UzbekPOS
收藏arXiv2025-01-17 更新2025-01-21 收录
下载链接:
https://huggingface.co/datasets/latofat/uzbekpos
下载链接
链接失效反馈官方服务:
资源简介:
UzbekPOS数据集是首个公开的乌兹别克语词性标注基准数据集,由凯泽斯劳滕-兰道大学和萨尔兰大学的研究团队创建。该数据集包含500个句子,共计5831个单词,涵盖了新闻和小说两种文本类型。数据集的标注基于通用词性标注(UPOS)标准,适用于乌兹别克语的拉丁和西里尔两种书写形式。数据集的创建过程包括手动标注和脚本转换,旨在为乌兹别克语的词性标注任务提供高质量的基准数据。该数据集的应用领域包括自然语言处理中的词性标注、语言分析和语料库语言学,旨在解决乌兹别克语这一低资源语言在NLP任务中的资源匮乏问题。
The UzbekPOS dataset is the first publicly available benchmark dataset for Uzbek part-of-speech tagging, developed by a research team from the University of Kaiserslautern-Landau and Saarland University. This dataset contains 500 sentences with a total of 5,831 words, covering two text genres: news and fiction. The annotation of the dataset follows the Universal Part-of-Speech (UPOS) standard, and supports both Latin and Cyrillic writing systems for the Uzbek language. The creation of the dataset involves manual annotation and script conversion, aiming to provide high-quality benchmark data for Uzbek part-of-speech tagging tasks. The dataset has applications in part-of-speech tagging, linguistic analysis, and corpus linguistics within the field of natural language processing, and is designed to address the resource scarcity issue of Uzbek, a low-resource language, in NLP tasks.
提供机构:
凯泽斯劳滕-兰道大学, 萨尔兰大学
创建时间:
2025-01-17
搜集汇总
数据集介绍
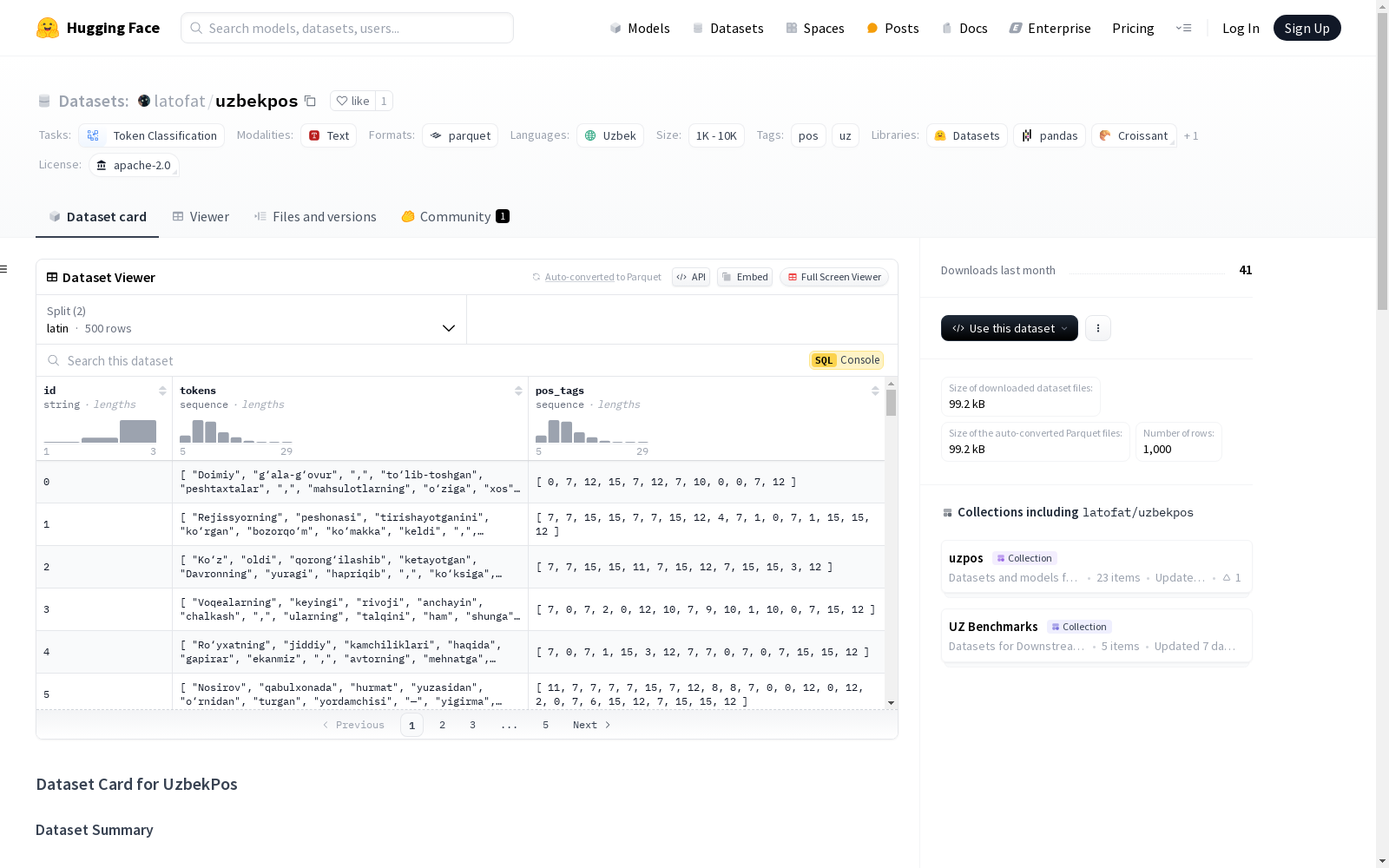
构建方式
UzbekPOS数据集的构建基于乌兹别克语的新闻和小说文本,共包含500个句子,涵盖了拉丁和西里尔两种书写形式。数据集的标注采用了通用词性标注(UPOS)体系,确保了跨语言的一致性。首先,研究人员从新闻文章和小说中选取了250个句子,手动标注了拉丁脚本的文本,随后将其转写为西里尔脚本,以便为西里尔脚本的模型进行微调。数据集的标注工作由具有乌兹别克语语言学背景的专家完成,确保了标注的准确性和一致性。
特点
UzbekPOS数据集是首个公开的乌兹别克语词性标注基准数据集,涵盖了17个UPOS标签,能够全面反映乌兹别克语的词性特征。该数据集的一个显著特点是其多脚本支持,既包含拉丁脚本,也包含西里尔脚本,为研究乌兹别克语的多脚本处理提供了便利。此外,数据集的句子来源广泛,涵盖了新闻和小说两种文体,确保了数据的多样性和代表性。数据集的标注质量高,能够有效支持基于BERT等预训练模型的词性标注任务。
使用方法
UzbekPOS数据集主要用于乌兹别克语的词性标注任务,特别适用于基于BERT等预训练模型的微调实验。研究人员可以通过该数据集对乌兹别克语的词性标注模型进行训练和评估,尤其是在低资源语言环境下。数据集的使用方法包括将数据集划分为训练集和测试集,通常采用5折交叉验证的方式进行模型评估。此外,数据集还可用于比较不同脚本(拉丁与西里尔)下的模型表现,以及研究乌兹别克语的形态学特征。数据集的公开性为乌兹别克语的NLP研究提供了重要的基准资源。
背景与挑战
背景概述
UzbekPOS数据集是首个公开的乌兹别克语词性标注基准数据集,由RPTU Kaiserslautern-Landau和Saarland University的研究团队于2025年创建。该数据集旨在填补乌兹别克语这一低资源语言在自然语言处理(NLP)领域中的空白,特别是在词性标注(POS tagging)任务上。乌兹别克语作为一种形态丰富的语言,具有高度的黏着性,其词性标注任务面临诸多挑战。该数据集的创建基于500个句子,涵盖了新闻和小说两种文体,并采用了通用的词性标注集(UPOS)。通过该数据集,研究团队成功训练了基于BERT的乌兹别克语词性标注模型,取得了91%的平均准确率,显著优于现有的规则基标注器和多语言BERT模型。
当前挑战
UzbekPOS数据集在构建和应用过程中面临多重挑战。首先,乌兹别克语作为一种低资源语言,缺乏公开的标注数据集和预训练模型,导致词性标注任务的基准数据稀缺。其次,乌兹别克语的形态复杂性使得词性标注任务尤为困难,特别是在处理词缀变化和上下文敏感性时,现有的规则基标注器表现不佳。此外,数据集的构建过程中,研究人员需要手动标注大量数据,并处理拉丁字母和西里尔字母之间的转换问题,尤其是拉丁字母中的特殊字符(如o‘、g‘和’)在预训练模型中的处理不当,导致分词错误。最后,数据集中某些词性标签的样本量不足,影响了模型对这些标签的学习效果。
常用场景
经典使用场景
UzbekPOS数据集在自然语言处理领域中的经典使用场景主要集中在对乌兹别克语的词性标注任务上。该数据集通过提供500个经过手动标注的句子,涵盖了新闻和小说两种文本类型,为研究者提供了一个基准测试平台。通过使用BERT模型进行微调,研究者能够在乌兹别克语的词性标注任务中达到91%的平均准确率,显著优于传统的基于规则的标注工具。
实际应用
在实际应用中,UzbekPOS数据集可以用于乌兹别克语的文本分析、语料库语言学以及机器翻译等领域。通过提供高质量的标注数据,该数据集能够帮助开发更精确的语言模型,提升乌兹别克语文本处理的效率。此外,该数据集还可用于教育领域,帮助学习者更好地理解乌兹别克语的语法结构和词性变化。
衍生相关工作
UzbekPOS数据集的发布推动了乌兹别克语自然语言处理领域的研究进展。基于该数据集,研究者开发了多个BERT模型,如TahrirchiBERT和UzBERT,这些模型在词性标注任务中表现出色。此外,该数据集还激发了更多关于乌兹别克语形态分析和句法标注的研究,为未来的语言模型开发提供了重要的参考。
以上内容由遇见数据集搜集并总结生成


