Light-R1-SFTData-Reformatted
收藏Hugging Face2025-03-19 更新2025-03-20 收录
下载链接:
https://huggingface.co/datasets/RJTPP/Light-R1-SFTData-Reformatted
下载链接
链接失效反馈官方服务:
资源简介:
这个数据集是Light-R1-SFTData的一个重格式化版本,它将原始的对话JSON结构拆分为三个不同的列:问题、复杂思维链和最终响应。数据集适用于问题回答和文本生成任务,主题标签涉及医学和生物学。
创建时间:
2025-03-18
搜集汇总
数据集介绍
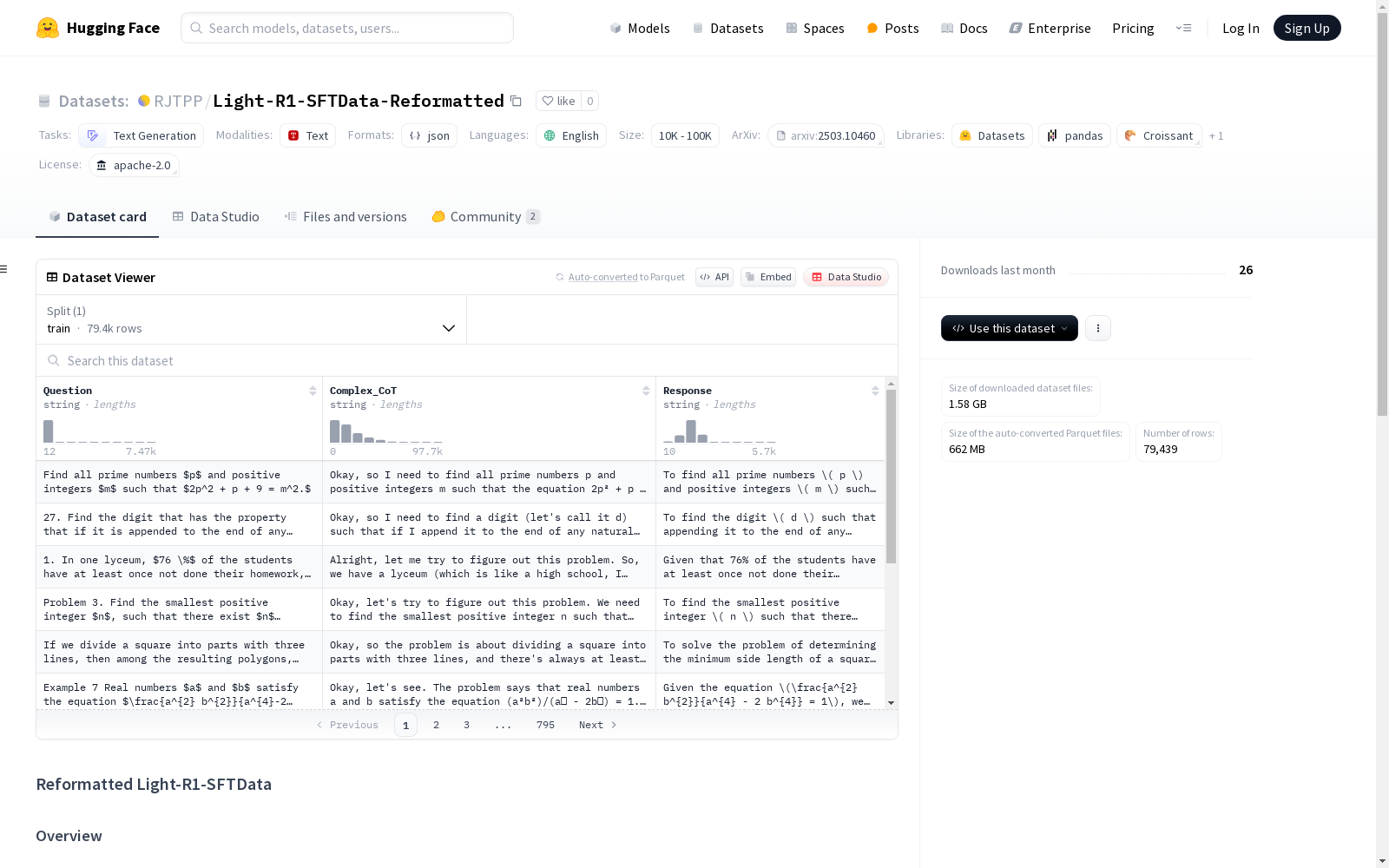
构建方式
Light-R1-SFTData-Reformatted数据集是对原始Light-R1-SFTData的重新格式化版本,旨在提升数据处理的灵活性和训练效率。原始数据集采用`conversations`的JSON结构,经过重构后,数据被划分为三个独立的列:`Question`、`Complex_CoT`和`Response`。这种结构化的拆分不仅便于数据的进一步定制化处理,还为模型训练提供了更清晰的输入输出框架。
特点
该数据集的特点在于其清晰的层次化结构,将复杂的链式思维推理(Complex_CoT)与问题(Question)和最终响应(Response)分离,使得模型能够更好地理解和生成多步推理过程。此外,数据集的格式化设计使其能够无缝集成到多种文本生成任务中,特别适用于需要复杂推理能力的场景。
使用方法
使用Light-R1-SFTData-Reformatted数据集时,用户可以直接加载其分列结构,利用`Question`作为输入,`Complex_CoT`作为中间推理步骤,`Response`作为目标输出进行模型训练。这种设计使得数据能够灵活适配不同的训练框架,如监督微调(SFT)或强化学习(RL)。用户还可以根据需求进一步调整数据格式,以优化特定任务的性能。
背景与挑战
背景概述
Light-R1-SFTData-Reformatted数据集是基于原始Light-R1-SFTData的重新格式化版本,旨在提升数据处理的灵活性和训练效率。该数据集由360公司(qihoo360)的研究团队于2025年发布,专注于文本生成任务,特别是复杂推理链(Chain-of-Thought, CoT)的生成。原始数据集采用对话形式的JSON结构,经过重新格式化后,数据被分解为三个独立列:问题、复杂推理链和生成响应。这一改进使得数据更易于定制和训练,推动了自然语言处理领域中对复杂推理任务的研究。该数据集的研究成果已在arXiv平台上公开发表,标志着其在长链推理和文本生成领域的重要贡献。
当前挑战
Light-R1-SFTData-Reformatted数据集在解决复杂推理链生成问题时面临多重挑战。首先,复杂推理链的生成需要模型具备高度的逻辑推理能力,这对模型的架构和训练方法提出了更高的要求。其次,原始数据集的对话形式虽然丰富,但在实际应用中存在格式不统一的问题,导致数据处理和训练效率低下。重新格式化过程中,研究人员需要确保数据的完整性和一致性,同时保留原始数据的语义信息。此外,如何在高维文本空间中有效捕捉和生成复杂的推理链,仍然是该领域亟待解决的核心问题。这些挑战不仅推动了数据集的优化,也为相关领域的研究提供了新的方向。
常用场景
经典使用场景
Light-R1-SFTData-Reformatted数据集在自然语言处理领域,尤其是文本生成任务中,展现了其独特的价值。该数据集通过将原始的对话结构拆分为问题、复杂推理链和最终响应三个独立列,极大地提升了数据处理的灵活性和训练效率。这种格式特别适用于需要精细控制生成内容的场景,如对话系统的训练和优化。
衍生相关工作
基于Light-R1-SFTData-Reformatted数据集,一系列相关研究工作得以展开。例如,研究人员利用该数据集开发了新的模型训练方法,如基于课程学习的策略优化和深度偏好优化。这些方法不仅提升了模型的生成质量,还显著提高了训练效率。此外,该数据集还促进了多模态学习领域的研究,推动了文本与视觉信息的深度融合。
数据集最近研究
最新研究方向
在自然语言处理领域,Light-R1-SFTData-Reformatted数据集的最新研究方向聚焦于链式思维(Chain-of-Thought, CoT)推理的优化与应用。该数据集通过将原始对话结构拆分为问题、复杂链式思维推理和最终响应三个独立列,显著提升了数据处理的灵活性和训练效率。近年来,随着大语言模型(LLMs)在复杂推理任务中的广泛应用,CoT推理已成为研究热点,尤其是在多步推理和长文本生成任务中。Light-R1-SFTData-Reformatted的推出为研究者提供了更精细的数据支持,助力模型在长链式思维推理任务中的性能提升。此外,该数据集的开源特性及其遵循的Apache 2.0许可,进一步推动了学术界和工业界的协作创新,为自然语言生成和推理任务的前沿研究奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


