AvaMERG
收藏arXiv2025-02-07 更新2025-02-11 收录
下载链接:
https://AvaMERG.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
AvaMERG数据集是由西安电子科技大学等机构的研究人员构建的大规模高质量基准数据集,旨在推动多模态情感响应生成任务的研究。该数据集在现有的纯文本情感对话数据集的基础上进行了扩展,包含了真实的语音音频和动态对话头像视频,覆盖了不同年龄、性别、语音语调、情感表现和种族的多样化对话场景,为多模态情感对话研究提供了坚实的基础。
The AvaMERG dataset is a large-scale high-quality benchmark dataset developed by researchers from Xidian University and other institutions, with the goal of advancing research on multimodal emotional response generation tasks. Expanded based on existing purely textual emotional dialogue datasets, it contains real speech audio and dynamic conversational avatar videos, covering diverse dialogue scenarios with varied age, gender, speech intonation, emotional expression, and ethnicity, thereby providing a solid foundation for multimodal emotional dialogue research.
提供机构:
西安电子科技大学
创建时间:
2025-02-07
搜集汇总
数据集介绍
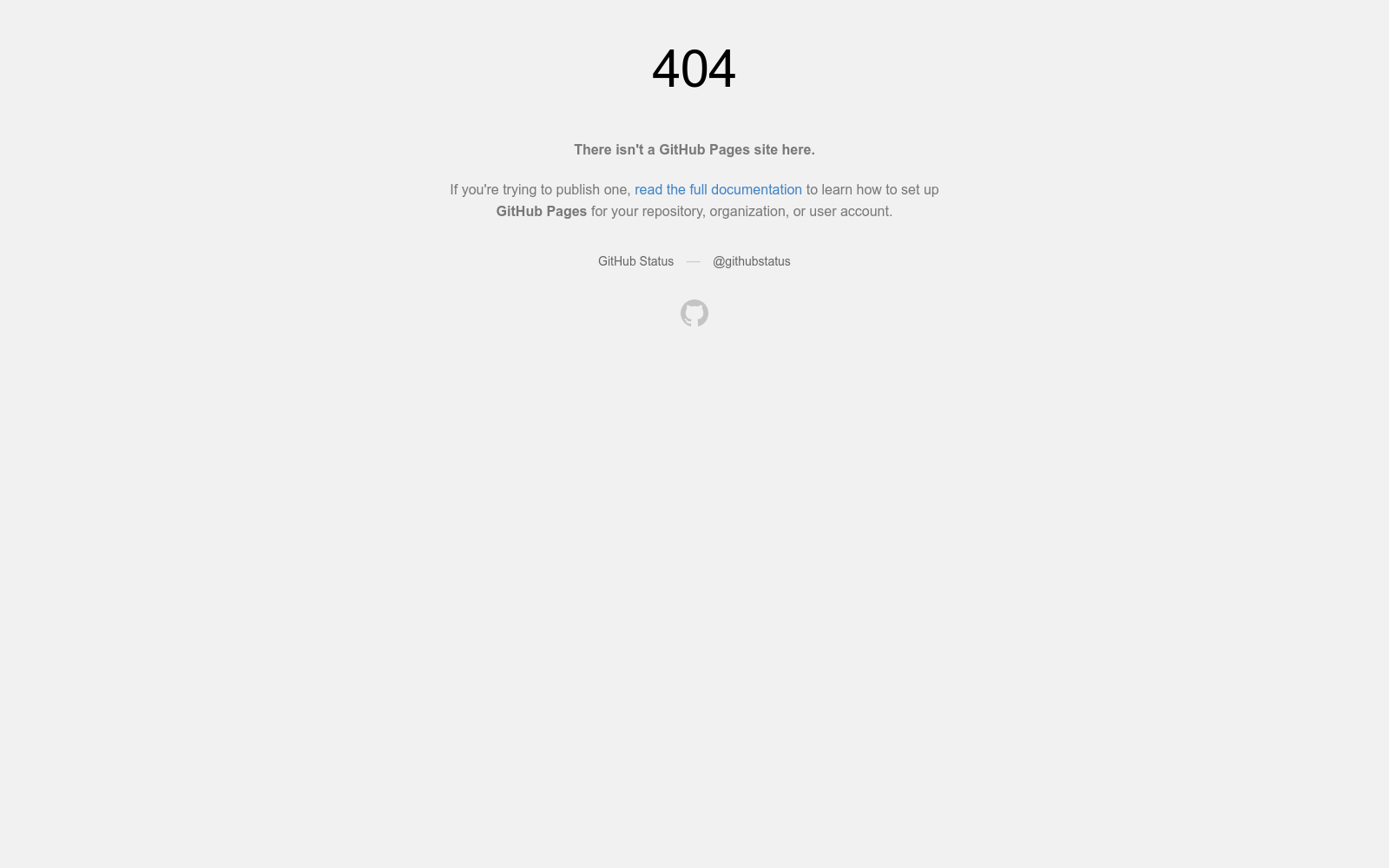
构建方式
AvaMERG数据集的构建方式首先是在现有的文本ERG基准数据集的基础上进行扩充,加入了真实的人声语音和动态的说话人脸头像视频。具体来说,对于对话中的每一轮发言,都提供了对应的真实人声朗读语音和动态说话人脸头像视频(2D面部建模),这些视频都与预期的情绪相符。数据集包含了各种不同的头像资料,涵盖了现实世界场景中的各种主题,包括不同的年龄组、性别、语调和外貌。为了确保标注的高质量,进行了精细的手动验证,保证了头像的语音和视频在情感上的准确性和一致性。
特点
AvaMERG数据集的特点包括:大规模和高质量,包含了33,048个对话和152,021个发言;多模态对话,涵盖了文本、语音和头像视频三个模态;头像资料多样性,涵盖了4个不同的年龄组,每个年龄组都有男性和女性,以及3种不同的语调;情感多样性,包含了7种常见的情绪;广泛的主题覆盖,涵盖了10个主要主题和数百个子主题。
使用方法
AvaMERG数据集的使用方法主要包括:作为多模态ERG任务的训练数据,用于训练和评估多模态ERG模型;作为研究多模态情感理解和生成的基础数据集,用于研究和开发新的多模态情感理解和生成技术;作为情感计算领域的参考数据集,用于研究和开发情感计算领域的各种应用。
背景与挑战
背景概述
AvaMERG 数据集是针对多模态共情响应生成(Multimodal Empathetic Response Generation,MERG)任务构建的一个大规模、高质量的基准数据集。该数据集由张瀚、孟子翔、罗梦、韩红、廖丽芝、坎布里亚·埃里克和费浩等研究人员于 2025 年创建,旨在解决现有共情响应生成研究主要局限于单一文本模态的问题。AvaMERG 数据集融合了真实的人类语音音频和动态的说话人脸头像视频,涵盖了多样化的头像特征和广泛的真实世界场景话题,为多模态共情对话研究提供了坚实的基础。该数据集的创建填补了多模态共情响应生成研究的空白,对相关领域产生了重要影响。
当前挑战
AvaMERG 数据集面临的挑战主要包括:1) 所解决的领域问题,即如何生成情感丰富且富有同情心的多模态响应,以更好地理解和模拟人类的情感表达;2) 构建过程中所遇到的挑战,如确保多模态信号(文本、音频、视频)之间的情感准确性、同步性和一致性,以及克服模块间交互不足的问题。此外,还需要解决离散方法导致的生成内容质量下降的问题,并开发高效的训练策略来增强模型的情感准确性和内容/头像一致性。
常用场景
经典使用场景
AvaMERG数据集被设计用于多模态共情响应生成(MERG)任务,旨在生成具有情感细微差别和同情心的响应。该数据集最经典的使用场景包括心理治疗、陪伴机器人、电子个人助理等,在这些场景中,系统需要接受多模态信号输入(如文本、语音和面部视频)并生成多模态的共情响应。例如,在心理治疗中,系统可以分析患者的语音语调和面部表情,并生成相应的共情文本和视频响应,以提供更人性化的支持和安慰。
衍生相关工作
AvaMERG数据集衍生了许多相关的经典工作,包括但不限于多模态大语言模型(MLLM)、语音和头像生成器、共情推理机制等。这些工作不仅提高了ERG任务的性能,还为多模态情感理解和生成提供了新的研究方向。例如,基于AvaMERG数据集的多模态大语言模型(MLLM)可以更准确地生成具有情感细微差别和同情心的文本响应,而语音和头像生成器可以生成更自然和真实的语音和视频响应。此外,共情推理机制可以帮助系统更好地理解用户的情感需求,并提供更贴心的服务和个性化支持。
数据集最近研究
最新研究方向
随着人工智能领域的不断发展,情感计算已成为研究的热点之一。情感计算的核心任务之一是同情心响应生成(ERG),旨在为用户的查询生成充满情感色彩和同情心的回应。然而,现有的ERG研究主要集中在单一文本模态,限制了其有效性,因为人类的情感本质上是通过多种模态来传达的。为了克服这个问题,我们提出了一个基于虚拟形象的跨模态ERG(MERG)任务,包括丰富的文本、语音和面部视觉信息。我们首先提出一个大规模高质量的数据集AvaMERG,它通过整合真实的语音音频和动态的虚拟形象视频扩展了传统的文本ERG,涵盖了各种虚拟形象配置文件,并广泛涵盖了各种现实场景的话题。此外,我们还特别设计了一个名为Empatheia的系统,用于MERG。Empatheia基于一个多模态大型语言模型(MLLM),具有多模态编码器、语音生成器和虚拟形象生成器,执行端到端的MERG,并集成了Chain-of-Empathetic推理机制,以增强同情心理解和推理。最后,我们设计了一系列同情心增强的调整策略,增强了情感准确性和内容,以及跨模态的虚拟形象配置文件一致性。在AvaMERG数据上的实验结果表明,Empatheia在文本ERG和MERG上都始终优于基线方法。所有数据和代码都是开放的,可以在https://AvaMERG.github.io/上找到。
相关研究论文
- 1Towards Multimodal Empathetic Response Generation: A Rich Text-Speech-Vision Avatar-based Benchmark西安电子科技大学 · 2025年
以上内容由遇见数据集搜集并总结生成


