megalith-10m
收藏魔搭社区2025-12-05 更新2024-08-31 收录
下载链接:
https://modelscope.cn/datasets/AI-ModelScope/megalith-10m
下载链接
链接失效反馈官方服务:
资源简介:
# 🗿 Megalith-10m
### What is Megalith-10m?

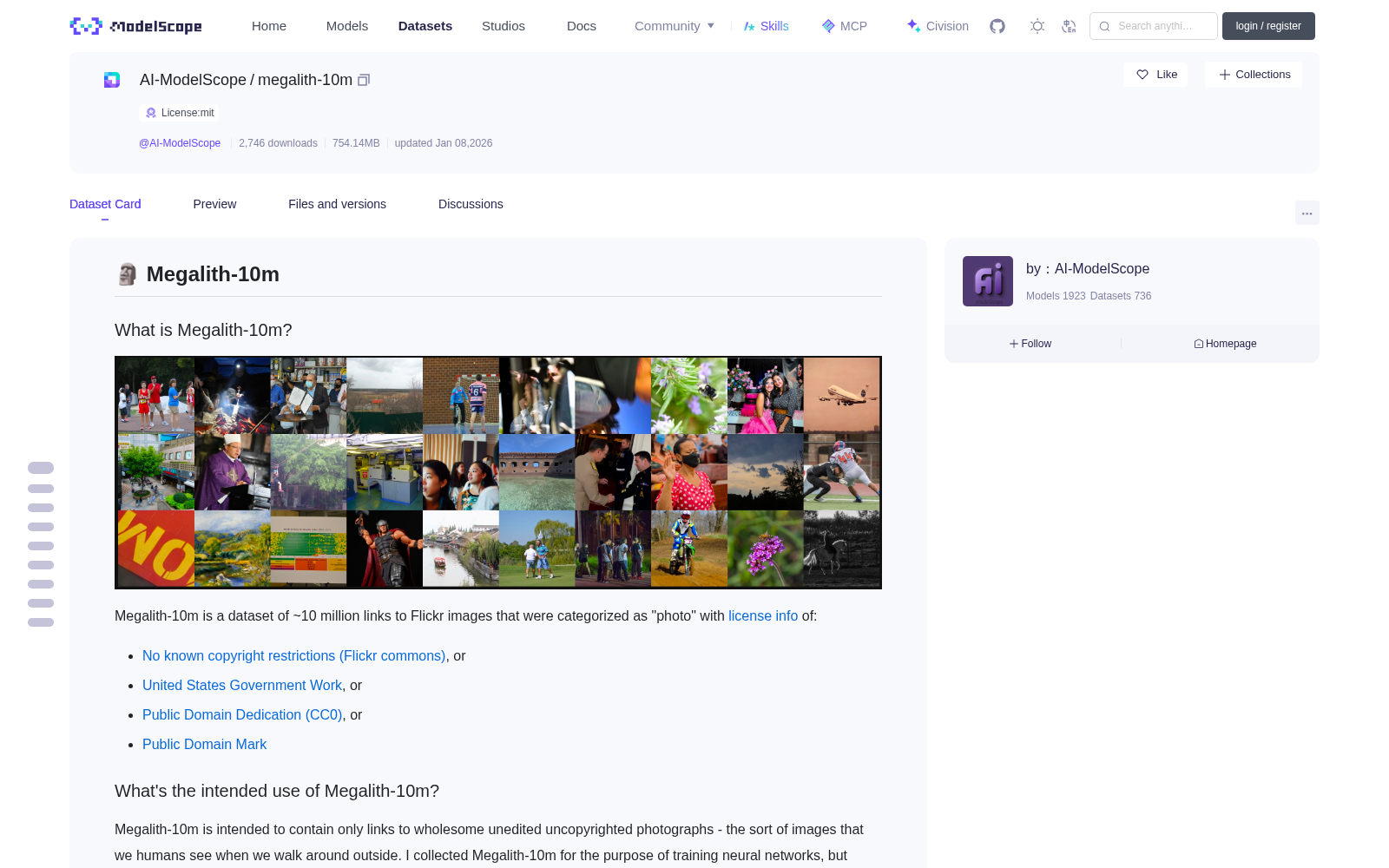
Megalith-10m is a dataset of ~10 million links to Flickr images that were categorized as "photo" with [license info](https://www.flickr.com/services/api/flickr.photos.licenses.getInfo.htm) of:
* [No known copyright restrictions (Flickr commons)](https://www.flickr.com/commons/usage), or
* [United States Government Work](https://en.wikipedia.org/wiki/Copyright_status_of_works_by_the_federal_government_of_the_United_States), or
* [Public Domain Dedication (CC0)](https://creativecommons.org/publicdomain/zero/1.0/), or
* [Public Domain Mark](https://en.wikipedia.org/wiki/Public_Domain_Mark)
### What's the intended use of Megalith-10m?
Megalith-10m is intended to contain only links to wholesome unedited uncopyrighted photographs - the sort of images that we humans see when we walk around outside.
I collected Megalith-10m for the purpose of training neural networks, but you're welcome to use Megalith-10m for whatever you want.
Of course, I recommend conducting your own independent analysis of content and copyright status before using Megalith-linked images in Serious Projects.
### Where can I get text captions for Megalith-10m?
* [DrawThings.ai](https://drawthings.ai) have uploaded [`megalith-10m-sharecap`](https://huggingface.co/datasets/drawthingsai/megalith-10m-sharecap) (captions made with [ShareCaptioner](https://huggingface.co/Lin-Chen/ShareCaptioner)) <br/><a href="https://huggingface.co/datasets/drawthingsai/megalith-10m-sharecap"><img src='https://cdn-uploads.huggingface.co/production/uploads/630447d40547362a22a969a2/vXM-x4TNfRn3AQTRGveLn.png' width=720px/></a>
* [AI Picasso](https://aipicasso.app) have uploaded [`megalith-10m-florence2`](https://huggingface.co/datasets/aipicasso/megalith-10m-florence2) (captions made with [Florence 2](https://huggingface.co/microsoft/Florence-2-large)) <br/><a href="https://huggingface.co/datasets/aipicasso/megalith-10m-florence2"><img src='https://cdn-uploads.huggingface.co/production/uploads/630447d40547362a22a969a2/RVHZluYqq4-pB1mFpq5Qj.png' width=720px/></a>
* [CaptionEmporium](https://huggingface.co/CaptionEmporium) have uploaded [`flickr-megalith-10m-internvl2-multi-caption`](https://huggingface.co/datasets/CaptionEmporium/flickr-megalith-10m-internvl2-multi-caption) (captions made with [InternVL2-8B](https://huggingface.co/datasets/CaptionEmporium/flickr-megalith-10m-internvl2-multi-caption/blob/main/OpenGVLab/InternVL2-8B) as well as shorter single-sentence captions made by summarizing the InternVL2/Florence2/ShareCaptioner results with [Llama3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)) <br/><a href="https://huggingface.co/datasets/CaptionEmporium/flickr-megalith-10m-internvl2-multi-caption"><img src='https://cdn-uploads.huggingface.co/production/uploads/630447d40547362a22a969a2/BObamPthy8kiQICGjCQ4f.png' width=720px/></a>
* [Moondream](https://moondream.ai) have uploaded [`megalith-mdqa`](https://huggingface.co/datasets/moondream/megalith-mdqa), captions and Q&A pairs made with Moondream
### How can I efficiently download the images referenced by Megalith-10m?
* [DrawThings.ai](https://drawthings.ai) has archived the images linked by Megalith-10m here: https://huggingface.co/datasets/drawthingsai/megalith-10m
* If you want to download Megalith-10m images directly from Flickr, I posted a sample [downloading command](https://huggingface.co/datasets/madebyollin/megalith-10m/discussions/2#6693f3a7e05c3f1e0e0d62c1) you can use with [img2dataset](https://github.com/rom1504/img2dataset/)
### How was Megalith-10m collected?
I used the Flickr API to query for photos matching some basic criteria (SFW photo with CC0 / public domain license info), which gave me around 12 million links.
I then used various filtering strategies to exclude ~2m image links which didn't appear to point to wholesome public-domain minimally-edited photos.
These filtering strategies included:
1. Account-level filtering, based on
1. Manual adjudication for the top 5000 most prolific accounts
2. Repeated-watermark detection
2. Photo-level filtering, based on
1. Image metadata
1. Mention of copyright restrictions in the EXIF tags
2. Mention of copyright restrictions in the text description
2. Image content
1. Duplicate detection
2. CLIP-assisted checking for
1. Clearly non-photo images (illustrations, screenshots, 3d renders, etc.)
2. Clearly non-wholesome images (violence, nudity, etc.)
3. Minimum-resolution enforcement (at least 256x256 pixels)
4. Manual spot-checking of some images and metadata
### What content does Megalith-10m contain?
The [demo notebook](./Megalith_Demo_Notebook.ipynb) shows a random sample of 100 images being loaded from the links in Megalith-10m.
Based on this random sample, I would estimate the following dataset statistics:
* 5-7% of images may have minor edits or annotations (timestamps, color grading, borders, etc.)
* 1-2% of images may be copyright-constrained (watermarks or text descriptions cast doubt on the license metadata)
* 1-2% of images may be non-wholesome (guns, suggestive poses, etc.)
* 1-2% of images may be non-photos (paintings, screenshots, etc.)
### Is 10 million images really enough to teach a neural network about the visual world?
For the parts of the visual world that are well-represented in Megalith-10m, definitely!
Projects like [CommonCanvas](https://arxiv.org/abs/2310.16825), [Mitsua Diffusion](https://huggingface.co/Mitsua/mitsua-diffusion-one), and [Matryoshka Diffusion](https://arxiv.org/abs/2310.15111)
have shown that you can train useable generative models on similarly-sized image datasets.
Of course, many parts of the world aren't well-represented in Megalith-10m, so you'd need additional data to learn about those.
### What have people done with Megalith-10m?
1. AI Picasso have successfully trained a full text-to-image model [CommonArt β](https://huggingface.co/aipicasso/commonart-beta) on Megalith-10m (and other open datasets).
2. I've successfully trained small [text-to-image models](https://x.com/madebyollin/status/1788282620981497981) on Megalith-10m for my own education.
3. Megalith-10m was among the datasets used to train DeepSeek's [Janus](https://github.com/deepseek-ai/Janus) and [DeepSeek-VL2](https://arxiv.org/abs/2412.10302) models
4. Megalith-10m was used to train [Bokeh Diffusion](https://atfortes.github.io/projects/bokeh-diffusion/) which adds bokeh control to T2I models
5. Megalith-10m was used to help train [OpenSDI](https://github.com/iamwangyabin/OpenSDI), a detector for diffusion-generated images
6. Megalith-10m was used to train [otoro](https://huggingface.co/aihub-geniac/oboro), an open-weights image generator by AiHUB
# 🗿 巨石10M(Megalith-10m)
### 什么是Megalith-10m?

Megalith-10m是一个包含约1000万条Flickr图片链接的数据集,这些图片被归类为“照片”,且具备以下任一许可信息:
* [无已知版权限制(Flickr公共图库)](https://www.flickr.com/commons/usage)
* [美国政府作品](https://en.wikipedia.org/wiki/Copyright_status_of_works_by_the_federal_government_of_the_United_States)
* [公共领域贡献(CC0)](https://creativecommons.org/publicdomain/zero/1.0/)
* [公共领域标记](https://en.wikipedia.org/wiki/Public_Domain_Mark)
### Megalith-10m的预期用途是什么?
本数据集仅包含指向健康合规、未编辑的无版权照片的链接——即我们日常户外行走时所见的各类图像。我收集Megalith-10m的初衷是用于神经网络训练,但你可将其用于任意场景。当然,若要在正式项目中使用本数据集关联的图片,我建议你先自行对内容及版权状态进行独立核查。
### 我可以在哪里获取Megalith-10m的文本标注?
* [DrawThings.ai](https://drawthings.ai) 已上传 [`megalith-10m-sharecap`](https://huggingface.co/datasets/drawthingsai/megalith-10m-sharecap)(标注由[ShareCaptioner](https://huggingface.co/Lin-Chen/ShareCaptioner)生成)<br/><a href="https://huggingface.co/datasets/drawthingsai/megalith-10m-sharecap"><img src='https://cdn-uploads.huggingface.co/production/uploads/630447d40547362a22a969a2/vXM-x4TNfRn3AQTRGveLn.png' width=720px/></a>
* [AI Picasso](https://aipicasso.app) 已上传 [`megalith-10m-florence2`](https://huggingface.co/datasets/aipicasso/megalith-10m-florence2)(标注由[Florence 2](https://huggingface.co/microsoft/Florence-2-large)生成)<br/><a href="https://huggingface.co/datasets/aipicasso/megalith-10m-florence2"><img src='https://cdn-uploads.huggingface.co/production/uploads/630447d40547362a22a969a2/RVHZluYqq4-pB1mFpq5Qj.png' width=720px/></a>
* [CaptionEmporium](https://huggingface.co/CaptionEmporium) 已上传 [`flickr-megalith-10m-internvl2-multi-caption`](https://huggingface.co/datasets/CaptionEmporium/flickr-megalith-10m-internvl2-multi-caption)(标注由[InternVL2-8B](https://huggingface.co/datasets/CaptionEmporium/flickr-megalith-10m-internvl2-multi-caption/blob/main/OpenGVLab/InternVL2-8B)生成,同时通过[Llama3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct)对InternVL2、Florence2及ShareCaptioner的标注结果进行摘要,生成简短的单句标注)<br/><a href="https://huggingface.co/datasets/CaptionEmporium/flickr-megalith-10m-internvl2-multi-caption"><img src='https://cdn-uploads.huggingface.co/production/uploads/630447d40547362a22a969a2/BObamPthy8kiQICGjCQ4f.png' width=720px/></a>
* [Moondream](https://moondream.ai) 已上传 [`megalith-mdqa`](https://huggingface.co/datasets/moondream/megalith-mdqa),包含由Moondream生成的标注及问答对。
### 我该如何高效下载Megalith-10m关联的图片?
* [DrawThings.ai](https://drawthings.ai) 已将Megalith-10m关联的图片归档于此:https://huggingface.co/datasets/drawthingsai/megalith-10m
* 若你希望直接从Flickr下载图片,我发布了一份示例[下载命令](https://huggingface.co/datasets/madebyollin/megalith-10m/discussions/2#6693f3a7e05c3f1e0e0d62c1),可配合[img2dataset](https://github.com/rom1504/img2dataset/)工具使用。
### Megalith-10m是如何收集的?
我通过Flickr API查询符合基础条件的图片(即符合SFW标准的照片,且具备CC0/公共领域许可信息),共获得约1200万条链接。随后我通过多种过滤策略剔除了约200万条指向非健康公共领域、未经过度编辑的图片的链接。具体过滤策略包括:
1. 账号级过滤:
1. 对前5000个多产账号进行人工审核
2. 重复水印检测
2. 图片级过滤:
1. 图片元数据:
1. EXIF标签中提及版权限制的内容
2. 文本描述中提及版权限制的内容
2. 图片内容:
1. 重复检测
2. 基于CLIP的辅助检查:
1. 明显非照片类图像(插画、截图、3D渲染图等)
2. 明显非健康图像(暴力、色情等)
3. 最低分辨率限制(至少256×256像素)
4. 部分图片及元数据的人工抽检
### Megalith-10m包含哪些内容?
[演示笔记本](./Megalith_Demo_Notebook.ipynb)展示了从Megalith-10m的链接中随机抽取的100张图片的加载效果。基于该随机样本,我估算得到以下数据集统计情况:
* 5%-7%的图片可能存在轻微编辑或标注(如时间戳、色彩分级、边框等)
* 1%-2%的图片可能存在版权限制(水印或文本描述对许可元数据提出质疑)
* 1%-2%的图片可能包含非健康内容(枪支、暗示性姿势等)
* 1%-2%的图片可能属于非照片类(绘画、截图等)
### 1000万张图片真的足够让神经网络学习视觉世界的知识吗?
对于Megalith-10m中充分覆盖的视觉领域部分,当然足够!诸如[CommonCanvas](https://arxiv.org/abs/2310.16825)、[Mitsua Diffusion](https://huggingface.co/Mitsua/mitsua-diffusion-one)以及[Matryoshka Diffusion](https://arxiv.org/abs/2310.15111)等项目已证明,你可以在规模相近的图片数据集上训练出可用的生成式模型。当然,世界上诸多场景并未在Megalith-10m中得到充分体现,因此若要学习这些场景,你需要补充额外的数据。
### 人们使用Megalith-10m完成了哪些工作?
1. AI Picasso已基于Megalith-10m(及其他开源数据集)成功训练了完整的文本到图像生成模型[CommonArt β](https://huggingface.co/aipicasso/commonart-beta)。
2. 我本人基于Megalith-10m训练了小型文本到图像生成模型,用于个人学习研究。
3. Megalith-10m是训练DeepSeek的[Janus](https://github.com/deepseek-ai/Janus)及[DeepSeek-VL2](https://arxiv.org/abs/2412.10302)模型所使用的数据集之一。
4. Megalith-10m被用于训练[Bokeh Diffusion](https://atfortes.github.io/projects/bokeh-diffusion/),该模型可为文本到图像生成模型添加散景控制能力。
5. Megalith-10m被用于辅助训练[OpenSDI](https://github.com/iamwangyabin/OpenSDI),一款扩散生成图像检测器。
6. Megalith-10m被用于训练[otoro](https://huggingface.co/aihub-geniac/oboro),一款由AiHUB开发的开源权重图像生成模型。
提供机构:
maas创建时间:
2024-07-04
搜集汇总
数据集介绍
背景与挑战
背景概述
Megalith-10m 是一个包含约1000万条Flickr图像链接的数据集,这些图像被标记为'照片',并具有公共领域或类似版权许可,旨在提供未经编辑的未受版权保护的照片资源,主要用于神经网络训练。数据集通过Flickr API收集,并经过过滤以确保图像质量,已被应用于多个AI项目,如文本到图像模型和视觉语言模型的训练。
以上内容由遇见数据集搜集并总结生成


