PHMartialLaw-NER_final
收藏Hugging Face2025-11-25 更新2025-11-26 收录
下载链接:
https://huggingface.co/datasets/etdvprg/PHMartialLaw-NER_final
下载链接
链接失效反馈官方服务:
资源简介:
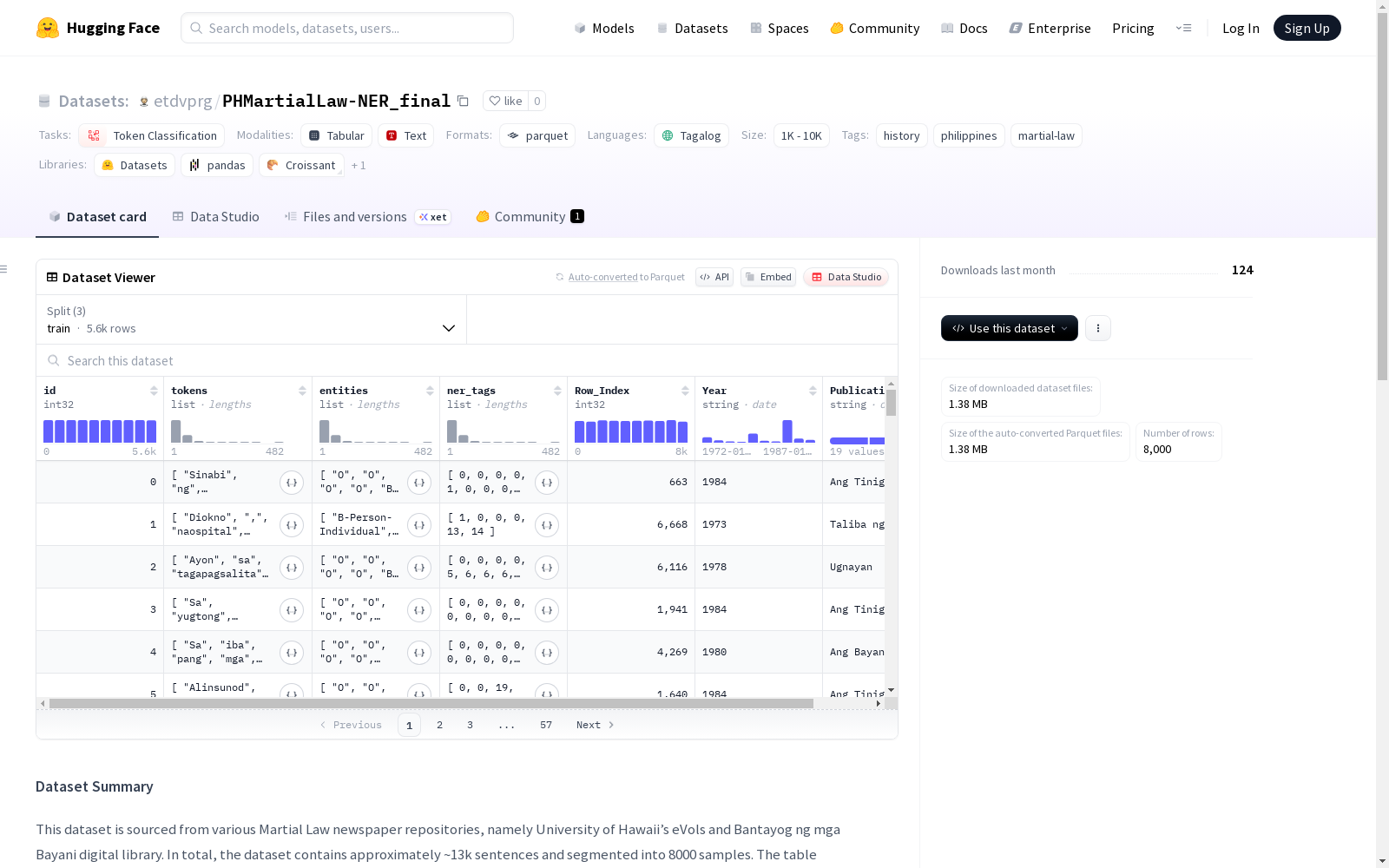
这是一个从菲律宾戒严时期报纸库收集而来的数据集,包含大约13000个句子,分为8000个样本。数据集的实体是根据Impresso指南制定的,并且对每种实体的token分布进行了统计。数据集分为训练集、验证集和测试集,每个样本包含id、tokenized文本、实体标签、ner标签、原始数据行索引、出版年份和出版商信息。数据标注通过三个标注员以迭代方式进行,并经过质量保证阶段。
创建时间:
2025-11-12
原始信息汇总
PHMartialLaw-NER数据集概述
数据集基本信息
- 数据集名称: ph-martial_law-ner
- 语言: 菲律宾语(tl)
- 任务类别: 标记分类
- 数据规模: 1K<n<10K
- 总样本数: 8000
- 总大小: 9,052,697字节
数据来源
- 夏威夷大学eVols报纸库
- Bantayog ng mga Bayani数字图书馆
- 菲律宾戒严时期报纸资料
数据集结构
数据划分
| 划分 | 样本数 | 大小(字节) |
|---|---|---|
| 训练集 | 5,602 | 6,294,856 |
| 验证集 | 799 | 892,624 |
| 测试集 | 1,599 | 1,865,217 |
数据字段
id: 整型样本IDtokens: 字符串列表,分词后的标记entities: 字符串列表,IOB格式分类标签ner_tags: 整型列表,0表示外部,1-28对应实体类型Row_Index: 整型,原始数据表格行索引Year: 字符串,出版年份Publication: 字符串,出版商
实体标注体系
实体类型及编码
| 编码 | 实体类型 | 描述 |
|---|---|---|
| 0 | O | 外部 |
| 1-2 | Person-Individual | 个人 |
| 3-4 | Person-Collective | 集体人物 |
| 5-6 | Organization-Political | 政治组织 |
| 7-8 | Organization-Government | 政府组织 |
| 9-10 | Organization-Military | 军事组织 |
| 11-12 | Organization-Other | 其他组织 |
| 13-14 | Location | 地点 |
| 15-16 | Time | 时间 |
| 17-18 | Production-Media | 媒体作品 |
| 19-20 | Production-Government | 政府文件 |
| 21-22 | Production-Doctrine | 学说文献 |
| 23-24 | Numerical Statistics | 数值统计 |
| 25-26 | Object-Weapon | 武器对象 |
| 27-28 | Event | 事件 |
实体分布统计
训练集实体数量
- 个人: 3,359
- 集体人物: 876
- 政治组织: 893
- 政府组织: 1,460
- 军事组织: 958
- 其他组织: 918
- 地点: 3,118
- 时间: 1,396
- 媒体作品: 538
- 政府文件: 518
- 学说文献: 1,336
- 数值统计: 2,144
- 事件: 896
- 武器对象: 332
标注质量
- 标注人员: 3名标注员
- 标注流程: 迭代式标注,定期讨论修订指南
- 科恩卡帕系数(全部标记): 0.86
- 科恩卡帕系数(仅标注标记): 0.72
- F1分数: 0.74
搜集汇总
数据集介绍
构建方式
在历史文献数字化研究领域,PHMartialLaw-NER_final数据集通过系统化采集与标注流程构建而成。其原始文本来源于夏威夷大学eVols和Bantayog ng mga Bayani数字图书馆的戒严时期报刊档案,经过专业团队采用迭代式标注方法,由三名标注员遵循Impresso指南对实体进行边界划分与类型标记。在每轮标注后研究人员会集体讨论修订标注规范,最终形成包含8000个样本的语料库,并通过科恩卡帕系数等指标进行质量验证。
使用方法
针对历史文本挖掘任务,该数据集支持标准的三阶段建模流程。研究者可基于训练集开发命名实体识别模型,利用验证集进行超参数调优,最终通过测试集评估模型性能。数据字段包含词汇序列、IOB格式标签及元数据信息,支持直接输入BERT等预训练模型进行微调。特别设计的年代与出版方字段为时序分析和媒体偏见研究提供了跨维度验证可能。
背景与挑战
背景概述
菲律宾戒严令命名实体识别数据集由学术机构基于历史文献数字化需求构建,聚焦于东南亚政治史研究领域。该数据集源自夏威夷大学eVols档案馆与民族英雄纪念碑数字图书馆的戒严时期报刊资料,通过系统标注形成了涵盖人物个体与集体、政治组织、政府机构、军事单位等18类实体的多层次标注体系。其创建旨在解决历史文本中实体关系的自动化抽取难题,为东南亚殖民史与威权统治研究提供结构化数据支撑,推动数字人文方法与历史语义分析的交叉融合。
当前挑战
该数据集面临领域问题与构建过程双重挑战:在学术层面需解决历史文献中实体指称模糊性与时空语境依赖性问题,例如戒严时期组织机构变迁导致的实体消歧困难;技术构建过程中遭遇原始报刊数字化噪声干扰,三位标注者虽经多轮迭代协商,科恩卡帕系数仍仅达0.72,未达0.8的可靠性阈值,反映出台风时期军事术语与政治实体标注边界判定的复杂性。
常用场景
经典使用场景
在历史文本挖掘领域,PHMartialLaw-NER_final数据集为命名实体识别任务提供了丰富的标注资源。该数据集聚焦于菲律宾戒严时期的历史文献,涵盖人物、组织、地点等17种细粒度实体类别,典型应用于训练序列标注模型以自动提取历史档案中的结构化信息。通过对新闻文本的实体边界和类型识别,研究者能够系统分析戒严时期的政治格局与社会动态。
解决学术问题
该数据集有效解决了历史文献数字化过程中的信息抽取难题。通过精确标注军政机构、历史人物与事件等实体,为量化历史研究提供了数据基础,显著提升了历史事件关联分析的准确性。其细粒度标注体系突破了传统NER模型对历史专有名词的识别瓶颈,为东南亚殖民史研究提供了新的方法论支持。
实际应用
在文化遗产保护实践中,该数据集支撑了菲律宾历史档案的智能检索系统开发。博物馆与学术机构利用训练后的模型,能够快速定位特定军政人物在文献中的活动轨迹,辅助历史展览的策展工作。数字人文研究者藉此构建戒严时期的社会网络图谱,揭示权力结构的演变规律。
数据集最近研究
最新研究方向
在历史计算语言学领域,PHMartialLaw-NER_final数据集正推动菲律宾戒严时期历史文献的细粒度实体识别研究。该数据集通过标注个人、组织、时间等18类实体,为分析军政关系与媒体叙事提供了结构化基础。当前研究聚焦于跨领域命名实体识别模型的迁移学习,结合低资源语言处理技术,探索戒严时期权力结构的语义网络构建。随着数字人文研究热潮兴起,该数据集成为解构东南亚殖民历史记忆的关键语料,其标注框架已被应用于比较独裁政权话语分析,为历史事件因果推理提供可计算依据。
以上内容由遇见数据集搜集并总结生成


