Social Vision and Language Dataset (SVLD)
收藏arXiv2020-06-05 更新2024-06-21 收录
下载链接:
https://cannylab.github.io/svld
下载链接
链接失效反馈官方服务:
资源简介:
Social Vision and Language Dataset (SVLD) 是由加州大学伯克利分校创建的一个公开数据集,旨在通过提供同一上下文中的视觉和语言数据来推动多模态学习。该数据集包含来自社交媒体网站的677,181个帖子,其中包括290万张帖子图片、48.8万个帖子视频、140万条评论图片、460万条评论视频和9690万条评论。SVLD数据集的内容丰富,包括图像、视频、文本和社交数据,适用于图像字幕生成、图像分类、情感分析等多种任务。数据集的创建过程涉及使用Imgur API和开源爬虫工具进行数据收集。SVLD的应用领域广泛,旨在解决多模态学习中的长期问题,如提高模型在处理同步音频、视频和语言信息时的性能。
Social Vision and Language Dataset (SVLD) was developed by the University of California, Berkeley, as an open-access dataset designed to advance multimodal learning by offering paired visual and linguistic data within identical contextual scenarios. The dataset encompasses 677,181 posts sourced from social media platforms, including 2.9 million post images, 488,000 post videos, 1.4 million comment images, 4.6 million comment videos, and 96.9 million comments. Featuring rich content spanning images, videos, texts and social data, SVLD is applicable to a diverse array of tasks such as image captioning, image classification, sentiment analysis and more. The data collection process for SVLD utilized the Imgur API and open-source crawler tools. With a wide range of application scenarios, SVLD aims to address long-standing challenges in multimodal learning, such as enhancing model performance when processing synchronized audio, video and linguistic information.
提供机构:
加州大学伯克利分校
创建时间:
2020-06-05
搜集汇总
数据集介绍
构建方式
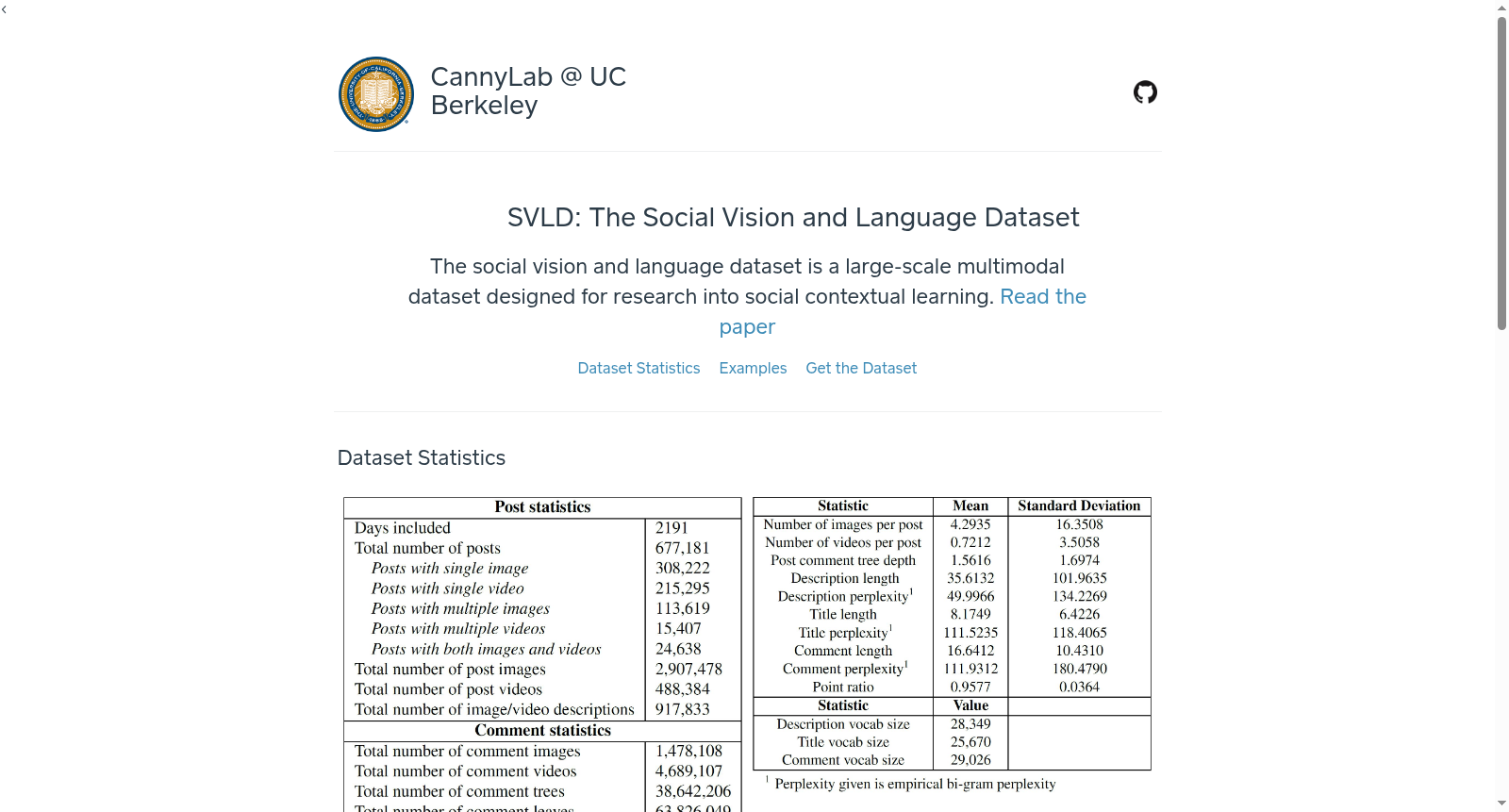
在多媒体社会分析的研究背景下,视觉与语言数据的深度融合是推动多模态智能发展的关键。Social Vision and Language Dataset (SVLD) 的构建源于对社交媒体平台 imgur.com 的大规模数据采集,通过其公开API及开源爬取工具,历时八个月获取了超过67.7万条帖子及其完整的评论树。每条样本均包含成对的图像或视频、自然语言标题、描述、分类标签、社交互动指标(如点赞与收藏数),以及评论中嵌入的额外图像与视频。数据涵盖约290万张帖子图像、48.8万个帖子视频、147.8万条评论图像、468.9万条评论视频和9696.1万条评论文本,形成了多模态信息天然同步的丰富语料库。
特点
SVLD 的核心特点在于其多模态数据的天然对齐与社会语境的高度融合。不同于传统数据集仅聚焦单一模态或小规模专业标注,SVLD 提供了帖子内图像、视频与文本的成对关联,以及评论树中嵌套的多模态回复,极大丰富了跨模态学习场景。数据集涵盖从基础物体分类到高层社会概念(如“有趣”、“温馨”)的多样化标签,并包含点赞比、浏览量等反映社区反馈的量化指标。其时间戳信息还支持对社交媒体主题演变的分析,而评论树的复杂结构则为上下文理解与对话建模提供了独特挑战。
使用方法
SVLD 适用于多种多模态学习任务,如图像描述、视频分类、情感分析及社交影响力预测。使用时,用户可提取帖子中的图像与视频帧,通过预训练模型(如ResNet152或D3D)进行特征编码,同时利用BERT对标题、描述及评论进行语言表征。各模态特征可通过全连接网络融合,用于回归任务(如预测点赞比)或分类任务(如标签预测)。数据集还支持基于评论树的问答与对话生成研究,以及结合时间戳的社交主题动态分析。官方提供了基线代码与处理流程,便于研究者快速上手。
背景与挑战
背景概述
在人工智能领域,多模态学习旨在融合视觉与语言等多种信息源以模拟人类对世界的综合认知能力,然而现有研究多聚焦于单一模态任务,大规模同步多模态数据的匮乏成为制约该领域发展的关键瓶颈。为填补这一空白,加州大学伯克利分校的Bofan Xue、David Chan与John Canny于2020年提出了社交视觉与语言数据集(Social Vision and Language Dataset, SVLD)。该数据集源自社交平台Imgur,包含逾67.7万条帖子、290万张图片、48.8万个视频以及9690万条多模态评论,并同步收录了标题、标签、评分等元数据,为图像描述、情感分析、社会动态建模等任务提供了前所未有的丰富资源。SVLD的发布不仅推动了多模态学习从理论走向大规模实践,也为社交内容理解与智能系统开发奠定了重要基石。
当前挑战
SVLD面临的核心挑战涵盖领域问题与构建过程两个层面。在领域问题方面,现有模型多依赖单模态或小规模配对数据,难以应对同步多模态信息中视觉与语言的复杂关联,例如如何从帖子标题、图片、视频及评论树中联合学习社会情感与主题迁移,当前基线实验显示简单多模态融合在预测点赞率时性能有限,表明跨模态语义鸿沟与分布漂移亟待攻克。在构建过程中,数据爬取遭遇了Imgur服务器错误、网络中断及图像处理库异常等困难,导致每日采集量不均;此外,评论树结构多样(如浅层意见分享与深层问答),且包含文本、图片与视频的混合回复,使得数据清洗与标准化成为巨大挑战,特别是处理长尾分布下的负样本稀缺问题,进一步增加了模型训练的复杂性。
常用场景
经典使用场景
SVLD作为大规模多模态社会媒体数据集,核心使用场景在于整合视觉与语言信息进行联合建模。研究者可借助其丰富的图像、视频、文本及评论树结构,开展图像描述生成、视频理解、多模态情感分析以及社会互动预测等经典任务。数据集中每个样本均包含配对的视觉内容与自然语言标题、描述及标签,为跨模态对齐与融合提供了天然实验场,尤其适合探索视觉与语言在真实社交语境中的协同学习范式。
实际应用
在实际应用层面,SVLD为内容推荐系统、社交媒体舆情监控与内容审核工具提供了坚实的数据基础。通过建模帖子点赞率、评论互动模式及标签分布,可开发用于预测内容流行度的智能算法,辅助广告投放与营销策略优化。此外,数据集中丰富的多模态评论树可驱动对话式AI与智能客服系统的训练,使其在真实社交语境下生成更具相关性与情感共鸣的回复,从而提升人机交互的自然度。
衍生相关工作
SVLD的发布催生了一系列相关研究工作。受其多模态融合框架启发,学界涌现出基于Transformer的跨模态编码器与注意力融合机制,如将图像、视频与文本特征通过堆叠全连接网络联合建模。评论树结构也推动了图神经网络在对话建模中的应用,研究者尝试从树状回复中提取上下文依赖关系。此外,数据集的时间戳信息促进了非平稳社会主题演化预测模型的开发,为动态内容理解与趋势分析开辟了新方向。
以上内容由遇见数据集搜集并总结生成


