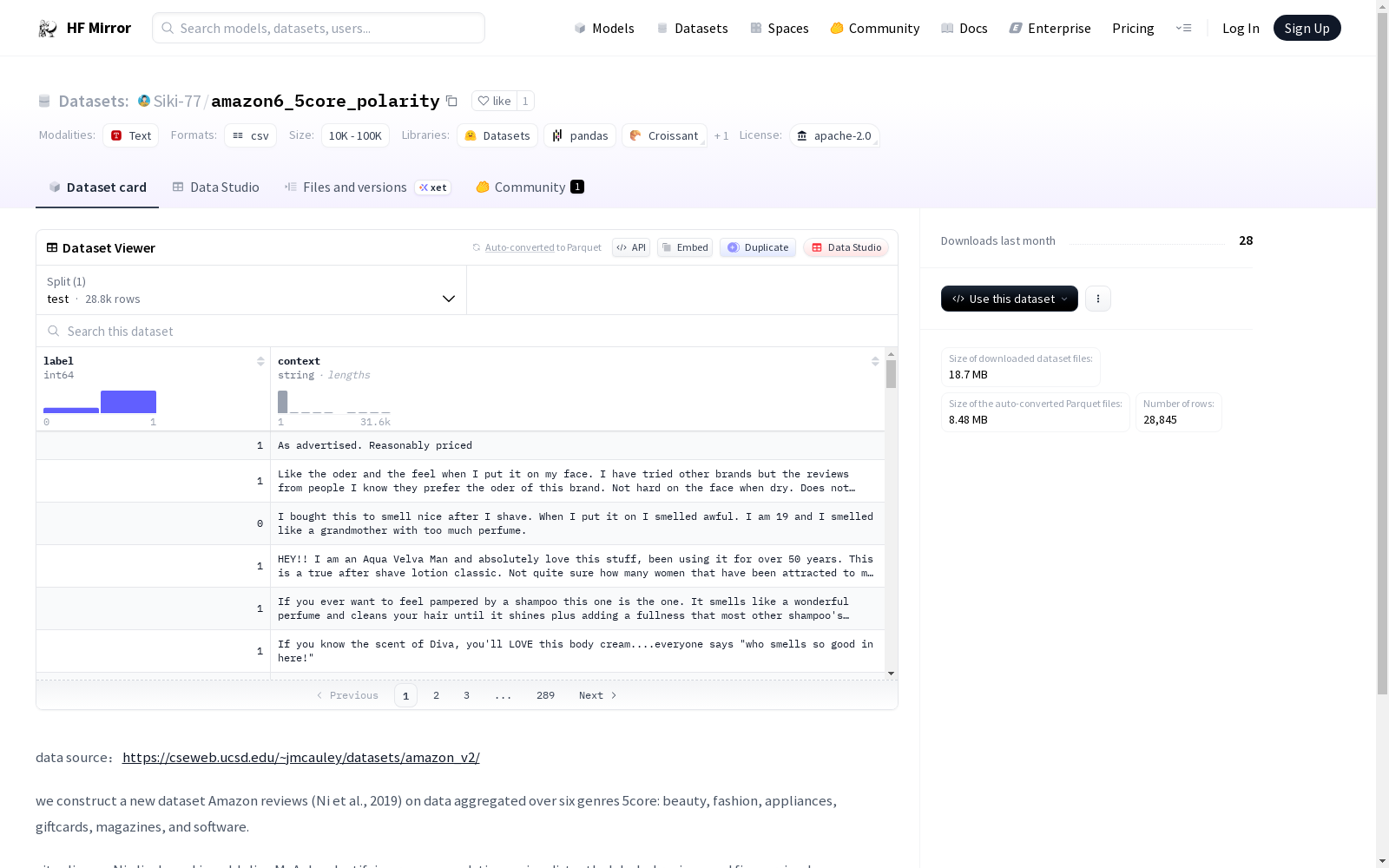
Siki-77/amazon6_5core_polarity
收藏Hugging Face2023-11-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Siki-77/amazon6_5core_polarity
下载链接
链接失效反馈资源简介:
---
license: apache-2.0
---
data source:https://cseweb.ucsd.edu/~jmcauley/datasets/amazon_v2/
we construct a new dataset Amazon reviews (Ni et al., 2019) on data aggregated over six genres 5core: beauty, fashion, appliances, giftcards, magazines, and software.
cite:
Jianmo Ni, Jiacheng Li, and Julian McAuley. Justifying recommendations using distantly-labeled
reviews and fine-grained aspects. In Empirical Methods in Natural Language Processing and
International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019. URL
https://www.aclweb.org/anthology/D19-1018.
提供机构:
Siki-77
原始信息汇总
数据集概述
数据来源
- 数据集来源于六个不同类别的亚马逊评论,包括:美容、时尚、家电、礼品卡、杂志和软件。
数据集构建
- 该数据集是由Ni et al. (2019)构建的,基于六个类别的5核心数据。
引用信息
- 引用该数据集时,请参考以下文献:
- 作者:Jianmo Ni, Jiacheng Li, Julian McAuley
- 标题:Justifying recommendations using distantly-labeled reviews and fine-grained aspects
- 会议:Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP)
- 年份:2019
- URL:https://www.aclweb.org/anthology/D19-1018
AI搜集汇总
数据集介绍
构建方式
在电子商务领域,用户评论数据对于理解消费者偏好至关重要。该数据集基于Ni等人(2019)的研究,从亚马逊平台聚合了六个特定品类的评论信息,包括美容、时尚、家电、礼品卡、杂志和软件。构建过程中,采用了5-core过滤策略,确保每个用户和商品至少拥有五条评论,从而提升了数据的密度和代表性。数据来源于公开的亚马逊评论数据集,经过精心筛选和整理,形成了结构化的极性分析资源。
特点
该数据集聚焦于多品类评论的极性分析,涵盖了从日常消费品到数字产品的广泛领域。其核心特点在于每个品类均经过5-core处理,保证了用户与商品交互的充分性,减少了数据稀疏性问题。数据以极性标签形式呈现,便于情感分类和推荐系统研究,同时支持跨品类的比较分析。这种细粒度的设计为自然语言处理任务提供了丰富而可靠的实验基础。
使用方法
在自然语言处理研究中,该数据集适用于情感分析、推荐系统优化等任务。使用者可直接加载数据,进行文本预处理和特征提取,以训练分类模型或评估算法性能。建议结合极性标签,探索用户评论的情感分布及其与商品类别的关系。数据格式清晰,便于集成到现有机器学习流程中,为电商领域的学术和工业应用提供实证支持。
背景与挑战
背景概述
在自然语言处理领域,情感分析作为文本挖掘的重要分支,其研究依赖于高质量、大规模标注数据的支撑。亚马逊评论数据集Amazon reviews由Jianmo Ni、Jiacheng Li和Julian McAuley等研究人员于2019年构建,旨在通过聚合六个核心类别——美容、时尚、家电、礼品卡、杂志和软件——的评论数据,探索细粒度方面的推荐理由生成问题。该数据集不仅为情感分类和推荐系统提供了丰富的语料资源,还推动了基于远程监督的文本分析方法的发展,对电子商务和用户行为研究产生了深远影响。
当前挑战
该数据集所针对的情感分析与推荐理由生成任务,面临文本语义多样性、领域适应性以及细粒度方面提取的复杂性等挑战。在构建过程中,研究人员需处理原始评论数据的噪声过滤、跨类别数据的一致性整合,以及通过远程标注确保标签质量的可靠性,这些因素共同构成了数据集构建的技术难点。
常用场景
经典使用场景
在自然语言处理领域,Amazon6_5core_polarity数据集常被用于情感分析任务,特别是针对多领域商品评论的极性分类。该数据集整合了美容、时尚、家电、礼品卡、杂志和软件六个类别的亚马逊评论,每个类别均经过5-core过滤,确保了数据的稠密性和代表性。研究者利用该数据集训练和评估模型,以探索跨领域情感分类的泛化能力,为推荐系统提供细粒度的情感依据。
实际应用
在实际应用中,Amazon6_5core_polarity数据集被广泛用于电商平台的智能推荐系统。企业利用该数据集训练情感分析模型,自动识别用户评论中的积极或消极情感,从而优化产品推荐策略。例如,在美容和时尚领域,模型可以分析用户反馈,调整库存或营销活动;在软件和家电领域,则有助于快速识别产品缺陷,提升客户服务质量,实现数据驱动的商业决策。
衍生相关工作
基于该数据集,衍生了一系列经典研究工作,如Ni等人(2019)提出的利用远距离标签评论进行推荐理由生成的方法。后续研究扩展了其在多任务学习中的应用,例如结合情感分析与方面级挖掘,以提升推荐系统的解释性。这些工作推动了细粒度情感分析模型的创新,为跨领域自然语言处理任务提供了新的基准,促进了学术与工业界的合作发展。
以上内容由AI搜集并总结生成


