COVID-19 X-ray Dataset
收藏github2024-08-01 更新2024-08-02 收录
下载链接:
https://github.com/ksmooi/mscs_dl_cnn_covid19_xray
下载链接
链接失效反馈官方服务:
资源简介:
该数据集用于区分正常和肺炎影响肺部,旨在通过放射学影像早期检测COVID-19。数据集包含188张JPEG格式的图像,分为训练集和测试集,每组包含NORMAL和PNEUMONIA两类图像。
This dataset is intended to distinguish between normal lungs and those affected by pneumonia, aiming to enable early detection of COVID-19 via radiological images. It contains 188 JPEG-formatted images, which are divided into training and test sets, with each set including images from two categories: NORMAL and PNEUMONIA.
创建时间:
2024-08-01
原始信息汇总
COVID-19 X-ray 数据集概述
数据描述
该数据集旨在区分正常和肺炎受影响的肺部,可能通过放射影像帮助早期检测 COVID-19。数据集分为训练集和测试集,每部分包含两类图像:NORMAL 和 PNEUMONIA。
文件夹结构和文件详情
数据集结构如下:
data/test/NORMAL data/test/PNEUMONIA data/train/NORMAL data/train/PNEUMONIA
文件摘要
| 文件夹 | 文件数量 | 文件格式 | 图像尺寸 |
|---|---|---|---|
| test/NORMAL | 20 | JPEG | (2244, 2030) |
| test/PNEUMONIA | 20 | JPEG | (1294, 1022) |
| train/NORMAL | 74 | JPEG | (1740, 1246) |
| train/PNEUMONIA | 74 | JPEG | (882, 876) |
| 总数据大小 | 85.24 MB |
类别摘要
| 类别 | 样本数量 | 平均尺寸 | 尺寸标准差 |
|---|---|---|---|
| Train Normal | 74 | [1539.7, 1968.1, 3.0] | [445.3, 337.95, 0.0] |
| Train Pneumonia | 74 | [1231.3, 1427.0, 3.0] | [842.95, 953.89, 0.0] |
| Test Normal | 20 | [1656.35, 2049.75, 3.0] | [323.63, 237.64, 0.0] |
| Test Pneumonia | 20 | [1536.65, 1605.7, 3.0] | [186.91, 229.14, 0.0] |
关键点
- 数据集总共包含 188 张图像,其中训练集有 148 张(74 张 NORMAL 和 74 张 PNEUMONIA),测试集有 40 张(20 张 NORMAL 和 20 张 PNEUMONIA)。
- 图像为 JPEG 格式,尺寸各异。
- 各类别的平均尺寸和标准差表明图像尺寸多样,需要在预处理时进行调整或归一化。
- 数据集大小为 85.24 MB,适合典型的机器学习和深度学习工作流程。
搜集汇总
数据集介绍
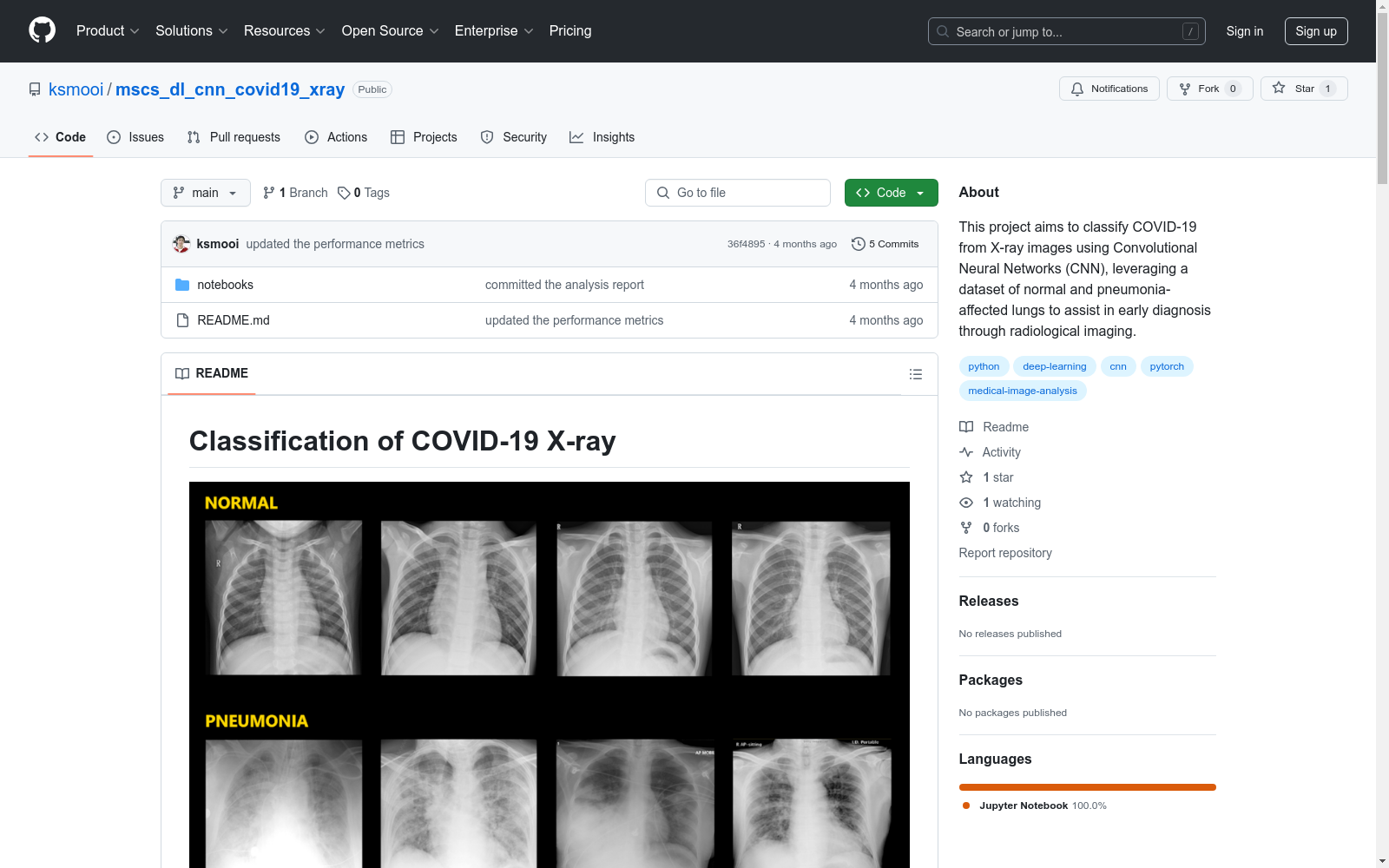
构建方式
在构建COVID-19 X-ray Dataset时,研究者精心设计了数据集的结构,以确保其适用于深度学习模型的训练与测试。数据集被划分为训练集和测试集,每个集合中包含NORMAL和PNEUMONIA两类图像。具体而言,训练集包含74张NORMAL图像和74张PNEUMONIA图像,而测试集则包含20张NORMAL图像和20张PNEUMONIA图像。图像格式为JPEG,尺寸多样,平均尺寸和标准差在不同类别中有所不同,这为模型提供了丰富的数据多样性。
特点
COVID-19 X-ray Dataset的主要特点在于其结构清晰且类别平衡,确保了模型训练的公平性和有效性。图像的多样性体现在尺寸和内容上,这有助于模型在不同条件下进行泛化。此外,数据集的大小适中,仅为85.24 MB,便于在各种计算环境中进行处理。通过详细的探索性数据分析,研究者确保了数据集的质量和适用性,为后续的模型训练提供了坚实的基础。
使用方法
使用COVID-19 X-ray Dataset时,用户首先需根据数据集的结构进行数据加载和预处理。由于图像尺寸多样,建议在预处理阶段进行尺寸统一或归一化处理。随后,用户可根据需求选择合适的卷积神经网络(CNN)架构进行模型训练。数据集的训练集和测试集划分明确,用户可直接用于模型的训练和验证。通过调整超参数和模型结构,用户可以进一步优化模型的性能,以实现对COVID-19的准确分类。
背景与挑战
背景概述
COVID-19 X-ray Dataset是在全球新冠疫情背景下,由研究人员和机构创建的一个专注于通过X光图像分类COVID-19的数据集。该数据集的创建旨在利用卷积神经网络(CNN)技术,辅助在疫情高峰期进行快速且准确的诊断。数据集包含了188张X光图像,分为正常和肺炎两类,分别用于训练和测试。这一数据集的开发不仅为医学影像分析提供了新的工具,也为深度学习在医疗领域的应用开辟了新的研究方向。
当前挑战
COVID-19 X-ray Dataset在构建和应用过程中面临多项挑战。首先,数据集的规模相对较小,仅包含188张图像,这可能导致模型在训练过程中出现过拟合现象。其次,图像的尺寸多样性较大,需要进行预处理以适应模型输入要求。此外,数据集的类别不平衡问题也是一个重要挑战,尽管在训练和测试集中每类图像数量相等,但在实际应用中可能面临更复杂的数据分布。最后,模型的泛化能力也是一个关键问题,特别是在面对不同来源和质量的X光图像时,模型的表现可能会有所不同。
常用场景
经典使用场景
在COVID-19大流行期间,COVID-19 X-ray Dataset被广泛用于通过卷积神经网络(CNN)对X光图像进行分类,以区分正常肺部和肺炎受影响的肺部。这一数据集的经典使用场景主要集中在利用深度学习技术辅助COVID-19的早期检测。通过训练和测试集中的图像数据,研究人员能够开发和优化CNN模型,以实现高精度的COVID-19分类。
衍生相关工作
基于COVID-19 X-ray Dataset,许多相关研究工作得以展开,包括但不限于改进CNN架构、优化超参数、引入数据增强技术等。此外,该数据集还激发了其他COVID-19相关数据集的创建和研究,如基于CT扫描的病毒检测工具和多模态数据融合方法,进一步推动了COVID-19诊断技术的进步。
数据集最近研究
最新研究方向
在COVID-19大流行背景下,COVID-19 X-ray Dataset的研究方向主要集中在利用卷积神经网络(CNN)进行X光图像的分类,以辅助早期诊断。前沿研究聚焦于优化模型架构,通过调整卷积层、全连接层和激活函数等参数,提升分类准确性。此外,数据增强技术和超参数优化也成为研究热点,旨在提高模型对不同图像尺寸和复杂度的适应性。这些研究不仅在医学影像分析领域具有重要意义,也为全球公共卫生危机提供了技术支持。
以上内容由遇见数据集搜集并总结生成


