FinRpt
收藏Hugging Face2025-11-13 更新2025-11-14 收录
下载链接:
https://huggingface.co/datasets/jinsong8/FinRpt
下载链接
链接失效反馈官方服务:
资源简介:
FinRpt是一个用于自动生成股票研究报告的大型高质量的双语(中文和英文)基准数据集。该数据集旨在解决金融领域数据稀缺的问题,并促进大型语言模型在金融行业的发展。数据集的核心任务是给定公司的股票代码和特定日期,模型需要利用提供的多源异构财务数据生成结构良好、全面且逻辑连贯的研究报告。
创建时间:
2025-11-10
原始信息汇总
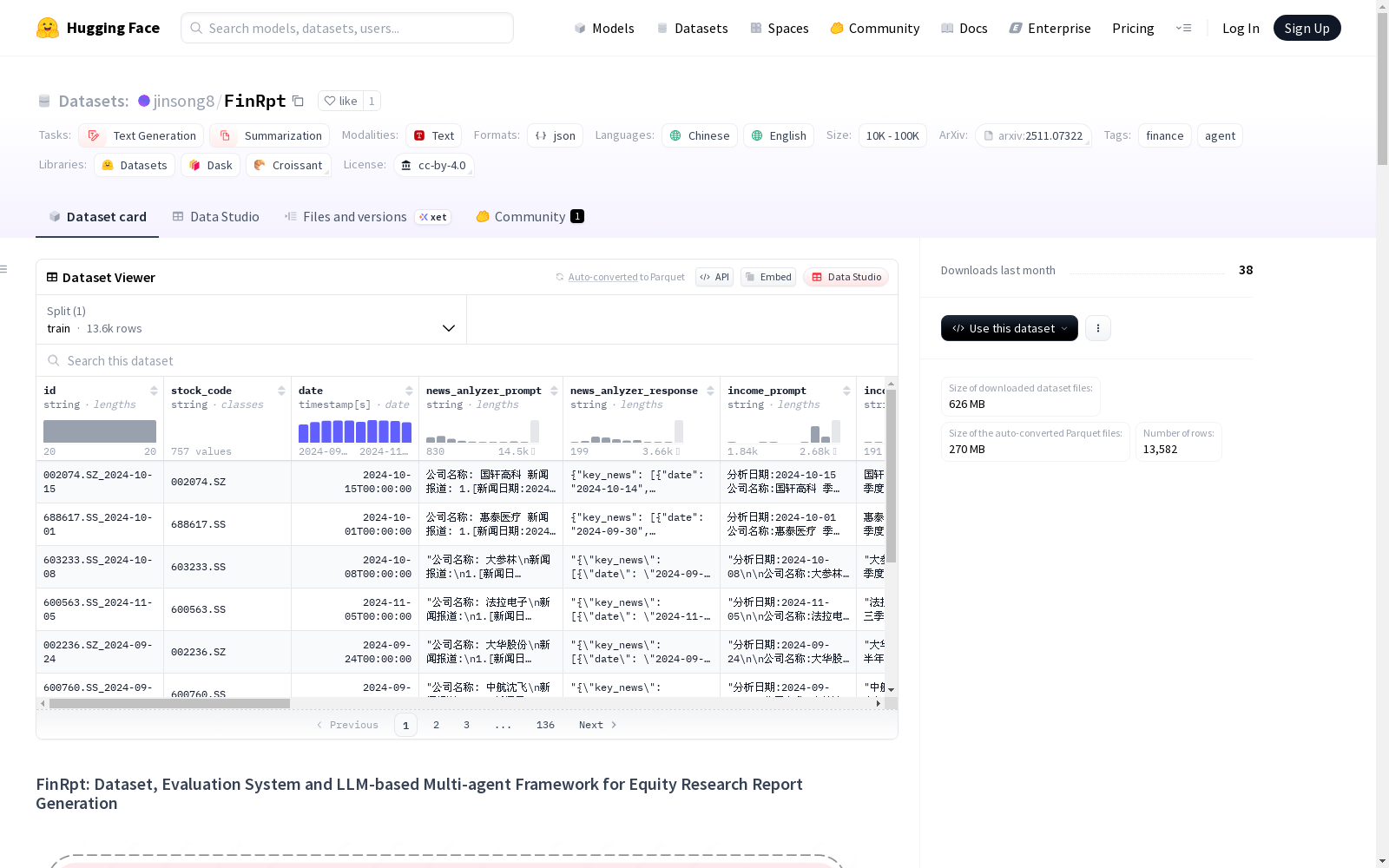
FinRpt数据集概述
数据集基本信息
- 名称:FinRpt
- 许可证:CC-BY-4.0
- 任务类别:文本生成、摘要生成
- 语言:中文、英文
- 标签:金融、智能体
- 规模:1K<n<10K
数据集描述
FinRpt是一个大规模、高质量的双语(英文和中文)基准数据集,专为自动化生成股权研究报告而设计。该数据集旨在解决该领域数据稀缺问题,并促进大型语言模型在金融领域的发展。
核心任务:给定公司股票代码和特定日期,模型应利用提供的多源异构财务数据生成结构良好、全面且逻辑连贯的股权研究报告。
数据集特点
- 报告使用FinRpt-Gen多智能体框架生成,模拟人类金融分析师的工作流程
- 包含最终生成的报告以及每个智能体的中间输入和输出
- 通过数据集增强模块确保数据质量
支持任务
- 文本生成:训练模型生成完整的股权研究报告
- 指令调优:包含大量提示-响应对,适用于指令调优LLM
- 金融摘要:可用于训练模型从季度收益数据生成财务摘要
数据结构
数据字段
id:唯一标识符,格式为股票代码_日期stock_code:股票代码date:分析日期- 多个智能体的提示和响应字段:
- 新闻分析智能体
- 利润表分析智能体
- 资产负债表分析智能体
- 现金流量表分析智能体
- 财务分析编写智能体
- 新闻分析编写智能体
- 管理与开发分析智能体
- 风险分析智能体
- 投资潜力与评级预测智能体
数据创建
- 创建理由:填补高质量长篇股权研究报告自动生成的空白
- 源数据:从公共金融数据API收集,整合七种不同数据类型
- 生成过程:使用FinRpt-Gen多智能体框架自动生成,GPT-4o作为核心LLM
使用注意事项
- 非投资建议:仅供学术研究使用,不构成任何形式的投资建议
- 数据时效性:数据集覆盖范围截至2024年11月初
- 模型偏差:数据由大型语言模型生成,可能继承其训练数据中的偏差
引用信息
bibtex @article{jin2025finrpt, title={FinRpt: Dataset, Evaluation System and LLM-based Multi-agent Framework for Equity Research Report Generation}, author={Jin, Song and Li, Shuqi and Zhang, Shukun and Yan, Rui}, journal={arXiv preprint arXiv:2511.07322}, year={2025} }
搜集汇总
数据集介绍
构建方式
在金融科技领域,自动化生成高质量研究报告的需求日益增长。FinRpt数据集通过多智能体框架FinRpt-Gen构建,模拟专业分析师的工作流程,整合公司档案、财务指标、新闻公告及市场数据等多源异构信息。生成过程采用GPT-4o作为核心语言模型,并经过数据集增强模块的三重优化:推荐评级校正确保投资建议与市场趋势一致,专家报告校正提升内容专业性,语言模型抛光增强文本可读性与逻辑连贯性。
特点
该数据集作为首个大规模双语股权研究报告生成基准,其突出特点在于完整保留了多智能体协作的中间过程。每个样本不仅包含最终研究报告,还囊括新闻分析、财务评估、风险识别等环节的提示与响应记录,形成层次化的分析链条。数据集覆盖中英文双语言环境,聚焦中国A股市场,兼具时序性与结构性,为模型训练提供深度可解释性支撑。
使用方法
研究人员可将该数据集应用于三大核心场景:通过端到端训练实现研究报告自动生成,利用丰富的提示-响应对进行指令微调以提升金融任务理解能力,或抽取特定模块开展财务摘要生成等子任务研究。使用前需注意数据时效性截至2024年11月,且生成内容含模型固有偏差,严禁作为实际投资决策依据。
背景与挑战
背景概述
随着金融科技领域的快速发展,自动化生成高质量研究报告成为学术界与产业界共同关注的焦点。FinRpt数据集由研究团队于2024年创建,旨在填补股权研究报告自动生成领域的数据空白。该数据集通过整合多源异构金融数据,构建了涵盖公司概况、财务指标、新闻公告等维度的双语基准,为大型语言模型在金融领域的深度应用提供了重要支撑。其创新性地采用多智能体框架模拟人类分析师工作流,不仅产出最终报告,更完整保留了中间推理过程,对推动可解释金融AI研究具有里程碑意义。
当前挑战
在解决股权研究报告自动生成这一核心问题时,需克服多重技术障碍:如何从异构数据源中提取有效特征,如何保证生成内容在投资建议与市场趋势间的一致性,以及如何确保专业术语与金融逻辑的准确表达。数据集构建过程中面临三大挑战:一是多模态金融数据的时序对齐与噪声过滤,二是通过评级校正模块消除模型生成偏差,三是依靠专家报告校正机制维持行业标准,这些难点共同构成了该领域技术突破的关键瓶颈。
常用场景
经典使用场景
在金融科技领域,FinRpt数据集为自动化生成股权研究报告提供了标准化实验平台。该数据集通过整合多源异构金融数据,包括公司财务指标、市场新闻、股价走势等信息,构建了完整的分析链条。研究人员可基于其结构化提示-响应对,训练模型模拟专业分析师的工作流程,从数据提取到最终报告生成实现端到端学习。
实际应用
在现实场景中,该数据集支撑的智能投研系统已应用于金融机构的初步研究环节。通过自动化处理海量金融数据,系统能够快速生成符合行业规范的研究报告框架,显著提升分析师的工作效率。部分券商机构正利用此类技术构建辅助决策系统,用于上市公司基本面分析的初步筛查和风险预警,但需注意其结论仍需专业人工复核。
衍生相关工作
基于该数据集衍生的经典研究包括多智能体协作框架的优化探索,如改进金融领域专用代理的决策逻辑。后续工作聚焦于跨市场泛化能力提升,尝试将A股市场验证的模型迁移至港股、美股市场。同时催生了金融报告自动评估体系的研究浪潮,推动了基于事实验证的生成质量量化标准建立。
以上内容由遇见数据集搜集并总结生成


