rinabuoy/khm-asr-cultural
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/rinabuoy/khm-asr-cultural
下载链接
链接失效反馈官方服务:
资源简介:
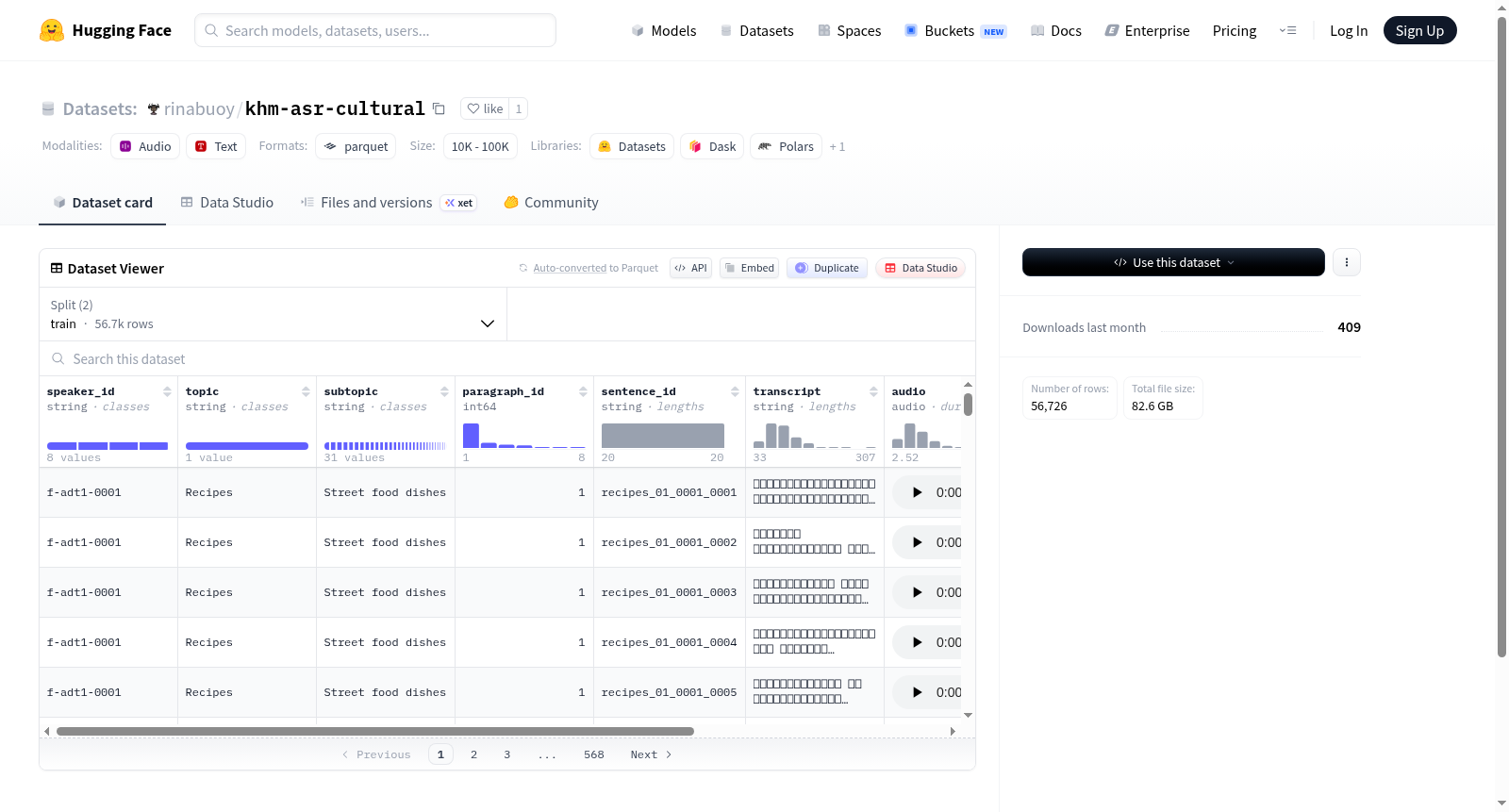
该数据集包含音频和文本数据,主要特征包括说话者ID、主题、子主题、段落ID、句子ID、转录文本、音频文件及其采样率和持续时间。数据集分为训练集和测试运行集,分别包含56716和10个示例。数据集的下载大小为82591796612字节,总大小为91246232067字节。
This dataset contains audio and text data, with main features including speaker ID, topic, subtopic, paragraph ID, sentence ID, transcript, audio file with its sampling rate and duration. The dataset is divided into a training set and a test run set, containing 56716 and 10 examples respectively. The download size of the dataset is 82591796612 bytes, and the total size is 91246232067 bytes.
提供机构:
rinabuoy
搜集汇总
数据集介绍
构建方式
khm-asr-cultural数据集由DDD-Cambodia团队精心构建,旨在服务于高棉语音识别(ASR)领域,特别聚焦于柬埔寨的文化语境。该数据集通过系统化的数据采集流程完成,包含说话人身份(speaker_id)、主题(topic)、子主题(subtopic)、段落编号(paragraph_id)、语句编号(sentence_id)、转录文本(transcript)、音频信号(audio)及音频时长(duration)等结构化字段。其中音频数据以16kHz采样率编码,确保高保真度。数据集划分为训练集(train)与测试集(test_run),训练集包含56,716个样本,测试集为10个样本,前者总字节数达91.2 GB,为模型训练提供了丰沛的语料基础。数据以分片形式存储于train-*与test_run-*路径下,便于分布式加载与处理。
特点
该数据集的核心特色在于其深厚的文化底蕴与专业化的构建策略。主题与子主题字段的引入,使得音频内容覆盖柬埔寨多元文化领域,如传统习俗、历史典故及艺术形式,赋予声学模型文化敏感性的学习能力。每条样本包含完整的说话人标注,支持多说话人场景下的声纹特征提取。音频时长字段(duration)以浮点数表示,便于统计分布与批次规划。特别值得注意的是,数据集设置了仅有10个样本的test_run分割,虽规模微小,但可能用于快速原型验证或调试,体现了开发者为研究人员提供的灵活性与便捷性。数字化建设上,16kHz采样率符合主流ASR标准,确保了与国际基准模型的兼容性。
使用方法
使用khm-asr-cultural数据集时,推荐通过Hugging Face的datasets库进行加载,指定配置名为default,并利用通配符路径data/train-*和data/test_run-*分别获取训练与测试数据。在ASR模型训练中,可将audio字段输入至特征提取模块,如Wav2Vec2或HuBERT的预处理器,并配合transcript字段作为标签进行端到端学习。topic与subtopic字段可用于条件式语言建模或领域自适应任务,增强模型在特定文化主题下的识别鲁棒性。speaker_id支持说话人验证或自适应训练,而paragraph_id与sentence_id有助于构建序列间依赖关系。建议在数据加载时利用map函数进行音频重采样或归一化,并依据duration字段过滤过短或过长的样本,以优化训练效率。
背景与挑战
背景概述
高棉语自动语音识别(ASR)领域长期面临数据资源匮乏的困境,尤其是针对柬埔寨本土文化语境的高质量语音数据集几乎空白。khm-asr-cultural数据集由柬埔寨数字发展组织(DDD-Cambodia)于近期创建,旨在填补这一关键缺口。该数据集围绕柬埔寨社会文化主题精心设计,涵盖多样化的演讲者、话题与子话题,通过结构化录音与转写构建起首个大规模高棉语文化语音基准。其发布不仅为低资源语言语音识别研究提供了稀缺的监督训练素材,更致力于推动面向东南亚语言语音技术的文化包容性发展。通过对本地语言发音、语调及民俗语汇的系统性收录,该数据集有望催生更精准的高棉语ASR模型,并激励研究者关注文化敏感型语音系统的构建。
当前挑战
该数据集所面临的核心挑战在于解决高棉语丰富却未被充分研究的音系特征所带来的自动识别难题,包括复杂音调模式、非正式的民间称谓以及地域性变体,这要求模型具备跨越细腻语境的适应能力。在构建过程中,团队需克服语料采集的分散性,从不同省份搜集代表性语音,并处理转写标注一致性的挑战,尤其针对部分口语表达缺乏标准化拼写的困境。此外,音频数据在真实环境中受背景噪音、录音设备差异等因素干扰,加之仅56716条训练样本的规模,对深度学习模型在不均衡方言分布下的鲁棒泛化构成了显著制约。
常用场景
经典使用场景
该数据集专为高棉语自动语音识别(ASR)任务而设计,其核心应用场景在于构建和评估面向低资源语言的端到端语音识别系统。数据集包含超过5.6万条训练样本,每条样本均提供了16kHz采样率的音频与对应文本转写,覆盖了多样化的主题与子话题,适用于开发者在受限数据条件下训练鲁棒性强的声学模型和语言模型,尤其适合探究迁移学习、数据增强及半监督方法在高棉语语音识别中的效能。
解决学术问题
该数据集着力解决高棉语等低资源语言在语音识别领域中标注数据匮乏的核心瓶颈。学术上,它支持研究者探索如何通过有限的有监督数据优化声学特征表示,评估跨语言或跨领域泛化能力,并推动对非拉丁字母语言音韵结构的建模研究。其意义在于为东南亚语言技术填补了数据空白,促进多语言ASR系统的公平性发展,为后续开展无监督预训练与微调范式的对比实验奠定了数据基础。
衍生相关工作
围绕该数据集衍生了多项经典工作,例如基于Wav2Vec 2.0或HuBERT等自监督框架在高棉语上的微调实验,验证了预训练模型在低资源场景下的迁移效果。部分研究利用该数据集构建了高棉语-英语的双语语音翻译基线系统,并对比了直接端到端模型与级联模型的性能差异。还有工作探索了说话人自适应与主题感知增强策略,证明了子话题标签可辅助改善语音识别中的领域歧义问题,为低资源语言的多任务学习提供了新思路。
以上内容由遇见数据集搜集并总结生成


