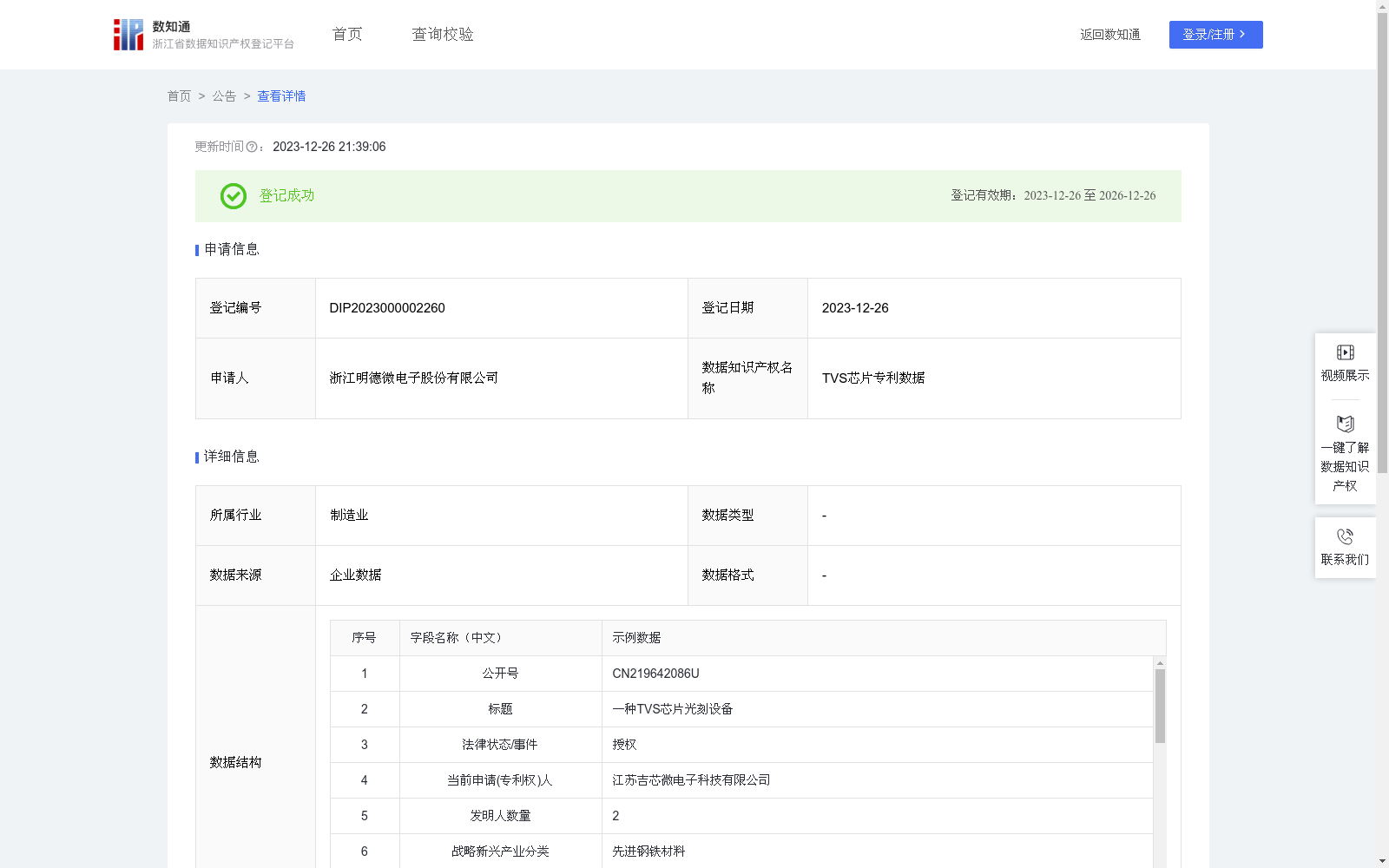
TVS芯片专利数据
收藏浙江省数据知识产权登记平台2023-12-26 更新2024-05-08 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/23052
下载链接
链接失效反馈官方服务:
资源简介:
通过收集TVS芯片领域专利申请人、法律状态、技术主题分类、简单同族成员数量等数据,形成了主要包括全球专利数据库中与TVS芯片相关的发明专利和实用新型专利数据,在结果中筛选关键词TVS芯片,找出TVS芯片方向专利数据,并根据自有算法对专利数据进行了评价和分类,可用于了解TVS芯片专利数据变化情况,有助于了解TVS芯片知识产权工作成果;通过对各企业/个人TVS芯片专利数据的对比,可了解各企业/个人的技术创新能力、创新水平差异;了解TVS芯片的技术发展趋势,有助于企业避免重复研发,避免企业开发的技术侵犯他人的知识产权。1、数据来源:全球专利数据库中与汽TVS芯片相关的发明专利和实用新型专利数据;2、数据采集:本数据目标层为专利技术相关性,指标层是将专利技术相关性指标体系分为市场、技术、法律、战略、经济五大价值维度,是检索出有关于TVS芯片的专利,指标层向下分准则层,包括:技术价值:IPC分类数量、被引用专利数量、授权年限;经济价值:剩余年数、质押次数;法律价值:权利要求数、文献页数;战略价值:发明人数量、简单同族成员数量;市场价值:技术主题分类数、专利类型、是否战略新兴产业。3、数据分析:本数据基于AHP层次法,采用定量与定性相结合,将技术关联性按从高到低分为(A、B、C),A为高关联性、B为一般关联性、C为较低关联性。采用综合分值法:战略价值≥50分及以上、经济价值≥20分及以上、市场价值≥50分及以上、法律价值≥60分及以上、技术价值≥30分及以上为A,战略价值40-50分(不含50分)、经济价值≥20分及以上、市场价值≥30分及以上、法律价值≥70分及以上、技术价值≥30分及以上为B,其余为C;4、数据应用:为本领域技术人员提供研发决策依据和技术规避作优先参考。
提供机构:
浙江明德微电子股份有限公司
创建时间:
2023-10-24
搜集汇总
数据集介绍
特点
TVS芯片专利数据集包含200条记录,每年更新一次,涵盖了全球专利数据库中与TVS芯片相关的发明专利和实用新型专利。数据集详细列出了专利的多个维度,如公开号、标题、法律状态等,适用于分析TVS芯片的技术发展趋势和企业技术创新能力。
以上内容由遇见数据集搜集并总结生成


