RECOR
收藏Hugging Face2026-01-13 更新2026-01-14 收录
下载链接:
https://huggingface.co/datasets/RECOR-Benchmark/RECOR
下载链接
链接失效反馈官方服务:
资源简介:
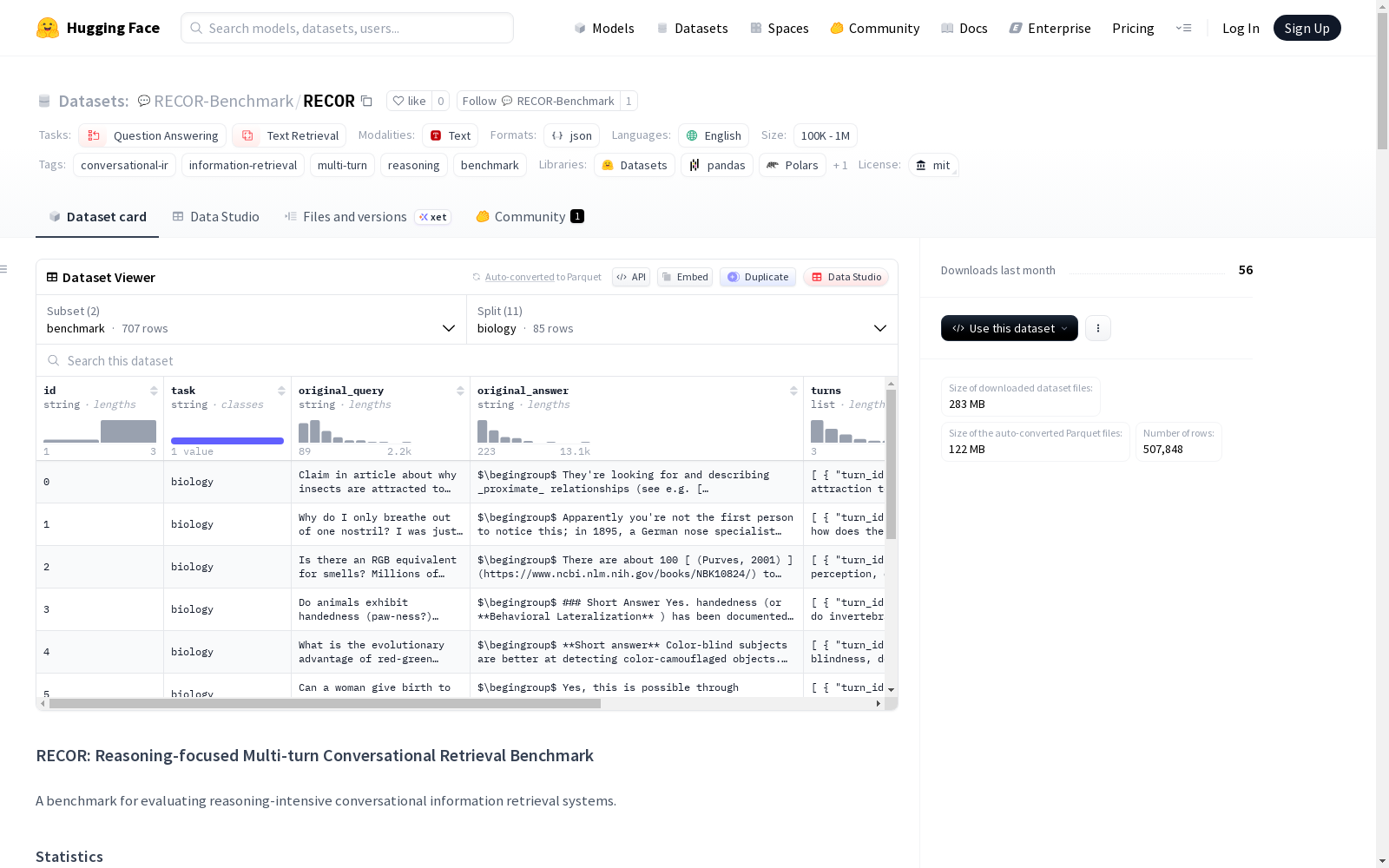
RECOR Benchmark是一个专注于评估推理密集型对话信息检索系统的多轮对话检索基准数据集。它包含两个主要子集:benchmark(707个多轮对话)和corpus(文档语料库,包含正面和负面文档)。数据集覆盖11个领域,包括生物学、地球科学、经济学、心理学、机器人学、可持续生活、无人机、硬件、法律、医学科学和政治学。每个对话包含多个回合,每个回合有用户问题、答案、相关文档ID、对话历史、子问题推理等字段。文档语料库包含文档ID和内容。数据集结构清晰,提供了详细的字段描述和使用示例。
创建时间:
2026-01-08
原始信息汇总
RECOR 数据集概述
数据集基本信息
- 数据集名称: RECOR Benchmark
- 托管地址: https://huggingface.co/datasets/RECOR-Benchmark/RECOR
- 许可证: MIT License
- 主要任务类别: 问答、文本检索
- 语言: 英语
- 规模: 1K<n<10K
- 标签: 会话式信息检索、信息检索、多轮对话、推理、基准测试
数据集构成与统计
整体统计
- 总对话数: 707
- 总轮次数: 2,971
- 领域数: 11
- 平均每对话轮次数: 4.2
领域划分与统计
数据来源与领域:
- BRIGHT: biology, earth_science, economics, psychology, robotics, sustainable_living
- StackExchange: Drones, hardware, law, medicalsciences, politics
各领域详细统计:
| 领域 | 对话数 | 轮次数 |
|---|---|---|
| biology | 85 | 362 |
| earth_science | 98 | 454 |
| economics | 74 | 288 |
| psychology | 84 | 333 |
| robotics | 68 | 259 |
| sustainable_living | 78 | 319 |
| Drones | 37 | 142 |
| hardware | 46 | 188 |
| law | 50 | 230 |
| medicalsciences | 44 | 183 |
| politics | 43 | 213 |
数据集结构
子集配置
数据集包含两个主要子集:
- benchmark: 包含707个多轮对话,用于推理密集型会话信息检索系统的评估。
- corpus: 文档语料库(包含正负文档)。
每个子集均按上述11个领域进行划分。
数据字段说明
Benchmark(对话)字段:
id: 唯一对话标识符task: 领域名称original_query: 初始用户问题original_answer: 对初始问题的回答turns: 对话轮次列表metadata: 对话元数据
Metadata 元数据字段:
num_turns: 对话轮次数gold_doc_count: 相关文档总数version: 数据集版本created_at: 创建时间戳source: 数据来源(bright 或 annotated_data)method: 生成方法
每个对话轮次(turn)包含的字段:
turn_id: 轮次编号(从1开始)query: 当前轮次的用户问题answer: 黄金答案gold_doc_ids: 相关文档ID列表conversation_history: 先前轮次的上下文subquestion_reasoning: 后续问题的推理过程subquestion_reasoning_metadata: 结构化推理元数据
subquestion_reasoning_metadata 推理元数据字段:
target_information: 查询所寻求的信息relevance_signals: 表示相关性的关键词/概念irrelevance_signals: 表示不相关性的关键词/概念
Corpus(文档)字段:
doc_id: 唯一文档标识符content: 文档文本
文件结构
data/ ├── benchmark/ # 对话数据(11个文件) │ └── {domain}_benchmark.jsonl └── corpus/ # 文档数据(11个文件) └── {domain}_documents.jsonl
使用方式
可通过 datasets 库加载特定领域或全部领域的数据。支持加载的领域包括:biology, earth_science, economics, psychology, robotics, sustainable_living, Drones, hardware, law, medicalsciences, politics。
评估
评估代码和指标请参考 GitHub 仓库:https://github.com/RECOR-Benchmark/RECOR。
搜集汇总
数据集介绍
构建方式
在信息检索领域,为评估系统在多轮对话中处理复杂推理任务的能力,RECOR数据集通过精心设计的流程构建而成。该数据集整合了来自BRIGHT和StackExchange两大知识源的11个专业领域内容,涵盖生物学、地球科学、经济学、心理学、机器人学、可持续生活,以及无人机、硬件、法律、医学科学和政治学。构建过程中,研究人员首先从这些领域收集原始对话和文档,随后通过人工标注与结构化处理,为每个对话回合添加了详细的推理元数据,包括目标信息、相关性信号和非相关性信号,从而形成了包含707段对话、总计2971个回合的高质量多轮对话语料。
特点
RECOR数据集的核心特征在于其专注于推理密集型对话检索任务,为信息检索研究提供了独特的评估基准。数据集不仅覆盖了广泛的学科领域,确保了内容的多样性和专业性,还通过平均每段对话4.2个回合的结构,模拟了真实场景中用户逐步深入追问的交互模式。每个对话回合均配备了精细的标注信息,如子问题推理及其元数据,这使研究者能够深入分析系统在理解上下文、识别相关文档和进行逻辑推理方面的表现。此外,数据集将对话语料与文档语料分离,支持对检索模型在跨领域、多轮次情境下的性能进行全面测评。
使用方法
使用RECOR数据集时,研究者可通过Hugging Face的datasets库便捷加载特定领域或全部数据。例如,调用load_dataset函数并指定配置为'benchmark'或'corpus',即可分别获取对话数据或文档集合;通过split参数可选择具体领域,如生物学或法律。在对话数据中,每个条目包含完整的多轮交互历史、答案及相关的文档ID,用户可依据这些ID从对应领域的文档语料中检索出正负例文档,以构建训练或测试集。数据集的模块化结构支持灵活的迭代访问,便于开发者在不同学科背景下评估对话检索系统的推理能力与泛化性能。
背景与挑战
背景概述
在信息检索与对话系统融合发展的背景下,多轮对话检索成为人工智能领域的前沿课题。RECOR基准数据集由RECOR-Benchmark团队创建,专注于评估推理密集型会话信息检索系统。该数据集整合了来自BRIGHT和StackExchange两大平台的707个多轮对话,涵盖生物学、地球科学、经济学、心理学、机器人学、可持续生活以及无人机、硬件、法律、医学科学、政治等11个专业领域,共计2971个对话轮次。其核心研究问题在于如何通过复杂的多轮交互,模拟真实场景中用户基于上下文进行深度推理的信息需求,从而推动对话检索系统在理解、推理与知识整合方面的能力提升,对自然语言处理与信息检索交叉领域具有重要的基准价值。
当前挑战
RECOR数据集旨在解决多轮对话信息检索中推理能力的挑战,这要求系统不仅能理解单轮查询的语义,还需追踪对话历史,解析用户隐含的推理逻辑,例如通过子问题推理元数据中的目标信息与相关性信号进行动态文档匹配。构建过程中的挑战包括多领域专业知识的整合,需确保生物学、法律等不同学科文档的准确性与代表性;对话数据的自然性与复杂性平衡,人工标注或生成多轮对话时需维持逻辑连贯性与真实交互模式;以及正负文档语料库的构建,需精确识别相关与无关文档以支持可靠的系统评估。
常用场景
经典使用场景
在信息检索与对话系统领域,RECOR数据集为评估多轮对话中的推理密集型检索任务提供了标准化的测试平台。该数据集通过涵盖生物学、经济学、心理学、机器人学等11个专业领域的多轮对话,模拟了用户在复杂信息需求下的交互过程。每个对话回合不仅包含用户查询与标准答案,还标注了推理链条与相关文档标识,使得研究者能够深入分析系统在理解上下文、进行逻辑推理以及精准检索方面的性能。这种结构化的设计使得RECOR成为推动对话式信息检索技术发展的核心资源。
实际应用
RECOR数据集的实际应用场景广泛涉及智能助手、专业咨询系统与教育技术领域。例如,在医疗或法律等专业咨询中,系统需要基于多轮对话理解用户的深层需求,并通过推理从海量文档中检索出精准信息。该数据集提供的多领域对话与文档库,能够帮助开发者训练和优化系统,使其在真实场景中更好地处理专业性强、逻辑复杂的用户查询,提升服务的准确性与交互的自然度,从而推动智能化信息服务的落地与普及。
衍生相关工作
围绕RECOR数据集,已衍生出一系列经典研究工作,主要集中在增强型检索模型与对话推理架构的开发上。例如,研究者利用该数据集的推理标注,提出了结合图神经网络与注意力机制的检索模型,以更好地捕捉对话中的逻辑关系。同时,基于RECOR的评估框架也催生了多种针对多轮对话的检索算法,如上下文感知的重新排序技术与动态查询扩展方法。这些工作不仅深化了对对话式检索的理解,也为后续更复杂的跨领域推理任务奠定了基础。
以上内容由遇见数据集搜集并总结生成


