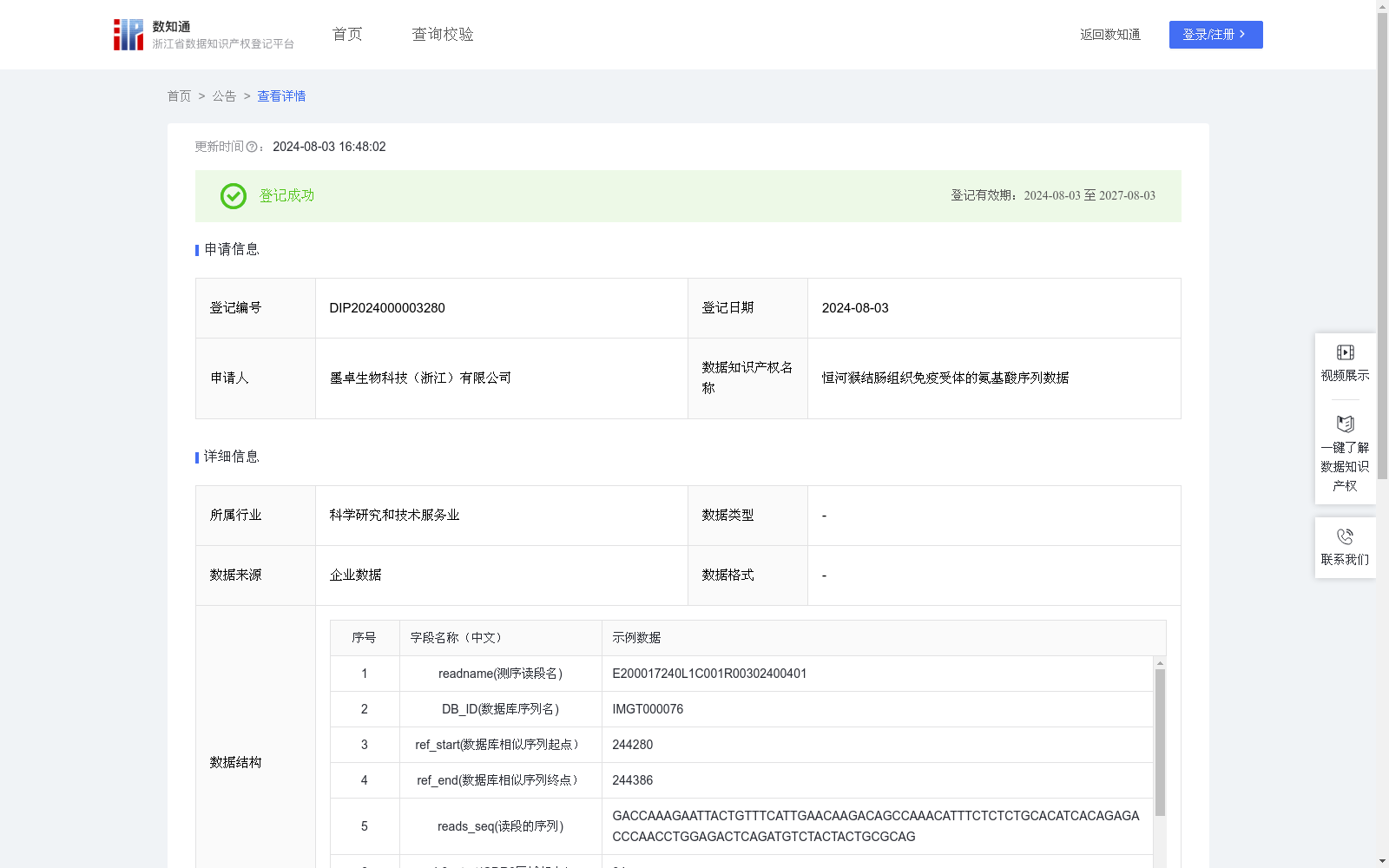
恒河猴结肠组织免疫受体的氨基酸序列数据
收藏浙江省数据知识产权登记平台2024-08-03 更新2024-08-04 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/47297
下载链接
链接失效反馈官方服务:
资源简介:
通过研究恒河猴免疫组库的细胞受体序列,可以筛选出潜在的药物靶点,设计新型药物或疫苗,用于治疗感染性疾病、自身免疫性疾病、癌症等疾病。基于受体上的CDR3序列,可以开发高灵敏度和特异性的病毒或细菌诊断试剂盒,用于检测各种疾病的标志物或致病微生物,如HIV、乙肝病毒、流感病毒等。猴在新药的临床前动物实验中扮演重要角色,猴子因其与人类DNA的高相似度而成为理想的实验动物,免疫学研究成果可催生了巨大的经济效益。首先是数据收集和预处理。从企业内部实验数据获取恒河猴的基因组数据,主要是恒河猴通过免疫基因有关引物扩增后的测序数据,格式为Fastq。利用Fastq数据抽取工具,从原始Fastq中抽取100万条序列,采用smalt工具进行序列比对,将这些reads比对到公共数据库的猕猴的免疫有关基因,获取公共数据库对应最相似序列DB_ID,确定实验数据中能够比对到免疫基因上的reads数据,在提交数据文件中包含了readname和reads_seq,这些信息都在原始Fastq中有记录。然后,对每个能比对到公共序列数据库的reads进行注释,获得reads能比对到公共序列上的的起点和终点,即ref_start和ref_end。最后,将这些reads的核苷酸序列翻译为蛋白质,从蛋白质的氨基酸序列中查找CDR3区域,其中CDR3区域是识别抗原的高变区域,这里的CDR3的起始氨基酸选取CA或CG这两种氨基酸序列,终止氨基酸序列为TF,YF,IF,然后找出CDR3序列在reads中的起点和终点,即cdr3_start和cdr3_end,并计算CDR3的核苷酸序列的长度cdr3_length。
By studying the cell receptor sequences of the rhesus macaque immune repertoire, potential drug targets can be screened, and novel drugs or vaccines can be developed for treating infectious diseases, autoimmune diseases, cancer and other diseases. Based on the CDR3 sequences on the receptors, diagnostic kits for viruses or bacteria with high sensitivity and specificity can be developed to detect biomarkers of various diseases or pathogenic microorganisms such as HIV, Hepatitis B Virus, Influenza Virus and others. Rhesus macaques play an important role in preclinical animal trials for new drugs: due to their high genetic similarity to human DNA, they are ideal experimental animals, and immunological research findings can generate substantial economic benefits.
The workflow begins with data collection and preprocessing. First, genomic data of rhesus macaques are acquired from internal enterprise experimental data, primarily sequencing data amplified using primers targeting immune-related genes of rhesus macaques, in Fastq format. A Fastq data extraction tool is used to extract 1,000,000 sequences from the raw Fastq data. Then, the smalt tool is employed for sequence alignment: these reads are aligned to the immune-related genes of rhesus macaques in public databases to obtain the DB_ID of the most similar corresponding sequences in the public databases. Reads that can be aligned to immune genes from the experimental data are identified, and the submitted data files contain readname and reads_seq, both of which are recorded in the original Fastq files.
Next, each read aligned to the public sequence database is annotated to obtain its alignment start and end positions on the reference sequence, namely ref_start and ref_end. Finally, the nucleotide sequences of these reads are translated into protein sequences, and the CDR3 region is identified from the amino acid sequences. The CDR3 region is the hypervariable region responsible for antigen recognition, where the start amino acid sequences of CDR3 are selected as CA or CG, and the stop amino acid sequences are TF, YF and IF. Subsequently, the start and end positions of the CDR3 sequence within the read are determined, namely cdr3_start and cdr3_end, and the length of the CDR3 nucleotide sequence, cdr3_length, is calculated.
提供机构:
墨卓生物科技(浙江)有限公司
创建时间:
2024-07-15
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


