piqa
收藏Hugging Face2025-07-21 更新2025-07-22 收录
下载链接:
https://huggingface.co/datasets/regisss/piqa
下载链接
链接失效反馈资源简介:
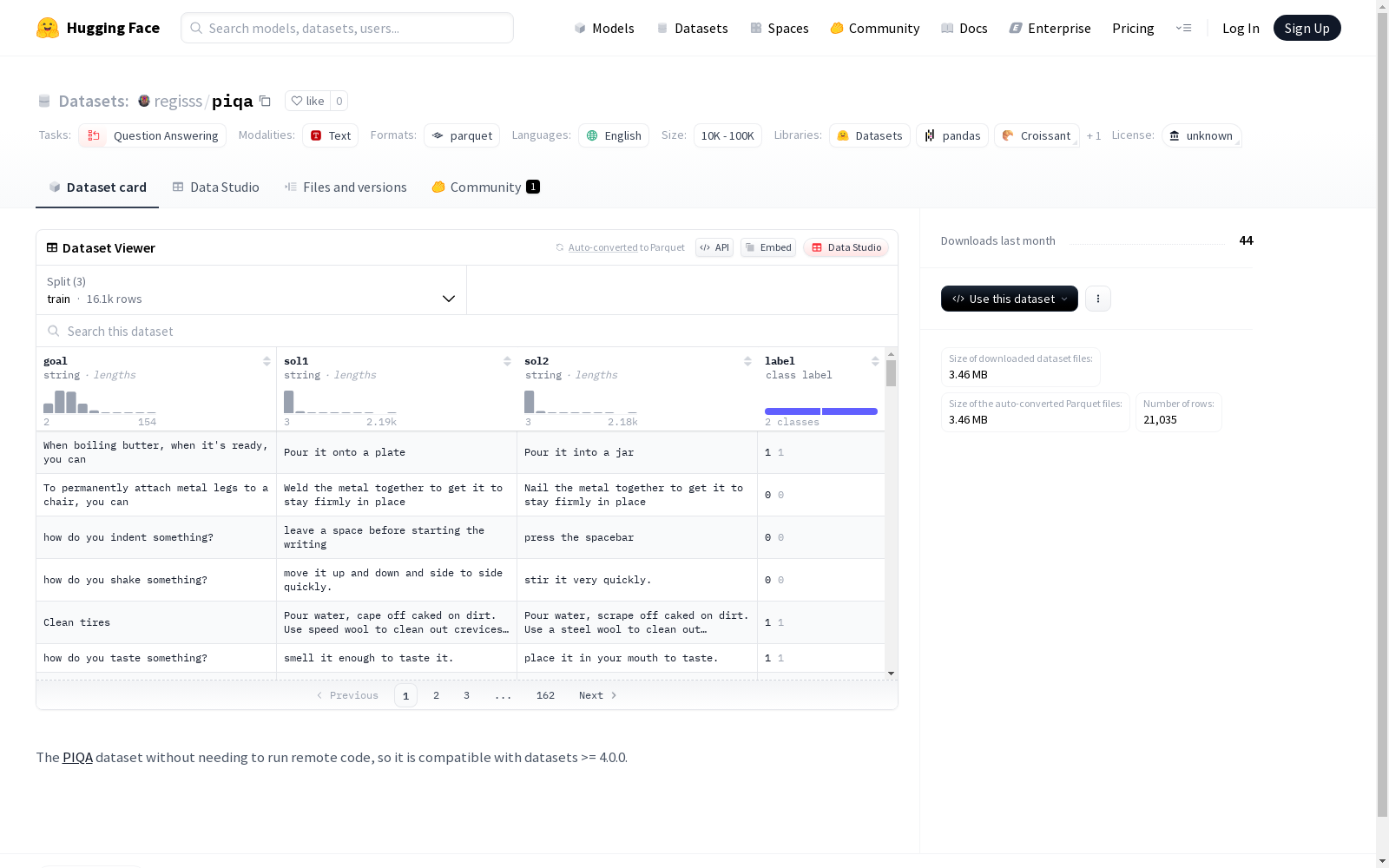
PIQA数据集是一个用于问答任务的数据集,包含goal, sol1, sol2和label四个字段,其中label有两个类别。数据集分为训练集、测试集和验证集,总大小为5329820字节。
The PIQA dataset is a dataset designed for question answering tasks, which contains four fields: goal, sol1, sol2, and label. The label has two categories. The dataset is divided into training set, test set and validation set, with a total size of 5,329,820 bytes.
创建时间:
2025-07-17
原始信息汇总
数据集概述
基本信息
- 数据集名称: PIQA
- 许可证: unknown
- 语言: 英语 (en)
- 大小类别: 10K<n<100K
- 任务类别: 问答 (question-answering)
数据集结构
- 特征:
goal: 字符串类型,描述任务目标sol1: 字符串类型,解决方案1sol2: 字符串类型,解决方案2label: 类标签类型,包含两个类别 (0 和 1)
数据划分
- 训练集 (train):
- 样本数量: 16113
- 大小: 4104002 字节
- 测试集 (test):
- 样本数量: 3084
- 大小: 761509 字节
- 验证集 (validation):
- 样本数量: 1838
- 大小: 464309 字节
下载与存储
- 下载大小: 3460529 字节
- 数据集总大小: 5329820 字节
备注
- 该数据集为PIQA数据集的兼容版本,无需运行远程代码,兼容 datasets >= 4.0.0。
AI搜集汇总
数据集介绍
构建方式
在物理推理与常识理解的研究领域中,PIQA数据集的构建采用了严谨的实证方法。研究者通过收集日常物理场景中的目标导向问题,精心设计了两套备选解决方案,并由专家团队进行人工标注。数据采集过程注重场景多样性和解决方案的平衡性,最终形成包含20,835个样本的高质量数据集,划分为训练集、验证集和测试集三部分,确保模型评估的科学性。
使用方法
该数据集适用于训练和评估物理常识推理模型,研究者可通过加载标准数据分割直接使用。训练集用于模型参数学习,验证集辅助超参数调优,测试集则提供最终性能评估。每个样本的标签信息支持二分类任务,解决方案对比机制特别适合研究物理常识的推理过程。使用HuggingFace数据集库可实现一键加载,确保与最新工具链的兼容性。
背景与挑战
背景概述
PIQA数据集作为物理常识推理领域的重要基准,由Yonatan Bisk等研究者于2019年构建,旨在评估人工智能系统对日常物理现象的认知能力。该数据集聚焦于物理交互问答任务,通过16,113组人工标注的问答对,探究机器在理解物体属性、力作用关系及因果推理等方面的表现。作为Allen人工智能研究院的成果之一,其创新性地将物理常识形式化为二选一问题范式,显著推动了具身智能和可解释AI在物理推理方向的研究进展。
当前挑战
该数据集核心挑战体现在语义理解与物理逻辑的双重复杂性上:一方面,模型需准确解析涉及多物体交互的自然语言描述,如‘如何用湿毛巾拧干水’这类隐含物理约束的问题;另一方面,数据构建过程面临标注一致性难题,因物理常识常存在地域文化差异,需通过多轮专家验证确保标注质量。此外,数据规模限制导致模型易受表面语言模式干扰,难以真正掌握物理规律的本质表征。
常用场景
经典使用场景
在认知科学与人工智能领域,PIQA数据集被广泛用于评估模型在物理常识推理方面的能力。该数据集通过呈现日常物理场景中的问题,要求模型在两个可能的解决方案中选择更合理的一个,从而测试其对物理世界的理解。这种设置特别适合于研究模型在非结构化环境下的推理能力,为研究者提供了一个标准化的评估平台。
解决学术问题
PIQA数据集有效解决了人工智能领域长期存在的物理常识推理难题。通过提供大量基于真实物理场景的问题,该数据集填补了传统语言模型在物理世界知识上的空白。研究者可以利用它来探索模型如何将语言理解与物理规律相结合,进而推动更具解释性的人工智能系统的发展。这一突破对构建真正理解物理世界的AI具有重要意义。
实际应用
在实际应用中,PIQA数据集为开发具有物理常识的智能助手奠定了基础。基于该数据集训练的模型可以应用于家庭机器人、智能教育系统等场景,使其能够更自然地与物理环境互动。例如,在家庭服务机器人领域,这种能力可以帮助机器人更好地理解用户指令背后的物理约束,从而做出更合理的决策。
数据集最近研究
最新研究方向
在自然语言处理领域,物理常识推理能力已成为评估模型智能水平的重要维度。PIQA数据集作为物理交互问答基准,近期研究聚焦于多模态预训练模型在该任务上的迁移学习表现,特别是视觉-语言联合表征对物理场景理解的增强效应。2023年以来,研究者们尝试将大型语言模型与物理引擎相结合,通过生成式对抗训练提升模型对物体相互作用、力传导等隐含物理规律的推理能力。这一方向与具身人工智能的发展趋势相呼应,为服务机器人、虚拟助手等应用场景提供了可解释性更强的决策基础。
以上内容由AI搜集并总结生成


