MolmoAct Dataset
收藏arXiv2025-08-11 更新2025-08-13 收录
下载链接:
https://huggingface.co/datasets/allenai/MolmoAct-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
MolmoAct数据集是一个包含超过10,000条高质量机器人轨迹的中期训练数据集,涵盖了多样化的场景和任务。该数据集用于训练MolmoAct模型,使其在模拟和现实世界中均表现出色,包括在SimplerEnv视觉匹配任务上达到70.5%的零样本准确率,以及在LIBERO上实现86.6%的平均成功率。该数据集的发布为机器人操作领域提供了重要的训练资源,有助于提升模型的泛化能力和执行效率。
The MolmoAct dataset is a mid-stage training dataset containing over 10,000 high-quality robotic trajectories, covering diverse scenarios and tasks. It is utilized to train the MolmoAct model, enabling it to deliver outstanding performance across both simulation and real-world environments, achieving a 70.5% zero-shot accuracy on the SimplerEnv visual matching task and an 86.6% average success rate on LIBERO. The release of this dataset provides a critical training resource for the field of robotic manipulation, helping to improve the generalization ability and execution efficiency of models.
提供机构:
艾伦人工智能研究所,华盛顿大学
创建时间:
2025-08-11
原始信息汇总
MolmoAct-Dataset 数据集概述
数据集基本信息
- 许可证: CC BY-4.0
- 任务类别: 机器人学 (robotics)
数据集描述
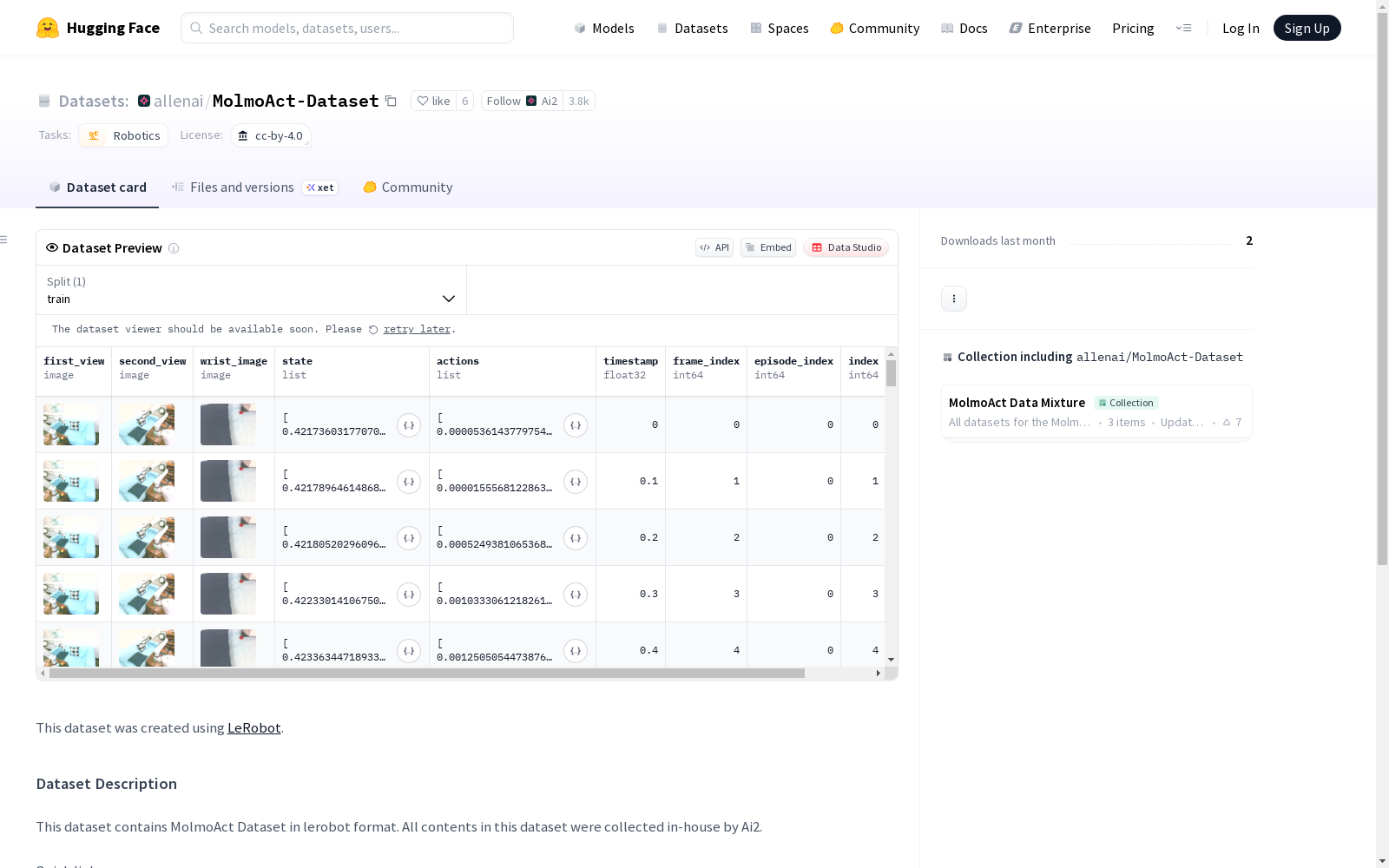
- 该数据集以 LeRobot 格式存储 MolmoAct 数据集。
- 所有数据内容均由 Ai2 内部收集。
相关资源
- 所有模型: https://huggingface.co/collections/allenai/molmoact-689697591a3936fba38174d7
- 所有数据: https://huggingface.co/collections/allenai/molmoact-data-mixture-6897e583e13b6c2cf3ea2b80
- 论文: https://huggingface.co/allenai/MolmoAct-7B-D-0812/blob/main/MolmoAct_Technical_Report.pdf
- 博客文章: https://allenai.org/blog/molmoact
- 视频: https://youtu.be/-_wag1X25OE?si=Xi_kUaJTmcQBx1f6
许可与使用
- 该数据集遵循 CC BY-4.0 许可协议。
- 旨在用于研究和教育目的,并符合 Ai2 负责任使用指南。
搜集汇总
数据集介绍
构建方式
MolmoAct数据集的构建过程体现了多模态与机器人技术的深度融合。该数据集通过专业团队历时两个月的严格采集,整合了单臂Franka机器人在家庭与桌面环境中的10,689条高质量轨迹数据,覆盖93种独特操作任务。构建过程中采用双阶段标注策略:首先利用深度估计专家模型生成场景的2.5D感知标记,再通过视觉语言模型Molmo预测机器人末端执行器的轨迹坐标,形成空间推理链。这种结构化标注方法将每帧观测数据转化为包含深度感知标记、视觉推理轨迹和动作指令的三元组序列,实现了感知-规划-执行的全链条数据表征。
特点
MolmoAct数据集的核心价值在于其空间推理的显式建模能力。区别于传统机器人数据集直接映射视觉指令到动作的模式,该数据集通过深度感知标记(100个离散化深度标记/帧)和2D轨迹多段线(1-5个归一化坐标点)构建了可解释的中间表征。数据分布呈现长尾特性,涵盖从基础抓取到复杂家务场景的连续技能谱系,其中家庭环境数据占比72.3%(7,730条轨迹),包含20类动词描述的73项任务。特别值得注意的是其双重视角配置——侧视摄像头与腕部摄像头同步采集,为多视角空间推理提供了独特的数据基础。
使用方法
该数据集的使用需遵循其分层推理架构:首先解码深度感知标记重建场景三维理解,其次解析视觉轨迹标记生成二维运动规划,最终输出机器人控制指令。研究人员可通过两种典型范式利用该数据:1)端到端训练视觉-语言-动作模型时,数据的三阶段标记自然形成链式监督信号;2)针对性微调时,可单独使用深度标记或轨迹标记提升特定模块性能。数据集特别支持交互式应用场景,用户可通过编辑轨迹多段线直接调整模型的空间推理结果,这种基于视觉的导引方式相比语言指令具有更高的操作精度和泛化性。
背景与挑战
背景概述
MolmoAct数据集由Allen Institute for AI和华盛顿大学的研究团队于2025年发布,旨在推动机器人操作中的空间推理能力。该数据集包含超过10,000条高质量机器人轨迹,覆盖多样化场景和任务,主要应用于视觉-语言-动作(VLA)模型的研究。MolmoAct通过深度感知令牌、视觉推理轨迹和动作预测的三阶段结构化推理架构,显著提升了机器人在仿真和现实环境中的适应性和可解释性。其影响力体现在多个基准测试中的优异表现,如SimperEnv和LIBERO,为机器人基础模型的开发提供了开放蓝图。
当前挑战
MolmoAct数据集面临的挑战主要包括两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,机器人操作需要精确的空间理解和复杂的动作规划,传统方法难以实现高效的泛化和语义 grounding。构建过程中的挑战包括数据收集的高成本和多模态数据的对齐问题,尤其是在处理深度感知和视觉推理轨迹时,需要确保数据的高质量和一致性。此外,如何在大规模数据上保持模型的解释性和可操作性也是一个重要挑战。
常用场景
经典使用场景
MolmoAct数据集在机器人视觉-语言-动作(VLA)模型的研究中具有重要应用。该数据集通过提供高质量的机器人轨迹数据,支持模型在感知、规划和控制的各个阶段进行深度推理。经典使用场景包括机器人视觉匹配任务、长时程任务规划以及开放指令跟随任务。例如,在LIBERO和SimplerEnv等标准基准测试中,MolmoAct数据集被广泛用于评估模型的空间推理能力和动作预测精度。
解决学术问题
MolmoAct数据集解决了机器人领域中多个关键学术问题。首先,它通过提供结构化推理链(深度感知令牌、视觉推理轨迹和动作令牌),显著提升了模型的解释性和可操作性。其次,该数据集弥补了传统VLA模型在3D空间理解和动作规划方面的不足,使得模型能够更精确地预测和控制机器人动作。此外,MolmoAct数据集还支持模型在零样本和微调场景下的高效泛化,为机器人基础模型的开发提供了重要支持。
衍生相关工作
MolmoAct数据集衍生了一系列相关研究工作,包括TraceVLA、CoT-VLA和ThinkAct等。这些工作进一步扩展了视觉-语言-动作模型的应用范围,尤其是在空间推理和动作规划方面。例如,TraceVLA利用MolmoAct数据集中的视觉推理轨迹功能,提升了模型在复杂任务中的表现。ThinkAct则通过结合强化学习,进一步优化了模型的长期任务规划能力。这些衍生工作共同推动了机器人基础模型的发展,为未来的研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


