尼黑工业大学的研究团队于2025年提出,旨在解决三维室内场景理解中的多粒度对象描述问题。该数据集基于ScanNet++数据集构建,包含190,000条文本描述,覆盖34,000个三维对象和947个室内场景。其核心创新在于同时提供对象级和部件级的双重描述,突破了传统三维标注方法仅支持单一描述粒度的局限。该研究团队提出的ExCap3D模型通过视觉语言模型的多视角标注技术,实现了对物体整体特征和局部细节的协同描述,在CIDEr指标上分别获得17%和124%的性能提升,为增强现实、机器人导航等需要细粒度场景理解的领域提供了新的基础支持。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,传统三维场景描述方法难以平衡全局对象识别与局部部件特征描述的协同性,现有技术生成的单一粒度描述无法满足机器人精细操作等需要多层次语义理解的应用需求;在构建过程层面,研究团队需要解决多视角视觉语言模型标注的一致性难题,包括部件级伪标注的可靠性验证、跨视角描述信息的融合优化,以及对象整体描述与部件特征描述的语义对齐问题。此外,基于稀疏卷积网络的2cm体素分辨率限制也对薄型和小型物体的细粒度描述构成了技术瓶颈。
常用场景
经典使用场景
ExCap3D数据集在3D室内场景理解领域具有广泛的应用价值,尤其在增强现实(AR)、虚拟现实(VR)和机器人导航等场景中表现突出。通过提供多层次的细节描述,该数据集能够支持从粗粒度到细粒度的场景理解任务。例如,在机器人导航中,系统可以利用对象级别的描述快速识别场景中的主要物体,而通过部分级别的描述则可以获取更精细的物体属性,如材质、颜色和功能,从而实现更精准的操作和交互。
实际应用
在实际应用中,ExCap3D数据集为智能家居、无障碍辅助技术和自动化服务等场景提供了强大的支持。例如,在无障碍辅助领域,视觉障碍者可以通过多层次的物体描述获取更全面的环境信息;在智能家居系统中,机器人能够根据部分级别的细节描述精确操作物体,如调整椅子的脚踏板或识别桌子的材质。此外,该数据集还可用于虚拟导游、室内设计等需要高精度场景理解的领域。
衍生相关工作
ExCap3D数据集推动了多项相关研究的发展,尤其是在3D密集描述和视觉-语言模型结合的方向上。基于该数据集,研究者们提出了多种改进模型,如结合跨层次注意力机制的联合描述生成方法,以及利用语义一致性损失优化多粒度描述的模型。此外,该数据集还促进了3D场景理解与其他任务的融合,例如3D视觉问答(QA)和场景生成,进一步扩展了其在多模态学习中的应用范围。
以上内容由遇见数据集搜集并总结生成


