sapienzanlp/ReTraceQA
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/sapienzanlp/ReTraceQA
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: commonsenseqa
features:
- name: question
dtype: string
- name: choices
dtype: string
- name: facts
dtype: float64
- name: answer
dtype: string
- name: model_output
dtype: string
- name: model_name
dtype: string
- name: annotation
dtype: float64
- name: error_class
dtype: string
- name: dataset_index
dtype: string
splits:
- name: train
num_bytes: 1343503
num_examples: 899
download_size: 608876
dataset_size: 1343503
- config_name: openbookqa
features:
- name: question
dtype: string
- name: choices
dtype: string
- name: facts
dtype: string
- name: answer
dtype: string
- name: model_output
dtype: string
- name: model_name
dtype: string
- name: annotation
dtype: float64
- name: error_class
dtype: string
- name: dataset_index
dtype: string
splits:
- name: train
num_bytes: 697655
num_examples: 428
download_size: 322285
dataset_size: 697655
- config_name: qasc
features:
- name: question
dtype: string
- name: choices
dtype: string
- name: facts
dtype: float64
- name: answer
dtype: string
- name: model_output
dtype: string
- name: model_name
dtype: string
- name: annotation
dtype: float64
- name: error_class
dtype: string
- name: dataset_index
dtype: string
splits:
- name: train
num_bytes: 730605
num_examples: 464
download_size: 323909
dataset_size: 730605
- config_name: strategyqa
features:
- name: question
dtype: string
- name: choices
dtype: float64
- name: facts
dtype: string
- name: answer
dtype: bool
- name: model_output
dtype: string
- name: model_name
dtype: string
- name: annotation
dtype: float64
- name: error_class
dtype: string
- name: dataset_index
dtype: string
splits:
- name: train
num_bytes: 984730
num_examples: 630
download_size: 492766
dataset_size: 984730
configs:
- config_name: commonsenseqa
data_files:
- split: train
path: commonsenseqa/train-*
- config_name: openbookqa
data_files:
- split: train
path: openbookqa/train-*
- config_name: qasc
data_files:
- split: train
path: qasc/train-*
- config_name: strategyqa
data_files:
- split: train
path: strategyqa/train-*
---
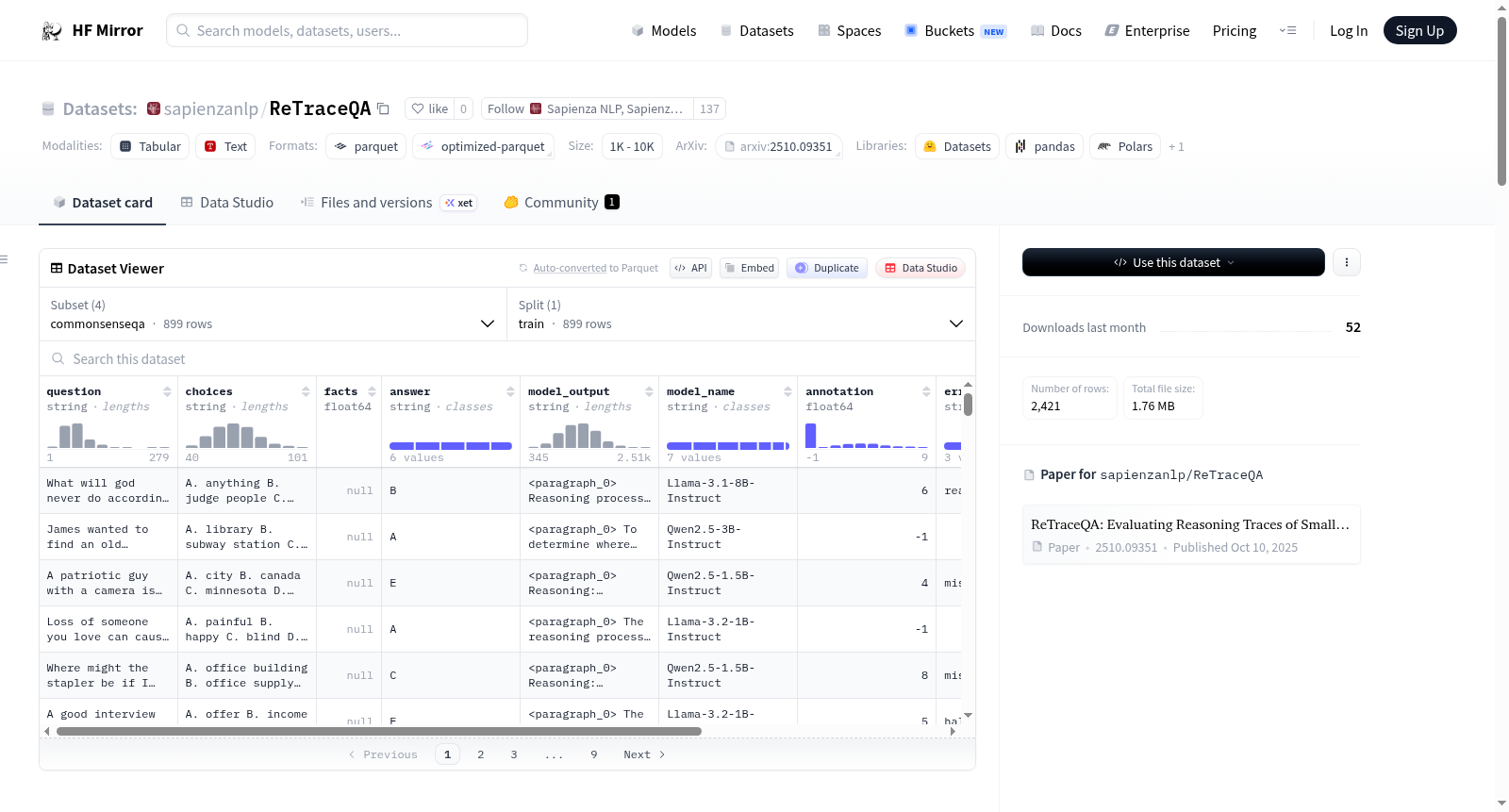
# Dataset Card for ReTraceQA
## Dataset Summary
**ReTraceQA** is a dataset designed to evaluate the reasoning traces of Small Language Models (SLMs) on commonsense reasoning tasks. It includes model-generated traces across four benchmark datasets: `CommonsenseQA`, `OpenBookQA`, `QASC`, and `StrategyQA`.
During the construction of ReTraceQA, only correct instances from the original benchmarks were retained, and erroneous instances were manually removed to ensure data quality.
Each item in the dataset contains a reasoning trace segmented into atomic steps (“paragraphs”), along with a human-annotated label indicating the index of the first erroneous step. If no error is present, the label is set to `-1`, indicating that the reasoning trace is entirely correct.
Additionally, for traces containing errors, each item includes an error classification specifying the type of mistake: `hallucination`, `reasoning`, or `misinterpretation`.
For more details, refer to our paper: [ReTraceQA: Evaluating Reasoning Traces of Small Language Models in Commonsense Question Answering
](https://arxiv.org/abs/2510.09351).
## Languages
This dataset is in English (en).
## Dataset Structure
The dataset consists of four subset one for each dataset : `CommonsenseQA`, `OpenBookQA`, `QASC`, and `StrategyQA`.
All the subsets share the same structure and contain the following fields:
- **`question` (str)**: The text of the question, drawn from the commonsense benchmarks.
- **`choices` (str)**: The text of the choices drawn from the commonsense benchmarks, it is not included for strategyqa benchmark.
- **`facts` (str)**: The text of the facts used as ground truth for evaluation of strategyqa subset.
- **`model_output` (str)**: A synthetic reasoning chain generated from SLMs, the text was postprocessed and divided into paragraphs.
- **`model_name` (str)**: The name of the SLM used to generate the synthetic reasonig trace.
- **`annotation` (int)**: The index of the first erroneous step if present in the `model_output`; `-1` if the trace is correct.
- **`error_class` (str)**: The annotated error category for erroneous traces, the categories are: `hallucination`, `reasoning`, and `misinterpretation`.
- **`dataset_index` (str)**: An unique index for the item.
An example of instance (commonsenseqa) is as follows:
```json
{
"question": "What will god never do according to religion?",
"choices": "A. anything\nB. judge people\nC. work miracles\nD. judge men\nE. everywhere",
"facts": null,
"answer": "B",
"model_output": "<paragraph_0>\nReasoning process:\n</paragraph_0>\n\n<paragraph_1>\nTo answer this..."
"model_name": "Llama-3.1-8B-Instruct",
"annotation": 6,
"error_class": "reasoning",
"dataset_index": "b62d7d1b5eec31be0b65146a9fc069e0",
}
```
## Dataset Statistics
### Error Index Annotations
Plot for the error index annotation over RetraceQA benchmark:
<p align="center">
<img src="https://github.com/Andrew-Wyn/images/blob/master/retraceqa/benchmark_error_steps.png?raw=true" width="500"/>
</p>
### Error Category Annotations
Distribution of the error categories annotation over RetraceQA benchmark:
<p align="center">
<img src="https://github.com/Andrew-Wyn/images/blob/master/retraceqa/avg-error-type.png?raw=true" width="500"/>
</p>
## Citation
If you use ReTraceQA in your research, please cite the following paper:
```bibtex
@misc{molfese2025retraceqaevaluatingreasoningtraces,
title={ReTraceQA: Evaluating Reasoning Traces of Small Language Models in Commonsense Question Answering},
author={Francesco Maria Molfese and Luca Moroni and Ciro Porcaro and Simone Conia and Roberto Navigli},
year={2025},
eprint={2510.09351},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2510.09351},
}
```
提供机构:
sapienzanlp
搜集汇总
数据集介绍
构建方式
在常识推理任务评估领域,ReTraceQA数据集的构建体现了严谨的学术范式。其核心方法在于从四个经典基准数据集(CommonsenseQA、OpenBookQA、QASC、StrategyQA)中筛选出模型回答正确的样本,并剔除了原始数据中的错误实例,以此确保数据质量的高纯度。随后,研究团队利用小型语言模型为每个样本生成结构化的推理轨迹,并将其分割为原子化的段落。关键的一步在于人工标注环节,专家为每条推理轨迹标注了首个错误步骤的索引,并对存在错误的轨迹进一步分类,归入幻觉、推理或误解三种错误类型,从而构建了一个具有精细错误诊断能力的评估资源。
特点
该数据集在常识推理评估领域展现出鲜明的结构性特征。其核心在于整合了多源基准数据,并统一封装了问题、选项、模型生成的推理轨迹、模型名称以及关键的人工标注信息。每条推理轨迹均被清晰地划分为段落结构,并附有首个错误步骤的索引标注,若无错误则以特定值标识。尤为突出的是,数据集对错误轨迹进行了类型学上的精细划分,涵盖了幻觉、推理与误解三大类别,这为深入分析模型在常识推理中失败的模式提供了多维度的视角。这种结构设计使得数据集不仅能评估最终答案的正确性,更能追溯和诊断推理过程中的具体缺陷。
使用方法
在自然语言处理的研究与应用中,ReTraceQA数据集主要服务于对小型语言模型推理能力的深度评估与改进。研究人员可以加载特定的数据子集,通过分析‘model_output’字段中的结构化推理轨迹,并结合‘annotation’与‘error_class’标注,定量评估模型在不同常识推理任务上的表现,并定位其典型的错误模式。该数据集可直接用于训练或评估旨在检测、纠正或生成更可靠推理链的模型,例如通过预测错误步骤或分类错误类型来提升模型的鲁棒性。其统一的数据结构也便于跨数据集比较分析,为理解模型在复杂推理任务中的行为机制提供了实证基础。
背景与挑战
背景概述
在自然语言处理领域,常识推理能力是评估语言模型智能水平的核心维度之一。ReTraceQA数据集由Francesco Maria Molfese等研究人员于2025年构建,旨在系统评估小型语言模型在常识问答任务中的推理轨迹。该数据集整合了CommonsenseQA、OpenBookQA、QASC和StrategyQA四个经典基准,通过保留原始数据中正确的问答实例,并引入模型生成的推理链与人工标注的错误步骤索引,为分析模型推理过程的透明性与可靠性提供了结构化资源。其设计聚焦于揭示模型在复杂语义理解与逻辑推演中的内在机制,对推动可解释人工智能与细粒度评估方法的发展具有显著意义。
当前挑战
ReTraceQA致力于解决常识推理任务中模型输出可解释性与错误归因的挑战,其核心在于精准定位推理链中的谬误步骤并分类错误类型,如幻觉、逻辑缺陷或语义误解。在构建过程中,研究团队面临多重困难:需从原始数据集中严格筛选正确实例以确保数据质量,同时人工标注要求对模型生成的冗长推理轨迹进行逐段审阅,界定错误边界与类别,这一过程耗时且易受主观判断影响。此外,协调不同基准数据集的结构差异,并设计统一且可扩展的标注框架,亦构成了数据集构建的技术瓶颈。
常用场景
经典使用场景
在常识推理研究领域,ReTraceQA数据集为评估小型语言模型的推理轨迹提供了标准化基准。该数据集整合了CommonsenseQA、OpenBookQA、QASC和StrategyQA等多个经典常识问答任务,通过保留原始基准中正确的实例并移除错误数据,构建了高质量的推理轨迹集合。研究者通常利用该数据集分析模型在生成多步推理链时的表现,特别是识别推理过程中首次出现错误的步骤位置,从而深入探究模型在复杂常识理解任务中的内部机制与局限性。
衍生相关工作
围绕ReTraceQA数据集,学术界已衍生出一系列聚焦于推理轨迹分析与改进的经典研究工作。这些工作通常利用数据集提供的错误步骤标注和分类信息,开发新型的评估指标或训练方法,例如针对推理链进行纠错或增强的模型。部分研究进一步探索了如何利用这些标注数据来提升模型在少样本或零样本设置下的推理能力,或者构建能够自动检测并修复推理错误的辅助系统。这些衍生工作共同推动了常识推理模型向更高层次的精确性与可解释性发展。
数据集最近研究
最新研究方向
在常识推理领域,ReTraceQA数据集的推出标志着对小型语言模型推理过程系统性评估的新兴趋势。该数据集通过整合多个经典基准,并引入人工标注的错误步骤索引与错误分类,为研究者提供了深入剖析模型推理链缺陷的宝贵资源。当前前沿研究聚焦于利用此类细粒度标注数据,开发更精准的推理验证与纠错机制,以增强模型的可解释性与鲁棒性。这一方向与当前人工智能领域追求透明、可信推理的热点紧密相连,对于推动小规模模型在资源受限场景下的可靠应用具有重要理论价值与实践意义。
以上内容由遇见数据集搜集并总结生成


