pubmed-en-quality-annotations-7
收藏Hugging Face2024-12-12 更新2024-12-13 收录
下载链接:
https://huggingface.co/datasets/rntc/pubmed-en-quality-annotations-7
下载链接
链接失效反馈官方服务:
资源简介:
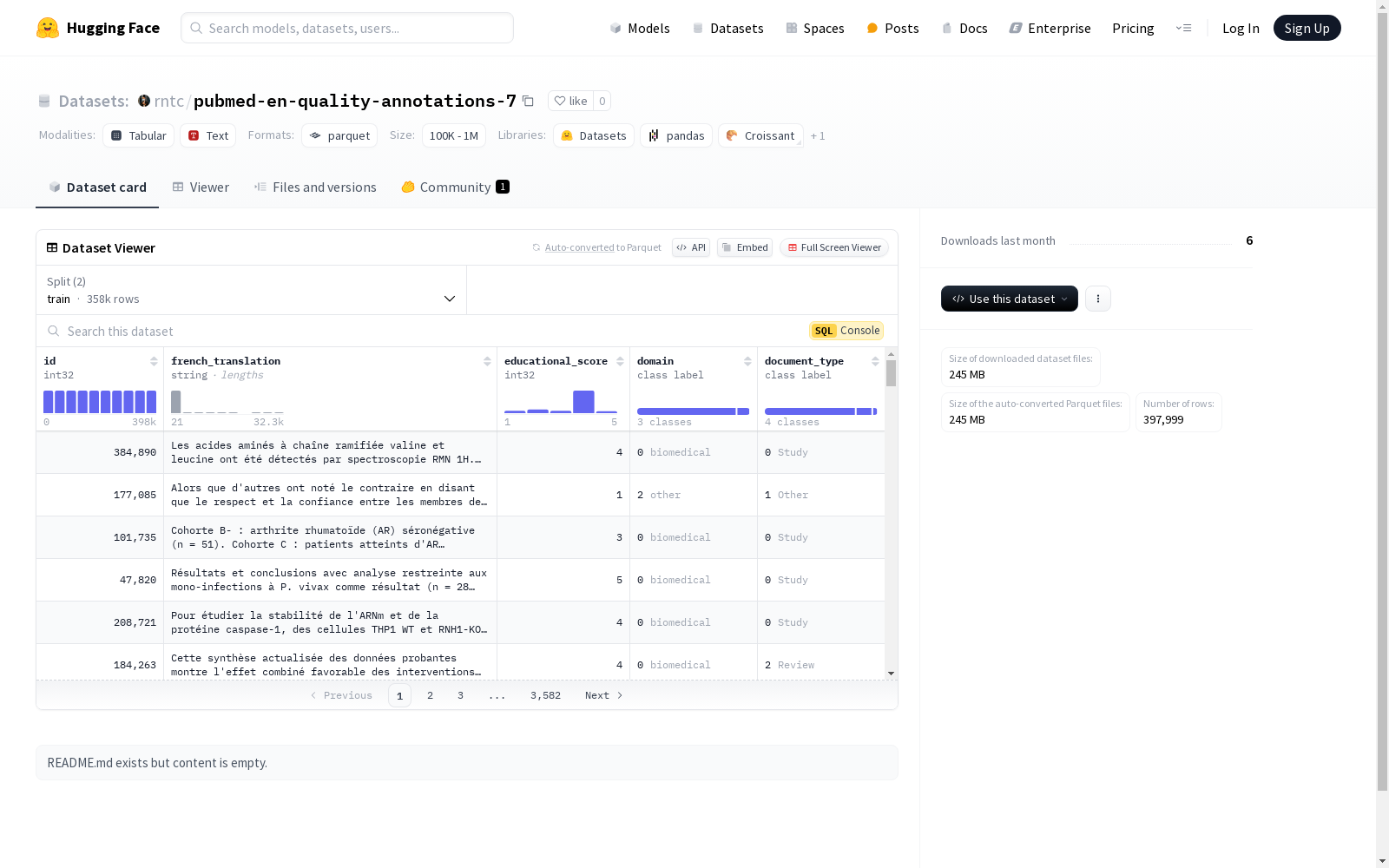
该数据集包含多个特征,如id、法语翻译、教育分数、领域和文档类型。领域和文档类型是分类变量,分别有三个和四个类别。数据集分为训练集和验证集,分别包含358199和39800个样本。数据集的总下载大小为245314153字节,总大小为438787962字节。
创建时间:
2024-12-12
原始信息汇总
数据集概述
数据集信息
- 特征:
- id: 数据类型为
int32。 - french_translation: 数据类型为
string。 - educational_score: 数据类型为
int32。 - domain: 数据类型为
class_label,包含以下类别:0: biomedical1: clinical2: other
- document_type: 数据类型为
class_label,包含以下类别:0: Study1: Other2: Review3: Clinical case
- id: 数据类型为
数据集划分
- train:
- 样本数量: 358199
- 数据大小: 394885209 字节
- validation:
- 样本数量: 39800
- 数据大小: 43902753 字节
数据集大小
- 下载大小: 245314153 字节
- 数据集总大小: 438787962 字节
配置
- config_name: default
- data_files:
- train: data/train-*
- validation: data/validation-*
搜集汇总
数据集介绍
构建方式
该数据集的构建基于对PubMed文献的深入分析,通过人工标注的方式,为每篇文献赋予了教育性评分(educational_score)和领域分类(domain)。此外,数据集还包含了文献的法语翻译(french_translation)以及文献类型(document_type)的分类信息。这些标注信息通过多层次的分类体系,确保了数据集在生物医学和临床领域的广泛适用性。
特点
该数据集的显著特点在于其多维度的标注体系,不仅涵盖了文献的教育性评分,还提供了文献的领域分类和类型分类。此外,数据集中的法语翻译为跨语言研究提供了便利,使得研究者能够在不同语言背景下进行深入分析。数据集的规模庞大,包含超过35万条训练样本和近4万条验证样本,为大规模模型训练提供了丰富的资源。
使用方法
该数据集适用于多种自然语言处理任务,如文本分类、情感分析和跨语言研究。研究者可以通过加载数据集的训练和验证集,利用其中的教育性评分、领域分类和文献类型信息进行模型训练和评估。此外,数据集中的法语翻译部分可用于跨语言模型的开发和测试,为多语言研究提供了宝贵的资源。
背景与挑战
背景概述
pubmed-en-quality-annotations-7数据集是由专业研究人员和机构创建,旨在评估和提升生物医学文献的质量。该数据集包含了大量来自PubMed数据库的文献,涵盖了多种文档类型,如研究、综述和临床案例等。通过引入教育评分和领域分类,该数据集为生物医学领域的文献质量评估提供了标准化的工具,对推动该领域的研究具有重要意义。
当前挑战
该数据集在构建过程中面临的主要挑战包括:首先,如何准确地对生物医学文献进行分类和评分,这需要高度专业化的知识和技能。其次,数据集的规模庞大,处理和标注这些数据需要大量的时间和资源。此外,确保数据集的多样性和代表性也是一个重要挑战,以避免偏见并提高评估的准确性。
常用场景
经典使用场景
在生物医学领域,pubmed-en-quality-annotations-7数据集被广泛用于评估和提升文献翻译质量。通过该数据集,研究者可以分析法语翻译文本的教育性评分,进而优化翻译模型,确保其在生物医学和临床领域的准确性和专业性。
解决学术问题
该数据集解决了生物医学文献翻译中的质量评估问题,特别是在多语言环境下如何保持专业术语的准确性。通过提供详细的翻译评分和领域分类,它为跨语言知识传递提供了可靠的评估工具,推动了多语言生物医学研究的进展。
衍生相关工作
基于pubmed-en-quality-annotations-7数据集,研究者们开发了多种翻译质量评估模型和工具,这些模型在多个国际翻译竞赛中表现优异。此外,该数据集还启发了对多语言生物医学文本处理的研究,推动了相关领域的技术进步和标准化。
以上内容由遇见数据集搜集并总结生成


