WanJuanCC
收藏魔搭社区2026-05-22 更新2024-06-01 收录
下载链接:
https://modelscope.cn/datasets/Shanghai_AI_Laboratory/WanJuanCC
下载链接
链接失效反馈官方服务:
资源简介:
# WanJuan2.0(WanJuan-CC)

## WanJuan2.0(WanJuan-CC)
WanJuan2.0(WanJuan-CC) 是从CommonCrawl获取的一个 1T Tokens 的高质量英文网络文本数据集。结果显示,与各类开源英文CC语料在 Perspective API 不同维度的评估上,WanJuan2.0 都表现出更高的安全性。此外,通过在4个验证集上的困惑度(PPL)和6下游任务的准确率,也展示了WanJuan2.0 的实用性。WanJuan2.0 在各种验证集上的PPL表现出竞争力,特别是在要求更高语言流畅性的tiny-storys等集上。通过与同类型数据集进行1B模型训练对比,使用验证数据集的困惑度(perplexity)和下游任务的准确率作为评估指标,实验证明,WanJuan2.0 显著提升了英文文本补全和通用英文能力任务的性能。
## 数据处理方法
### 处理流程简述
在WanJuan2.0(WanJuan-CC) 数据集的准备阶段,OpenDataLab团队搭建了一个高性能分布式数据处理框架进行数据的处理,具体的数据处理流程如图所示:
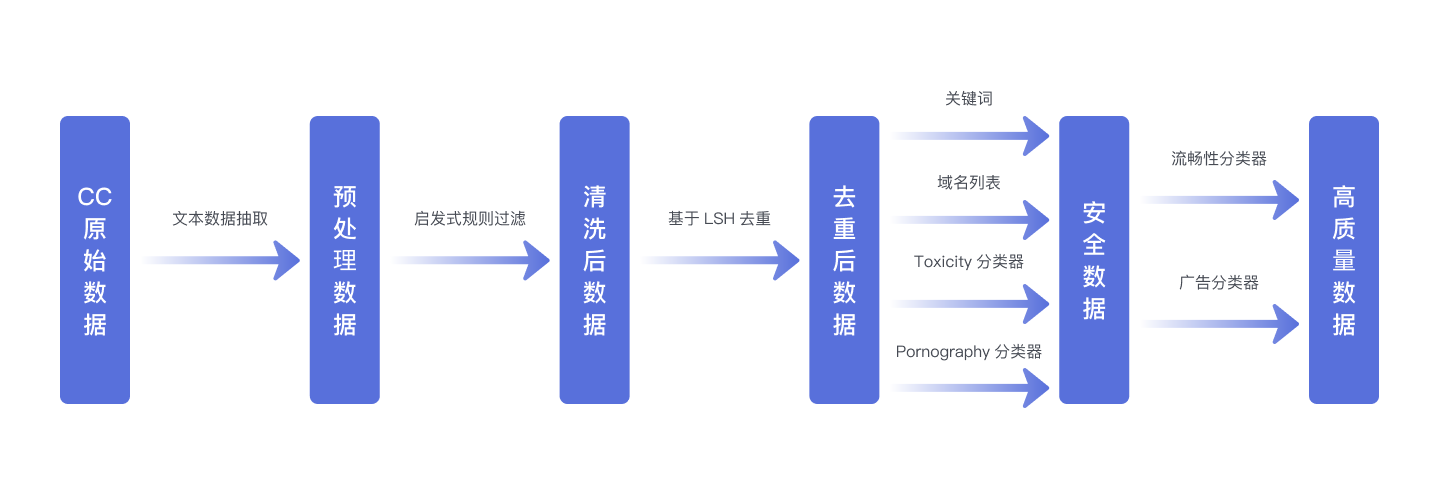
<p align="center">
<b>
WanJuan2.0(WanJuan-CC) 数据处理流程图
</b>
</p>
1. 从Common Crawl的WARC格式数据中提取文本,得到"原始数据"(Raw data)。
2. 通过启发式规则对原始数据进行过滤,生成"清洗数据"(Clean data)。
3. 利用基于LSH的去重方法对清洗数据进行处理,得到"无重复数据"(Dedup data)。
4. 使用基于关键词和域名列表的过滤方法,以及基于Bert的有害内容分类器和淫秽内容分类器对无重复数据进行过滤,产生"安全数据"(Safe data)。
5. 采用基于Bert的广告分类器和流畅性分类器对安全数据进行进一步过滤,得到"高质量数据"(High-Quality data)。
### 各步骤数据留存率
我们统计了各个步骤的文档数量,并绘制了各数据处理步骤的相对去除率与绝对留存率,如下图所示:
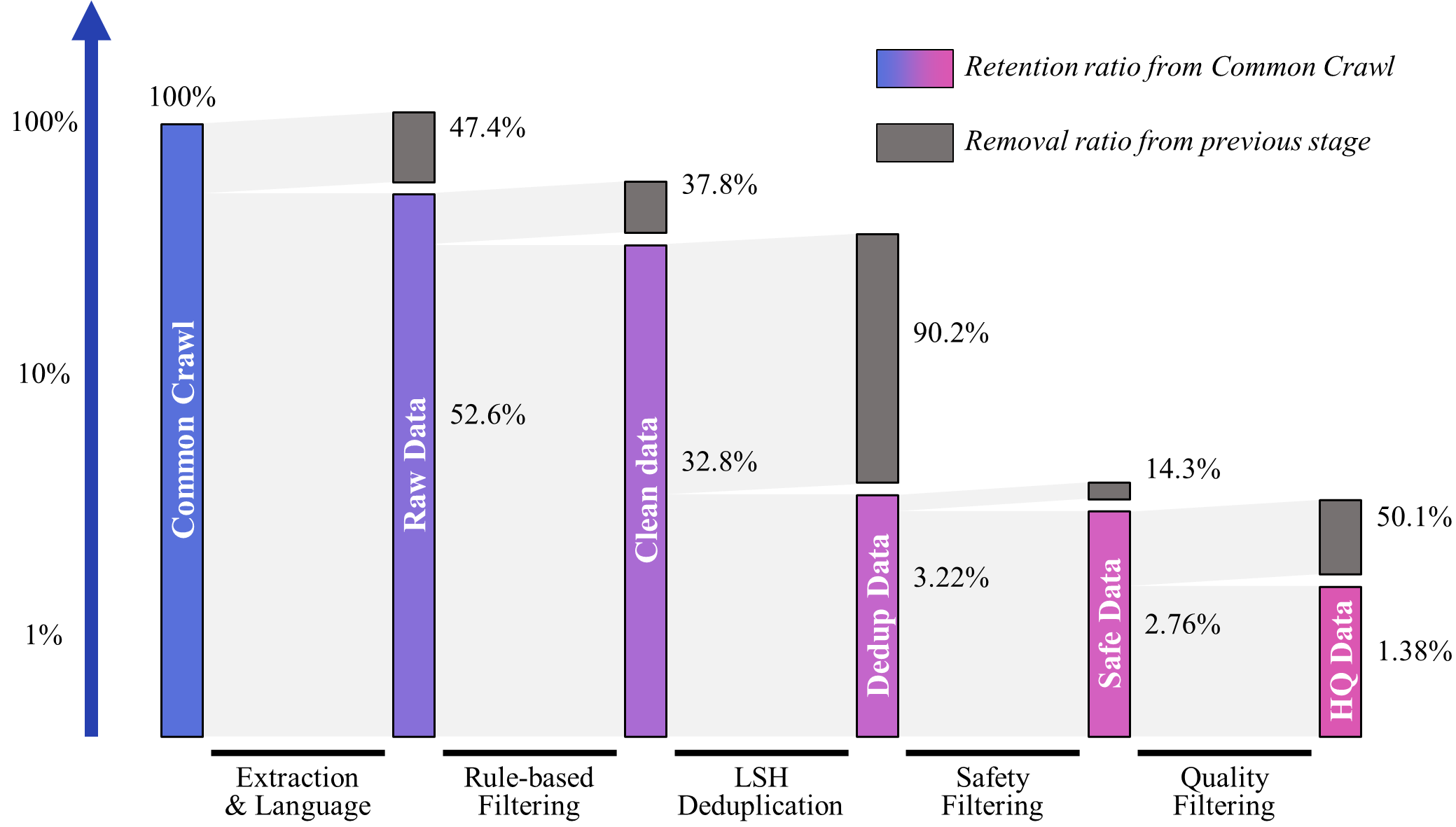
<p align="center">
<b>
WanJuan2.0(WanJuan-CC) 数据处理流程相对去除率和绝对留存率
</b>
</p>
## 数据信息
### 基本信息
- **数据模态**:纯文本数据;
- **主要语言**:英文;
- **数据量**:约 100B Tokens;
- **数据格式**:以Jsonlines形式存储的语料文本与附加信息。
### 数据样例
```json
{
"id": "Bk3aTI85qrqB0ZWjQ26l",
"content": "This year I have been overwhelmed by moving house. The planning and organising has dominated my life: packing and unpacking boxes, trying to keep the family fed and watered, being there 100% for my children to settle in. My life - my aims and goals - have taken second place to the family chaos.\nYesterday, for the first time in ages, I sat down and thought: I want to write my book. I want to get this back into my time schedule. I want to make this space for me, for expressing myself, for being creative.\nSo what happens as of 3.15pm tomorrow? School holidays. Am I really likely to get a moment's peace?\nNow I'm planning: take the laptop on holiday. Work out how to blog from mobile (have to confess this is highly unlikely to work!) Consider booking children into holiday camps for entire 5 weeks. (Would Grannie like them?) Insist on a couple of hours a day, uninterrupted, simply to write.\nOr ... accept the reality. Enjoy the children while they are still prepared to tolerate me. Plan for a solid routine when term starts in September.\nWhich do you think will win?",
"title": "Withenay Wanders: July 2009",
"language": "en",
"date": "2018-06-18T18: 54: 52Z",
"token_num": 244,
"cbytes_num": 1073,
"line_num": 6,
"char_num": 1073,
"toxic_score": 0.001661,
"porn_score": 0.003416,
"fluency_score": 0.998535,
"not_ad_score": 0.981934
}
```
### 数据字段格式
以下表格记录了数据各字段的字段名,意义,数据类型和取值说明:
| 字段名 | 意义 | 数据类型 |取值说明|
| --- | --- | --- | --- |
| id | 唯一标识符 | string |全局唯一标识|
| content | 正文内容 | string |此字段用于预训练|
| title | 标题 | string |网页标题|
| language | 语言 | string | "en" |
| date | 数据日期 | string | "2018-06-18T18: 54: 52Z" |
| token_num | content的token大小 | int | 正整数 |
| cbytes_num | content的字节大小 | int | 正整数 |
| line_num | content的行数,以\n分隔 | int | 正整数 |
| char_num | content的字符大小 | int | 正整数 |
| toxic_score | 毒性评分 | float |[0.0~1.0],高表示毒性可能性高|
| porn_score | 色情评分 | float |[0.0~1.0],高表示色情可能性高|
| fluency_score | 流畅性评分 | float |[0.0~1.0],高表示流畅性好|
| not_ad_score | 非广告评分 | float |[0.0~1.0],高表示非广告可能性高|
### 年份分布
我们统计了WanJuan2.0(WanJuan-CC) 数据集中文档数量,存储空间和Token数量的年份分布,如下图所示:

<p align="center">
<b>
WanJuan2.0(WanJuan-CC) 数据集年份分布
</b>
</p>
### 数据统计信息分布
我们使用了一些统计指标来描述WanJuan2.0(WanJuan-CC) 数据集的一些基本信息,并绘制了百分比直方图如下所示:
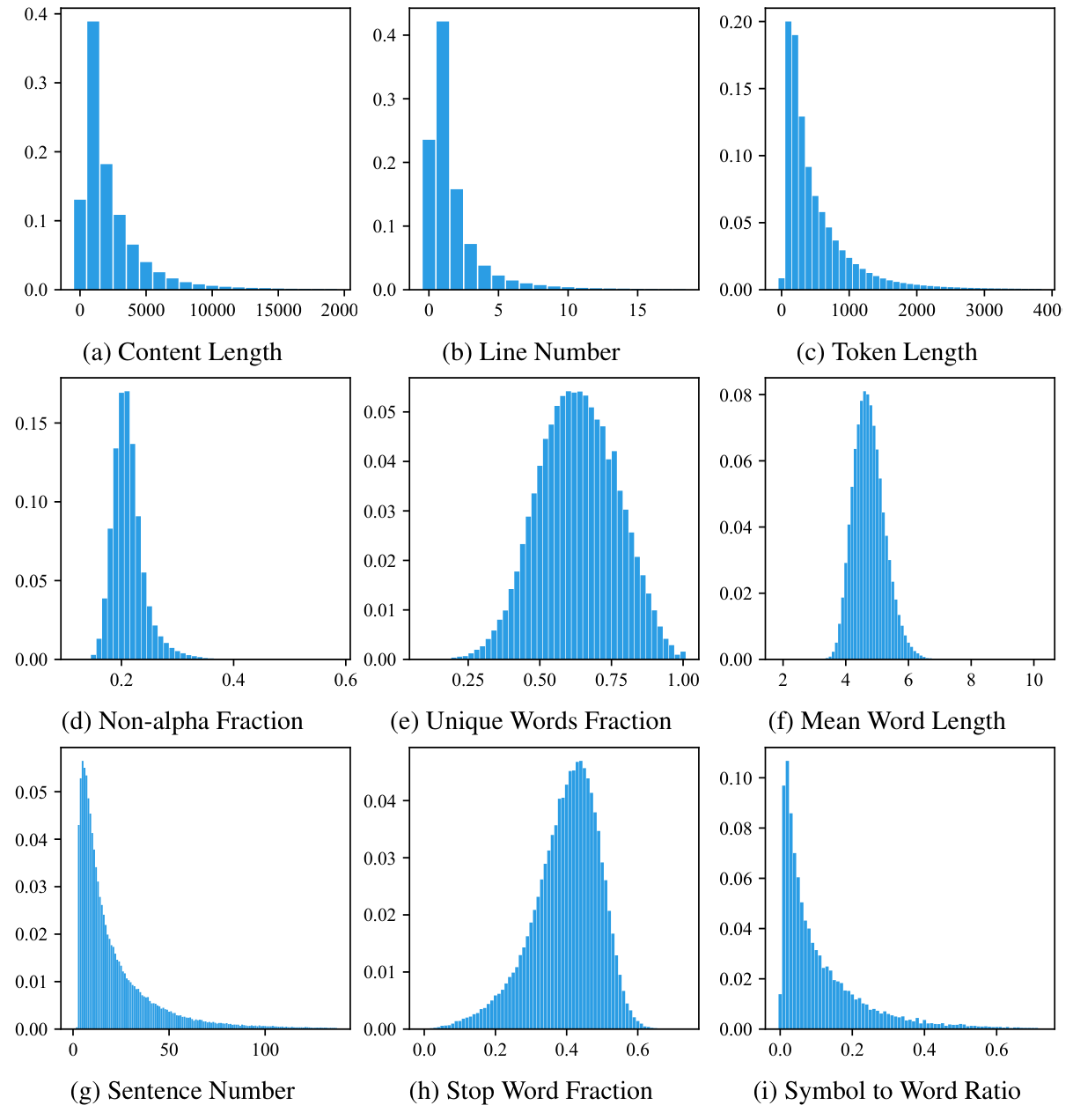
<p align="center">
<b>
WanJuan2.0(WanJuan-CC) 数据集统计信息分布
</b>
</p>
## 下载方法
:modelscope-code[]{type="git"}
## 许可
WanJuan2.0(WanJuan-CC) 整体采用CC BY 4.0许可协议。您可以自由共享、改编该数据集,唯需遵循以下条件:
- 署名:您必须适当地标明作者、提供指向本协议的链接,以及指明是否(对原始数据集)做了修改。您可以以任何合理的方式这样做,但不能以任何方式暗示许可人同意您或您的使用。
- 没有附加限制:您不得使用法律条款或技术措施来限制他人执行许可证允许的任何操作。
完整协议内容,请访问[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)协议全文。
## 特别注意事项
请注意,本数据集的某些子集可能受制于其他协议规定。在使用特定子集之前,请务必仔细阅读相关协议,确保合规使用。更为详细的协议信息,请在特定子集的相关文档或元数据中查看。
OpenDataLab作为非盈利机构,倡导和谐友好的开源交流环境,若在开源数据集内发现有侵犯您合法权益的内容,可发送邮件至([OpenDataLab@pjlab.org.cn](mailto:OpenDataLab@pjlab.org.cn)),邮件中请写明侵权相关事实的详细描述并向我们提供相关的权属证明资料。我们将于3个工作日内启动调查处理机制,并采取必要的措施进行处置(如下架相关数据)。但您应确保您投诉的真实性,否则采取措施后所产生的不利后果应由您独立承担。
## 引文
使用WanJuan2.0(WanJuan-CC),请添加以下引文:
```
@misc{qiu2024wanjuancc,
title={WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset},
author={Jiantao Qiu and Haijun Lv and Zhenjiang Jin and Rui Wang and Wenchang Ning and Jia Yu and ChaoBin Zhang and Zhenxiang Li and Pei Chu and Yuan Qu and Jin Shi and Lindong Lu and Runyu Peng and Zhiyuan Zeng and Huanze Tang and Zhikai Lei and Jiawei Hong and Keyu Chen and Zhaoye Fei and Ruiliang Xu and Wei Li and Zhongying Tu and Hang Yan and Conghui He},
year={2024},
eprint={2402.19282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# 万卷2.0(WanJuan-CC)

## 万卷2.0(WanJuan-CC)
万卷2.0(WanJuan-CC)是一款源自CommonCrawl的高质量英文网络文本数据集,总Token规模达1万亿(1T Tokens)。经多维度评测,相较于各类开源英文CC语料,万卷2.0在Perspective API的各项评估指标中均展现出更优异的安全性。此外,通过在4个验证集上的困惑度(PPL)与6项下游任务的准确率测试,进一步验证了万卷2.0的实用价值。万卷2.0在各类验证集上的PPL表现具备较强竞争力,尤其在tiny-storys这类对语言流畅性要求较高的数据集上优势突出。通过与同类数据集开展1B规模模型的训练对比实验,并以验证集困惑度(perplexity)与下游任务准确率作为评估指标,实验结果表明,万卷2.0显著提升了英文文本补全与通用英文能力任务的模型性能。
## 数据处理方法
### 处理流程概述
在万卷2.0(WanJuan-CC)数据集的筹备阶段,OpenDataLab团队搭建了高性能分布式数据处理框架以完成全流程数据加工,具体处理流程如下方图示:

<p align="center">
<b>
万卷2.0(WanJuan-CC)数据处理流程图
</b>
</p>
1. 从Common Crawl的WARC格式数据中提取文本,得到「原始数据(Raw data)」。
2. 通过启发式规则对原始数据进行过滤,得到「清洗数据(Clean data)」。
3. 利用基于LSH的去重方法处理清洗后的数据,得到「无重复数据(Dedup data)」。
4. 采用基于关键词与域名列表的过滤手段,结合基于Bert的有害内容分类器与色情内容分类器对无重复数据进行过滤,生成「安全数据(Safe data)」。
5. 通过基于Bert的广告分类器与流畅性分类器对安全数据进行二次过滤,得到「高质量数据(High-Quality data)」。
### 各环节数据留存率
我们统计了各处理环节的文档总量,并绘制了数据处理各步骤的相对去除率与绝对留存率图表,如下所示:

<p align="center">
<b>
万卷2.0(WanJuan-CC)数据处理流程相对去除率与绝对留存率
</b>
</p>
## 数据集概况
### 基本信息
- **数据模态**:纯文本;
- **主要语言**:英文;
- **数据规模**:约1000亿(100B)Token;
- **数据格式**:采用Jsonlines格式存储,包含语料文本与附加元信息。
### 数据示例
json
{
"id": "Bk3aTI85qrqB0ZWjQ26l",
"content": "This year I have been overwhelmed by moving house. The planning and organising has dominated my life: packing and unpacking boxes, trying to keep the family fed and watered, being there 100% for my children to settle in. My life - my aims and goals - have taken second place to the family chaos.
Yesterday, for the first time in ages, I sat down and thought: I want to write my book. I want to get this back into my time schedule. I want to make this space for me, for expressing myself, for being creative.
So what happens as of 3.15pm tomorrow? School holidays. Am I really likely to get a moment's peace?
Now I'm planning: take the laptop on holiday. Work out how to blog from mobile (have to confess this is highly unlikely to work!) Consider booking children into holiday camps for entire 5 weeks. (Would Grannie like them?) Insist on a couple of hours a day, uninterrupted, simply to write.
Or ... accept the reality. Enjoy the children while they are still prepared to tolerate me. Plan for a solid routine when term starts in September.
Which do you think will win?",
"title": "Withenay Wanders: July 2009",
"language": "en",
"date": "2018-06-18T18: 54: 52Z",
"token_num": 244,
"cbytes_num": 1073,
"line_num": 6,
"char_num": 1073,
"toxic_score": 0.001661,
"porn_score": 0.003416,
"fluency_score": 0.998535,
"not_ad_score": 0.981934
}
### 数据字段规范
下表详细记录了各数据字段的字段名、含义、数据类型及取值说明:
| 字段名 | 含义 | 数据类型 | 取值说明 |
| --- | --- | --- | --- |
| id | 唯一标识符 | string | 全局唯一标识 |
| content | 正文内容 | string | 该字段用于模型预训练 |
| title | 标题 | string | 网页标题 |
| language | 语言 | string | 固定取值为`"en"` |
| date | 数据日期 | string | 格式示例:`"2018-06-18T18:54:52Z"` |
| token_num | 正文Token数量 | int | 正整数 |
| cbytes_num | 正文字节数 | int | 正整数 |
| line_num | 正文行数(以`
`分隔) | int | 正整数 |
| char_num | 正文字符数 | int | 正整数 |
| toxic_score | 毒性评分 | float | 取值范围`[0.0~1.0]`,分值越高代表毒性风险越高 |
| porn_score | 色情评分 | float | 取值范围`[0.0~1.0]`,分值越高代表色情内容风险越高 |
| fluency_score | 流畅性评分 | float | 取值范围`[0.0~1.0]`,分值越高代表文本流畅性越好 |
| not_ad_score | 非广告评分 | float | 取值范围`[0.0~1.0]`,分值越高代表非广告内容可能性越高 |
### 年份分布情况
我们统计了万卷2.0(WanJuan-CC)数据集中文档总量、存储空间与Token规模的年度分布情况,如下方图示:

<p align="center">
<b>
万卷2.0(WanJuan-CC)数据集年度分布
</b>
</p>
### 数据集统计信息分布
我们采用多项统计指标刻画万卷2.0(WanJuan-CC)数据集的基础特征,并绘制了对应的百分比直方图,如下所示:

<p align="center">
<b>
万卷2.0(WanJuan-CC)数据集统计信息分布
</b>
</p>
## 获取方式
:modelscope-code[]{type="git"}
## 授权协议
万卷2.0(WanJuan-CC)整体采用CC BY 4.0授权协议。您可自由对该数据集进行共享与改编,但需遵守以下条款:
- 署名要求:您需以合理方式标注原作者、提供本协议的链接,并明确说明是否对原始数据集进行了修改。您可通过任何合理途径完成标注,但不得通过任何方式暗示原许可方认可您或您的使用行为。
- 无额外限制:您不得通过法律条款或技术手段限制他人行使本协议所允许的任何权利。
完整协议内容请访问[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)协议官方页面。
## 重要提示
请注意,本数据集的部分子集可能受其他协议约束。在使用特定子集前,请务必仔细阅读相关协议条款,确保合规使用。更详细的协议信息可在对应子集的文档或元数据中查阅。
OpenDataLab作为非营利机构,倡导和谐友好的开源交流氛围。若您认为本开源数据集内存在侵犯您合法权益的内容,可发送邮件至[OpenDataLab@pjlab.org.cn](mailto:OpenDataLab@pjlab.org.cn),邮件中请详细描述侵权相关事实,并提供相关权属证明材料。我们将在3个工作日内启动调查处理流程,并采取必要措施(如下架相关数据)进行处置。但请您确保投诉内容真实可信,否则由此产生的不利后果将由您自行承担。
## 引用规范
若使用万卷2.0(WanJuan-CC)数据集,请添加如下引用信息:
@misc{qiu2024wanjuancc,
title={WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset},
author={Jiantao Qiu and Haijun Lv and Zhenjiang Jin and Rui Wang and Wenchang Ning and Jia Yu and ChaoBin Zhang and Zhenxiang Li and Pei Chu and Yuan Qu and Jin Shi and Lindong Lu and Runyu Peng and Zhiyuan Zeng and Huanze Tang and Zhikai Lei and Jiawei Hong and Keyu Chen and Zhaoye Fei and Ruiliang Xu and Wei Li and Zhongying Tu and Hang Yan and Conghui He},
year={2024},
eprint={2402.19282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
提供机构:
maas
创建时间:
2024-05-17


