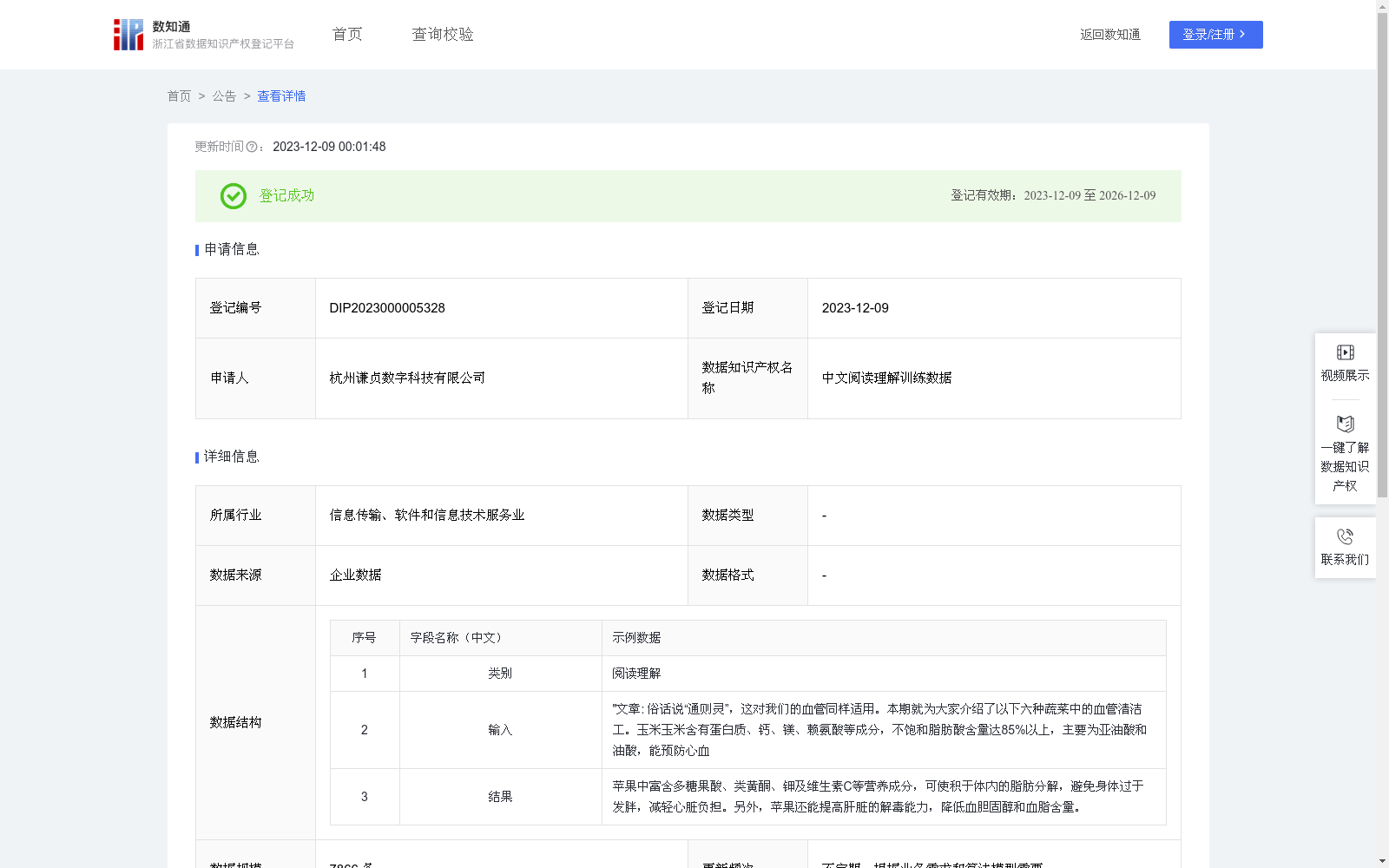
中文阅读理解训练数据
收藏浙江省数据知识产权登记平台2023-12-09 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/17935
下载链接
链接失效反馈官方服务:
资源简介:
1.适用条件与范围
教育技术:在在线教育平台上使用,帮助学生提升阅读理解能力,提供个性化的学习建议。
问答系统:用于开发可以理解和回答基于中文文本的复杂问题的系统,如智能助手。
内容摘要:自动生成新闻、文章或报告的摘要。
企业数据分析:分析企业文档和报告,提取关键信息,辅助决策制定。
法律和合规性检查:分析法律文件,提供相关信息,帮助遵守法律法规。
2.对象
学生和教师:辅助教育过程,提高教学和学习效率。
商业分析师:从大量文本中快速提取商业洞察。
法律专业人士:快速理解和应用法律文档中的信息。
内容创作者:理解和分析已有内容,以产生新的创意。
3.禁用场景
不用于非法目的:禁止用于任何非法活动,如侵犯隐私、欺诈等。
避免生成不当内容:不应用于生成有害、歧视性或令人反感的内容。
数据隐私和安全:在处理敏感信息时必须遵守数据保护法规中文阅读理解任务在自然语言处理(NLP)中是一项挑战,因为它涉及到理解复杂的中文文本,并从中提取或推断信息。以下是中文阅读理解任务的算法规则简要说明:
1. 数据预处理
分词:由于中文写作不使用空格分隔词汇,因此需要通过分词算法将文本分割成单独的词汇。
文本清洗:去除无关字符,如标点符号和特殊字符,标准化文本格式。
2. 语言模型
预训练语言模型:使用如BERT、XLNet等预训练的中文语言模型来理解中文文本的语境和语义。
上下文理解:确保模型能够根据上下文理解词语的多种含义。
3. 特征提取
关键信息标识:识别文本中的关键实体、时间、地点和事件等。
关系和依赖解析:分析词语之间的语法关系和依赖。
4. 理解和推理
文本理解:通过算法理解文本的主题、情感和意图。
逻辑推理:在必要时,进行推理以回答问题或提取信息。
5. 答案生成
答案抽取:从文本中直接抽取答案。
抽象和综合:如果无法直接抽取答案,进行抽象和综合以生成回答。
6. 优化与评估
持续学习:通过新数据和用户反馈不断优化模型。
性能评估:定期评估模型在不同类型文本上的表现。
1. Applicable Conditions and Scope
Educational Technology: To be deployed on online education platforms, helping students improve their reading comprehension abilities and providing personalized learning recommendations.
Question Answering System: Used to develop systems that can understand and answer complex questions based on Chinese text, such as intelligent assistants.
Content Summarization: Automatically generate summaries of news, articles or reports.
Enterprise Data Analysis: Analyze enterprise documents and reports, extract key information to assist decision-making.
Legal and Compliance Review: Analyze legal documents, provide relevant information to help comply with laws and regulations.
2. Target Users
Students and Teachers: Assist in the educational process, improving the efficiency of teaching and learning.
Business Analysts: Rapidly extract business insights from large volumes of text.
Legal Professionals: Quickly understand and apply information contained in legal documents.
Content Creators: Understand and analyze existing content to generate new creative ideas.
3. Prohibited Scenarios
Prohibited for illegal activities: Forbidden to be used for any illegal activities such as privacy infringement, fraud, etc.
Avoid generating inappropriate content: Not to be used to generate harmful, discriminatory or offensive content.
Data Privacy and Security: Must comply with data protection regulations when processing sensitive information.
Chinese Reading Comprehension Task is a challenge in Natural Language Processing (NLP), as it involves understanding complex Chinese text and extracting or inferring information from it. The following is a brief description of the algorithm rules for the Chinese Reading Comprehension Task:
1. Data Preprocessing
Word Segmentation: Since Chinese writing does not use spaces to separate words, a word segmentation algorithm is required to split text into individual lexical units.
Text Cleaning: Remove irrelevant characters such as punctuation and special characters, and standardize the text format.
2. Language Model
Pre-trained Language Model: Use pre-trained Chinese language models such as BERT, XLNet to understand the context and semantics of Chinese text.
Context Understanding: Ensure that the model can comprehend the multiple meanings of words based on the given context.
3. Feature Extraction
Key Information Identification: Identify key entities, times, locations and events in the text.
Relationship and Dependency Parsing: Analyze the grammatical relationships and dependencies between words.
4. Understanding and Reasoning
Text Understanding: Understand the theme, sentiment and intention of the text through algorithms.
Logical Reasoning: Conduct reasoning when necessary to answer questions or extract target information.
5. Answer Generation
Answer Extraction: Directly extract answers from the source text.
Abstraction and Synthesis: If the answer cannot be extracted directly, perform abstraction and synthesis to generate a response.
6. Optimization and Evaluation
Continuous Learning: Continuously optimize the model through new data and user feedback.
Performance Evaluation: Regularly evaluate the model's performance across different types of text.
提供机构:
杭州谦贞数字科技有限公司
创建时间:
2023-11-23
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


