MTADataset
收藏Hugging Face2025-10-23 更新2025-10-24 收录
下载链接:
https://huggingface.co/datasets/huangjun12/MTADataset
下载链接
链接失效反馈官方服务:
资源简介:
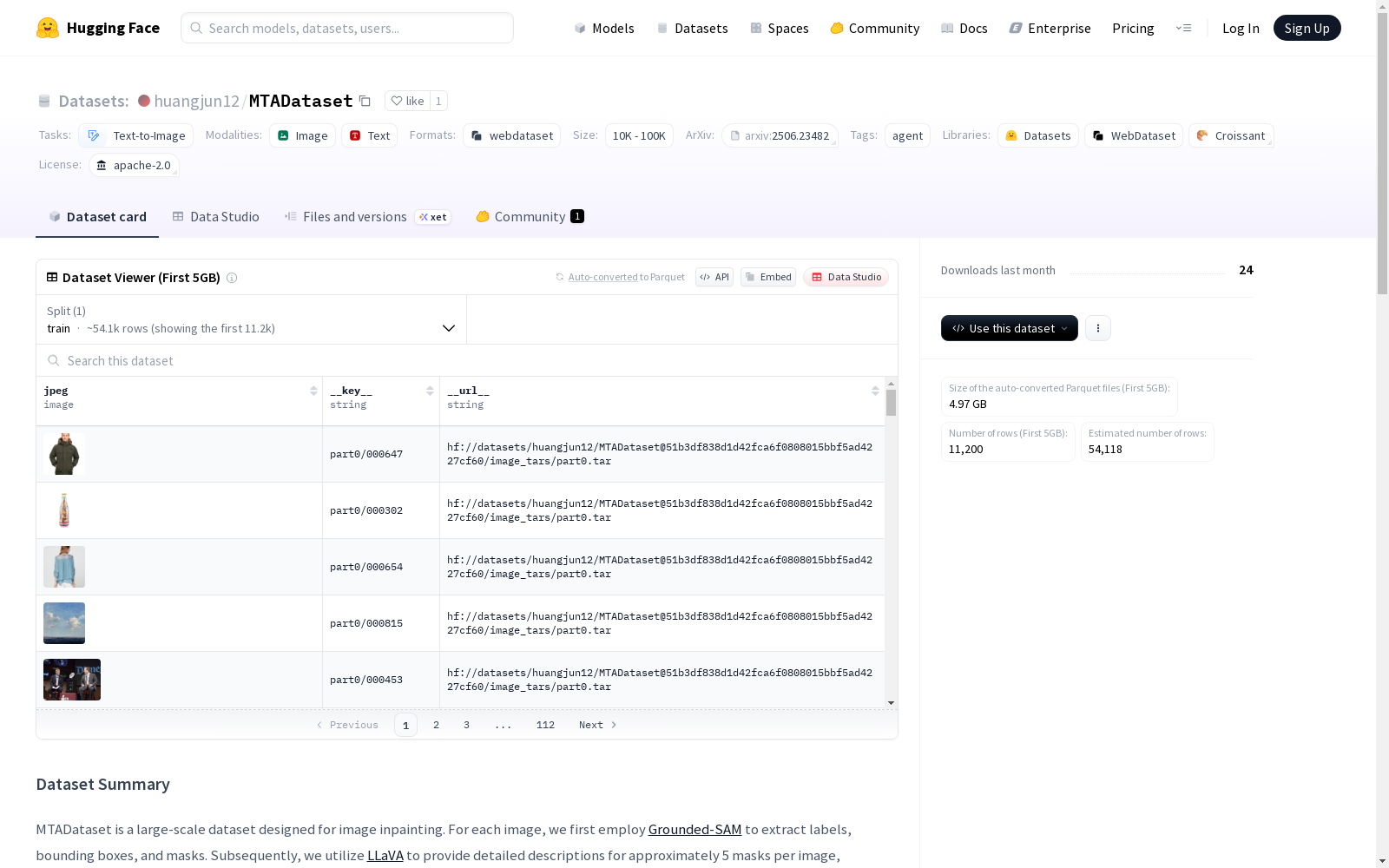
MTADataset 是一个为图像修复任务设计的大型数据集。对于每张图像,首先使用 Grounded-SAM 提取标签、边界框和掩码,然后使用 LLaVA 为每个图像中的大约 5 个掩码提供详细的描述,包括它们的内容和风格。
创建时间:
2025-10-22
原始信息汇总
MTADataset 数据集概述
数据集基本信息
- 许可证:Apache-2.0
- 任务类别:文本到图像
- 数据规模:10K-100K
- 标签:智能体
数据集简介
MTADataset是一个专为图像修复设计的大规模数据集。该数据集通过以下流程构建:
- 使用Grounded-SAM提取标签、边界框和掩码
- 使用LLaVA为每张图像中约5个掩码提供详细描述,包括内容和风格信息
技术细节
数据处理流程
- 图像处理:读取图像文件
- 掩码处理:解码RLE格式掩码,提取边界框信息
- 文本描述:读取LLaVA生成的掩码描述
数据结构
数据集包含以下关键文件:
- 图像文件
- JSONL格式的主数据文件(mta_dataset.jsonl)
- 掩码描述文件
- LLaVA生成的文本描述文件
相关论文
- 论文标题:MTADiffusion: Mask Text Alignment Diffusion Model for Object Inpainting
- 会议:CVPR 2025
- 论文链接:https://arxiv.org/abs/2506.23482
引用格式
bibtex @InProceedings{Huang_2025_CVPR, author = {Huang, Jun and Liu, Ting and Wu, Yihang and Qu, Xiaochao and Liu, Luoqi and Hu, Xiaolin}, title = {MTADiffusion: Mask Text Alignment Diffusion Model for Object Inpainting}, booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)}, month = {June}, year = {2025}, pages = {18325-18334} }
搜集汇总
数据集介绍
构建方式
在计算机视觉领域的图像修复任务中,MTADataset的构建采用了系统化的多模态数据处理流程。该数据集通过Grounded-SAM模型对原始图像进行语义解析,自动提取物体标签、边界框及掩码信息,为每个图像建立结构化标注。随后运用LLaVA视觉语言模型对每张图像中约五个掩码区域生成精细化描述,涵盖物体内容特征与风格属性,最终形成包含图像、掩码与文本描述的对齐数据。
特点
作为面向图像修复的大规模数据集,MTADataset具备显著的多模态协同特性。其核心优势在于实现了掩码区域与文本描述的精准对齐,每个掩码均配备由视觉语言模型生成的细节描述,有效弥合了视觉信息与语义表达之间的鸿沟。数据集规模介于数万至十万样本量级,涵盖多样化的物体类别与场景类型,为深度学习模型提供丰富的训练素材。
使用方法
基于该数据集的特性,使用者可通过标准化流程加载多模态数据。具体操作包括读取JSONL格式的元数据文件,解析其中存储的图像路径、掩码文件及文本描述路径。掩码数据采用RLE编码格式存储,需通过专用解码函数还原为二维矩阵。在模型训练过程中,可随机选择特定掩码区域,结合对应的LLaVA生成描述,构建图像修复任务的训练样本。
背景与挑战
背景概述
图像修复作为计算机视觉领域的关键研究方向,致力于通过智能算法重构图像中被遮挡或损坏的区域。MTADataset作为2025年发布的大规模数据集,由研究团队在CVPR会议上正式提出,其核心目标在于解决基于文本引导的对象级图像修复问题。该数据集通过融合Grounded-SAM的实例分割能力与LLaVA的多模态理解技术,构建了包含对象掩码、边界框及语义描述的完整标注体系,为生成式模型在视觉内容编辑领域的发展提供了重要支撑。
当前挑战
在对象级图像修复任务中,模型需同时处理掩码区域的几何约束与文本描述的语义一致性,这对生成内容的视觉合理性与上下文连贯性提出双重挑战。数据集构建过程中,研究团队面临多模态数据对齐的复杂性:一方面需通过Grounded-SAM确保对象掩码的精确提取,另一方面需借助LLaVA生成与视觉内容高度契合的文本描述,这种跨模态协同标注的流程对算法精度与计算资源均提出较高要求。
常用场景
经典使用场景
在计算机视觉领域,图像修复技术致力于恢复图像中被遮挡或损坏的区域。MTADataset通过结合Grounded-SAM和LLaVA技术,为每个图像提供精确的掩码和详细描述,成为训练扩散模型进行对象级修复的经典基准。研究者利用其对齐的掩码文本对,能够有效指导模型生成与上下文协调的视觉内容,显著提升了复杂场景下的修复质量。
实际应用
在实际应用层面,该数据集支撑的技术已广泛应用于影视后期制作、文物数字化修复和电子商务图像处理等领域。例如在影视工业中,可快速移除画面中的穿帮物体;在数字文物保护中,能精准复原破损的壁画细节;这些应用显著提升了视觉内容生产的效率与质量。
衍生相关工作
基于该数据集衍生的经典工作包括MTADiffusion框架,该模型通过跨模态对齐机制实现了精准的对象修复。后续研究在此基础上发展了动态掩码生成、多尺度修复等创新方法,这些成果在CVPR等顶级会议中形成了系列重要论文,持续推动着图像生成技术的前沿发展。
以上内容由遇见数据集搜集并总结生成


