mosel
收藏Hugging Face2024-10-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/FBK-MT/mosel
下载链接
链接失效反馈官方服务:
资源简介:
MOSEL语料库是一个多语言数据集集合,包含多达95万小时的开放源代码语音录音,涵盖欧盟的24种官方语言。通过调查符合开放源代码许可的标记和未标记语音语料库来收集数据。它包括来自VoxPopuli和LibriLight的44.1万小时未标记语音的自动转录,使用Whisper large v3进行转录。数据集按语言使用2字母ISO代码分成文件夹,每个文件夹包含每个伪标记数据集的分割。数据集包含字段如'id'、'language'、'text'、'hall_repeated_ngrams'、'hall_long_word'和'hall_frequent_single_word'。数据集统计数据按每种语言的标记和未标记数据的小时数提供,总计950,192小时。
创建时间:
2024-09-23
原始信息汇总
MOSEL 数据集概述
数据集描述
- 任务类别: 自动语音识别
- 语言:
- 英语 (en)
- 保加利亚语 (bg)
- 克罗地亚语 (hr)
- 捷克语 (cs)
- 丹麦语 (da)
- 荷兰语 (nl)
- 爱沙尼亚语 (et)
- 芬兰语 (fi)
- 法语 (fr)
- 德语 (de)
- 希腊语 (el)
- 匈牙利语 (hu)
- 爱尔兰语 (ga)
- 意大利语 (it)
- 拉脱维亚语 (lv)
- 立陶宛语 (lt)
- 马耳他语 (mt)
- 波兰语 (pl)
- 葡萄牙语 (pt)
- 罗马尼亚语 (ro)
- 斯洛伐克语 (sk)
- 斯洛文尼亚语 (sl)
- 西班牙语 (es)
- 瑞典语 (sv)
- 数据集名称: MOSEL
- 许可证: CC-BY-4.0
数据集来源
- 数据收集: 通过调查符合开源许可的标注和未标注语音语料库收集数据。
- 自动转录: 使用 Whisper large v3 对 VoxPopuli 和 LibriLight 的 441k 小时未标注语音进行自动转录。
- 数据分割: 由于 LibriLight 包含超过 Whisper 最大时长限制(30秒)的片段,因此将其分割为不超过 30秒的块。
数据集结构
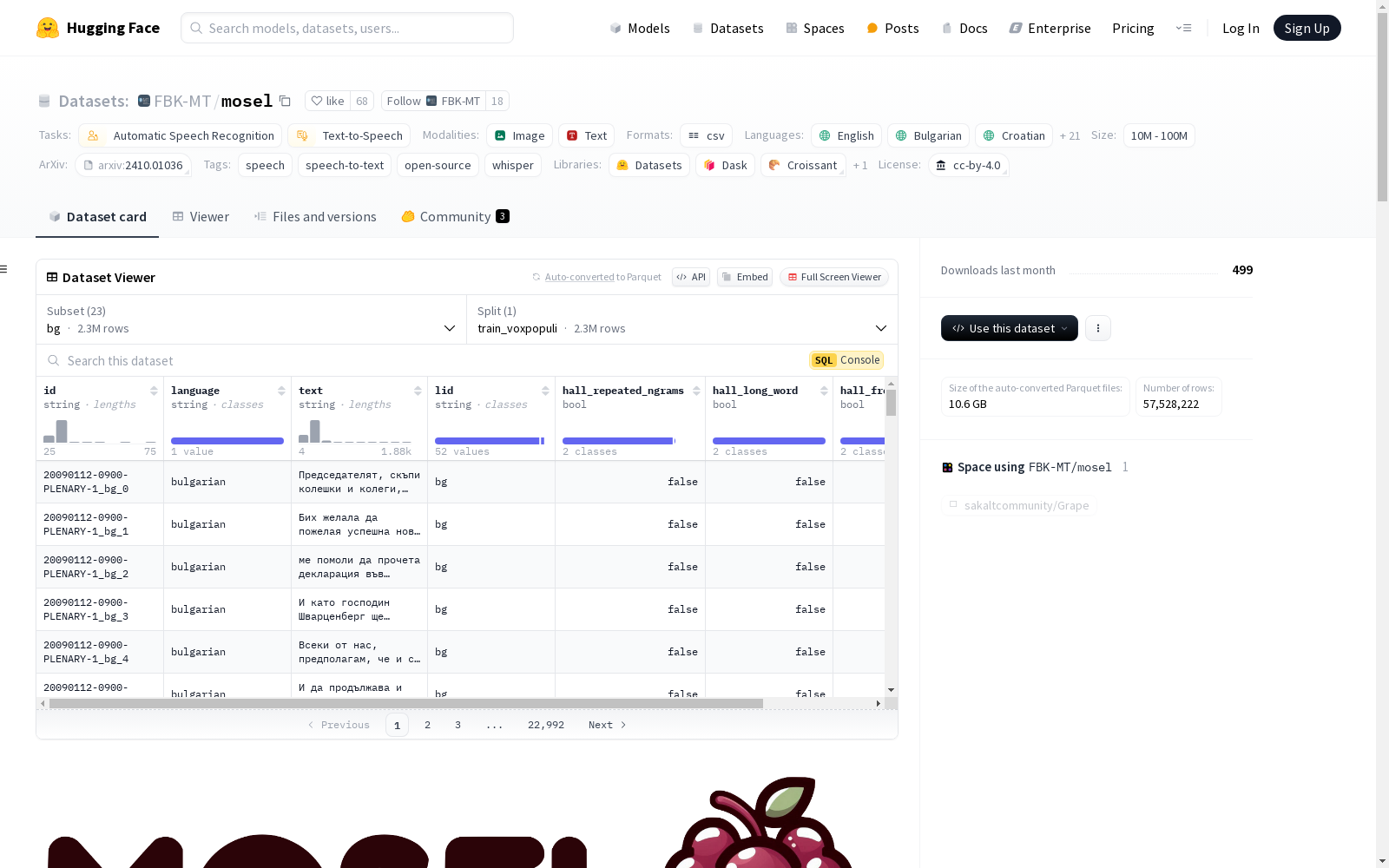
- 数据配置: 数据集按语言分为文件夹,使用 ISO 639-1 两字母代码表示语言。每个文件夹包含一个伪标注数据集的分割。
- 数据字段:
id: 段落的字母数字标识符language: 扩展语言名称(例如,"english")text: 伪标签内容hall_repeated_ngrams: 指示text中是否重复出现 n-gram,阈值为 4(n 为 1 到 2)或 3(n 为 3 到 5)hall_long_word: 指示text中是否存在至少 40 个字符的单词hall_frequent_single_word: 指示text是否仅由整个文本中最频繁的单个单词组成
数据集统计
| 语言 (LangID) | 标注时长 (小时) | 未标注时长 (小时) | 总时长 (小时) |
|---|---|---|---|
| Bulgarian (bg) | 111 | 17609 | 17720 |
| Croatian (hr) | 55 | 8106 | 8161 |
| Czech (cs) | 591 | 18705 | 19296 |
| Danish (da) | 20 | 13600 | 13620 |
| Dutch (nl) | 3395 | 19014 | 22409 |
| English (en) | 437239 | 84704 | 521943 |
| Estonian (et) | 60 | 10604 | 10664 |
| Finnish (fi) | 64 | 14200 | 14264 |
| French (fr) | 26984 | 22896 | 49880 |
| German (de) | 9236 | 23228 | 32464 |
| Greek (el) | 35 | 17703 | 17738 |
| Hungarian (hu) | 189 | 17701 | 17890 |
| Irish (ga) | 17 | 0 | 17 |
| Italian (it) | 3756 | 21933 | 25689 |
| Latvian (lv) | 173 | 13100 | 13273 |
| Lithuanian (lt) | 36 | 14400 | 14436 |
| Maltese (mt) | 19 | 9100 | 9119 |
| Polish (pl) | 510 | 21207 | 21717 |
| Portuguese (pt) | 5492 | 17526 | 23018 |
| Romanian (ro) | 121 | 17906 | 18021 |
| Slovak (sk) | 61 | 12100 | 12161 |
| Slovenian (sl) | 32 | 11300 | 11332 |
| Spanish (es) | 17471 | 21526 | 38997 |
| Swedish (sv) | 58 | 16300 | 16358 |
| 总计 | 505725 | 444467 | 950192 |
数据集创建
- 重现数据集创建: 请参考 MOSEL README in the fbk-llm 仓库。
引用
@inproceedings{mosel, title = {{MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages}}, author = {Marco Gaido and Sara Papi and Luisa Bentivogli and Alessio Brutti and Mauro Cettolo and Roberto Gretter and Marco Matassoni and Mohamed Nabihand Matteo Negri}, booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing", month = nov, year = "2024", address = "Miami, United States", publisher = "Association for Computational Linguistics", }
数据集卡片联系
- 联系人: @spapi
搜集汇总
数据集介绍
构建方式
MOSEL数据集通过整合多种开源语音语料库构建而成,涵盖了欧盟24种官方语言的语音数据,总计约950,000小时。数据来源包括VoxPopuli和LibriLight等开源语音库,其中441,000小时的未标注语音通过Whisper large v3模型自动转录生成。对于超过Whisper模型30秒时长限制的语音片段,数据集进行了分段处理,确保每段语音不超过30秒。所有数据均遵循开源许可协议,确保其合法性和可复用性。
特点
MOSEL数据集以其多语言性和大规模语音数据为显著特点,涵盖了从保加利亚语到瑞典语等多种欧洲语言。数据集不仅包含大量未标注的语音数据,还提供了自动生成的伪标签文本,并标注了文本中的重复n-gram、长单词及高频单字等特征。此外,数据集按语言分类存储,便于用户根据需求选择特定语言的数据进行训练或研究。
使用方法
MOSEL数据集适用于自动语音识别(ASR)和文本到语音(TTS)等任务。用户可通过Hugging Face平台访问数据集,按语言代码选择所需数据。数据集提供了详细的字段信息,如语音片段的唯一标识符、语言标签、伪标签文本及其质量标注。用户可直接加载数据用于模型训练,或参考GitHub仓库中的代码复现数据集的构建过程。
背景与挑战
背景概述
MOSEL数据集是一个多语言语音数据集,涵盖了欧盟24种官方语言,总时长高达950,000小时。该数据集由Marco Gaido、Sara Papi等研究人员主导,并由FAIR、Meetween和CINECA等机构资助,Fondazione Bruno Kessler负责共享。MOSEL的核心研究问题在于为开源语音基础模型的训练提供大规模、多语言的语音数据支持,特别是在自动语音识别(ASR)和文本到语音(TTS)任务中。该数据集通过整合VoxPopuli和LibriLight等开源语音语料库,利用Whisper模型进行自动转录,显著推动了多语言语音处理领域的研究与应用。
当前挑战
MOSEL数据集在构建和应用过程中面临多重挑战。首先,多语言数据的收集与标注需要处理不同语言的语音特征和语法结构,这对模型的泛化能力提出了高要求。其次,自动转录过程中,Whisper模型对长音频的处理存在限制,需将超过30秒的音频分割为短片段,这可能导致上下文信息的丢失。此外,数据集中部分语言的样本量较少,可能导致模型在这些语言上的表现不均衡。最后,尽管数据集规模庞大,但如何确保转录质量、减少噪声和错误标注仍是亟待解决的问题。
常用场景
经典使用场景
MOSEL数据集广泛应用于自动语音识别(ASR)和文本到语音(TTS)任务中,尤其是在多语言环境下。其包含的24种欧盟官方语言的语音数据,使得研究者能够在跨语言语音处理领域进行深入探索。通过Whisper模型生成的自动转录文本,MOSEL为语音识别模型的训练和评估提供了丰富的多语言语料库。
解决学术问题
MOSEL数据集解决了多语言语音识别中的语料稀缺问题,尤其是在低资源语言环境下。通过整合VoxPopuli和LibriLight等开源语音数据,MOSEL为研究者提供了大规模、高质量的语音转录数据,显著提升了多语言语音识别模型的性能。此外,其自动生成的伪标签为无监督学习和半监督学习提供了新的研究途径。
衍生相关工作
MOSEL数据集催生了一系列经典研究工作,尤其是在多语言语音识别和语音合成领域。基于MOSEL的研究成果包括改进的Whisper模型变体、多语言语音识别系统的优化方法,以及跨语言语音合成的创新技术。这些工作不仅推动了语音处理技术的发展,也为多语言语音应用的商业化奠定了基础。
以上内容由遇见数据集搜集并总结生成


