Hybrid Fake Face Dataset
收藏github2024-04-19 更新2024-05-31 收录
下载链接:
https://github.com/EricGzq/Generative-fake-face-dataset
下载链接
链接失效反馈官方服务:
资源简介:
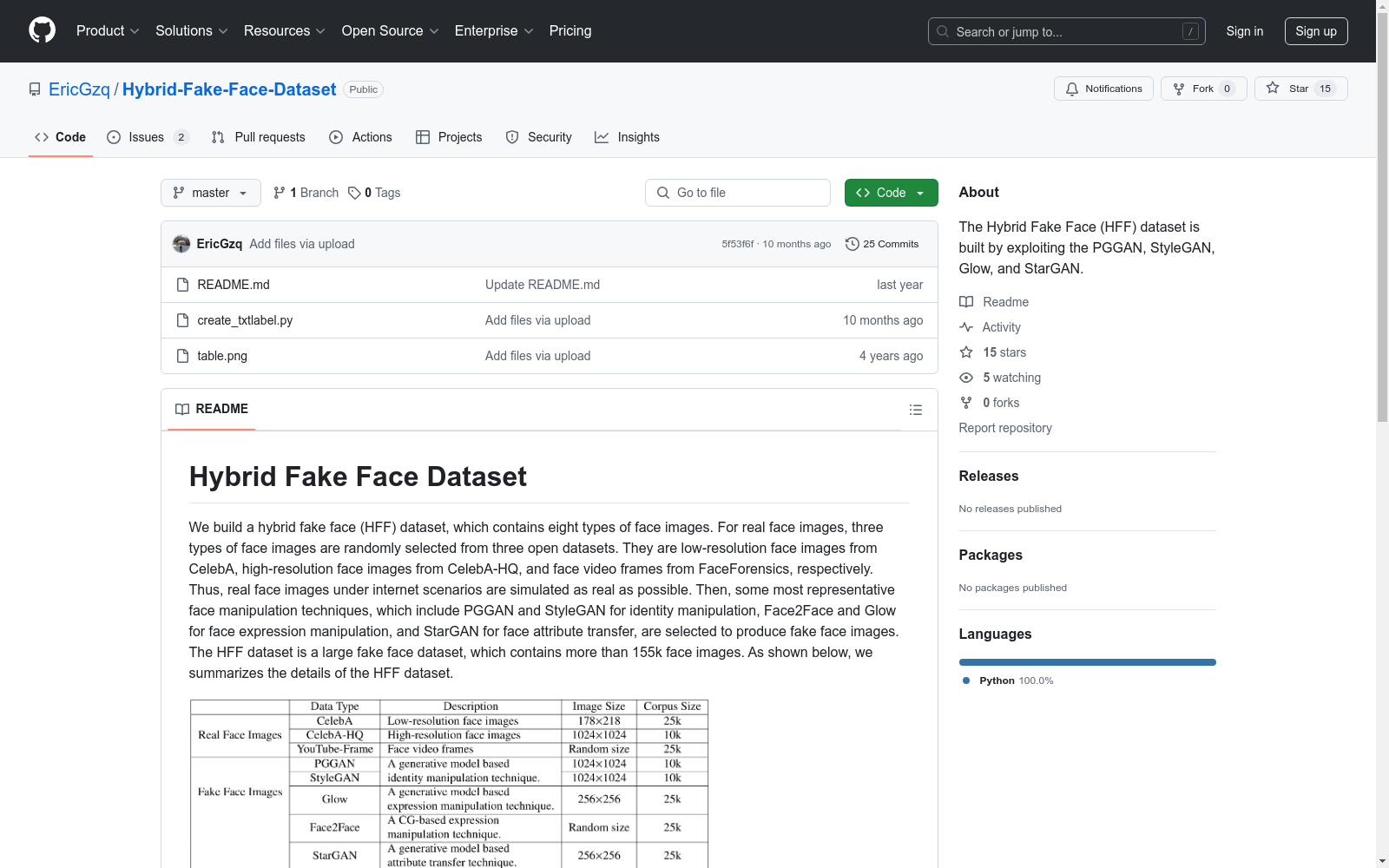
我们构建了一个混合假脸(HFF)数据集,包含八种类型的脸部图像。真实脸部图像从三个开放数据集中随机选择,包括CelebA的低分辨率脸部图像、CelebA-HQ的高分辨率脸部图像以及FaceForensics的脸部视频帧。此外,还使用了PGGAN、StyleGAN、Glow和StarGAN等技术生成了假脸图像。HFF数据集是一个大型假脸数据集,包含超过155,000张脸部图像。
We have constructed a Hybrid Fake Face (HFF) dataset, encompassing eight types of facial images. Authentic facial images were randomly selected from three open datasets, including low-resolution facial images from CelebA, high-resolution facial images from CelebA-HQ, and video frames from FaceForensics. Additionally, fake facial images were generated using technologies such as PGGAN, StyleGAN, Glow, and StarGAN. The HFF dataset is a large-scale fake face dataset, containing over 155,000 facial images.
创建时间:
2019-07-30
原始信息汇总
Hybrid Fake Face Dataset 概述
数据集内容
- 类型: 混合假脸数据集(HFF)
- 包含内容:
- 真实人脸图像:
- 低分辨率图像来自 CelebA
- 高分辨率图像来自 CelebA-HQ
- 视频帧来自 FaceForensics
- 假人脸图像:
- 身份操纵: PGGAN 和 StyleGAN
- 面部表情操纵: Face2Face 和 Glow
- 面部属性转移: StarGAN
- 真实人脸图像:
- 规模: 超过 155,000 张人脸图像
使用条款
- 仅限非商业研究及教育目的使用。
- 研究者需对数据集的使用负全责,保护数据提供者免受任何因使用数据集而产生的索赔。
- 允许在他人接受使用条款的前提下分享数据集。
- 数据提供方保留随时终止研究者访问数据集的权利。
下载流程
- 同意使用条款后,需通过电子邮件回答相关问题并发送至 guozhiqing@xju.edu.cn 以获取下载权限。
引用信息
-
如在研究中使用此数据集,请引用以下文献:
@article{AMTEN, title={Fake face detection via adaptive manipulation traces extraction network}, author={Guo, Zhiqing and Yang, Gaobo and Chen, Jiyou and Sun, Xingming}, journal={Computer Vision and Image Understanding}, volume={204}, pages={103170}, year={2021}, publisher={Elsevier} }
搜集汇总
数据集介绍
构建方式
在构建Hybrid Fake Face Dataset时,研究者们精心设计了一种混合方法,以确保数据集的真实性和多样性。首先,从三个公开数据集中随机选取了三种类型的真实人脸图像:CelebA中的低分辨率图像、CelebA-HQ中的高分辨率图像以及FaceForensics中的人脸视频帧。这些图像共同模拟了互联网场景下的真实人脸。随后,研究者们采用了多种先进的面部操作技术生成假脸图像,包括用于身份操作的PGGAN和StyleGAN、用于表情操作的Face2Face和Glow,以及用于属性转换的StarGAN。通过这些技术,数据集成功地包含了超过155,000张人脸图像,涵盖了多种操作类型。
特点
Hybrid Fake Face Dataset的显著特点在于其高度的多样性和真实性。数据集不仅包含了从不同来源获取的真实人脸图像,还通过多种先进的生成对抗网络(GAN)技术生成了多样化的假脸图像。这种多样性使得数据集在检测面部操作和伪造方面具有极高的应用价值。此外,数据集的规模庞大,包含了超过155,000张图像,为研究者提供了丰富的数据资源,有助于提升模型的泛化能力和检测精度。
使用方法
使用Hybrid Fake Face Dataset时,研究者需遵守特定的使用条款。首先,数据集仅限于非商业研究和教育目的。其次,使用者需对数据集的使用负全部责任,并保护数据集提供者免受任何因使用数据集而产生的索赔。此外,使用者若希望与他人共享数据集,需确保对方同意并遵守相同的使用条款。最后,数据集提供者保留随时终止使用者访问权限的权利。如需下载数据集,使用者需填写相关信息并发送到指定邮箱。
背景与挑战
背景概述
在人脸识别与深度伪造技术迅速发展的背景下,Hybrid Fake Face Dataset(HFF数据集)应运而生,旨在为研究者提供一个全面且多样化的数据集,以应对日益复杂的伪造人脸检测问题。该数据集由新疆大学的Guo Zhiqing等人于2021年创建,结合了来自CelebA、CelebA-HQ和FaceForensics等多个公开数据集的真实人脸图像,并通过PGGAN、StyleGAN、Face2Face、Glow和StarGAN等先进的人脸处理技术生成了多种类型的伪造图像。HFF数据集不仅模拟了互联网场景下的真实人脸,还涵盖了身份、表情和属性等多方面的伪造操作,为深度伪造检测领域的研究提供了宝贵的资源。
当前挑战
HFF数据集的构建面临多重挑战。首先,如何从多个公开数据集中选择并整合真实人脸图像,以确保数据集的真实性和多样性,是一个复杂的问题。其次,选择和应用多种先进的人脸处理技术生成伪造图像,不仅需要对这些技术的深入理解,还需确保生成的伪造图像具有足够的多样性和复杂性,以模拟实际应用中的伪造场景。此外,数据集的使用限制和访问控制也是一大挑战,确保数据仅用于非商业研究和教育目的,同时保护数据提供者的权益。这些挑战共同构成了HFF数据集在深度伪造检测领域中的重要性和复杂性。
常用场景
经典使用场景
Hybrid Fake Face Dataset(HFF数据集)在人脸图像处理领域中,主要用于检测和识别合成或篡改的人脸图像。该数据集通过结合多种先进的人脸生成和篡改技术,如PGGAN、StyleGAN、Face2Face、Glow和StarGAN,生成了大量高质量的假脸图像。这些图像与真实人脸图像混合,为研究人员提供了一个丰富的实验平台,用于开发和验证假脸检测算法。
衍生相关工作
基于HFF数据集,许多研究工作得以展开,包括但不限于假脸检测算法的改进、深度学习模型的优化以及多模态数据融合技术的应用。例如,Guo等人提出的自适应篡改痕迹提取网络(AMTENnet)就是基于该数据集开发的一种高效假脸检测方法。此外,该数据集还激发了关于人脸图像生成和篡改技术的深入研究,推动了相关领域的技术进步和创新。
数据集最近研究
最新研究方向
在人脸识别与深度伪造检测领域,Hybrid Fake Face Dataset(HFF数据集)因其丰富的图像类型和多样的生成技术而备受关注。该数据集不仅包含了从多个公开数据集中选取的真实人脸图像,还通过PGGAN、StyleGAN、Face2Face等前沿生成模型生成了大量伪造人脸图像,为研究者提供了多样化的数据支持。当前,HFF数据集的研究主要集中在深度伪造检测算法的开发与优化上,尤其是如何通过自适应特征提取网络(如AMTENnet)来提高检测的准确性和鲁棒性。此外,随着深度伪造技术的快速发展,HFF数据集的应用也扩展到了隐私保护、身份验证等新兴领域,进一步推动了相关技术的进步。
以上内容由遇见数据集搜集并总结生成


