dpohl/wmt19_de-distill
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/dpohl/wmt19_de-distill
下载链接
链接失效反馈官方服务:
资源简介:
---
dataset_info:
- config_name: student
features:
- name: source
dtype: string
- name: output
dtype: string
- name: messages
list:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: train
num_bytes: 1956035
num_examples: 5000
- name: dev
num_bytes: 398165
num_examples: 1000
- name: test
num_bytes: 440602
num_examples: 1000
- name: train_hard
num_bytes: 744930
num_examples: 5000
download_size: 2110474
dataset_size: 3539732
- config_name: teacher
features:
- name: source
dtype: string
- name: output
dtype: string
- name: messages
list:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: train
num_bytes: 3846639
num_examples: 10000
- name: dev
num_bytes: 376517
num_examples: 1000
- name: test
num_bytes: 435261
num_examples: 1000
download_size: 2920842
dataset_size: 4658417
configs:
- config_name: student
data_files:
- split: train
path: student/train-*
- split: dev
path: student/dev-*
- split: test
path: student/test-*
- split: train_hard
path: student/train_hard-*
- config_name: teacher
data_files:
- split: train
path: teacher/train-*
- split: dev
path: teacher/dev-*
- split: test
path: teacher/test-*
---
提供机构:
dpohl
搜集汇总
数据集介绍
构建方式
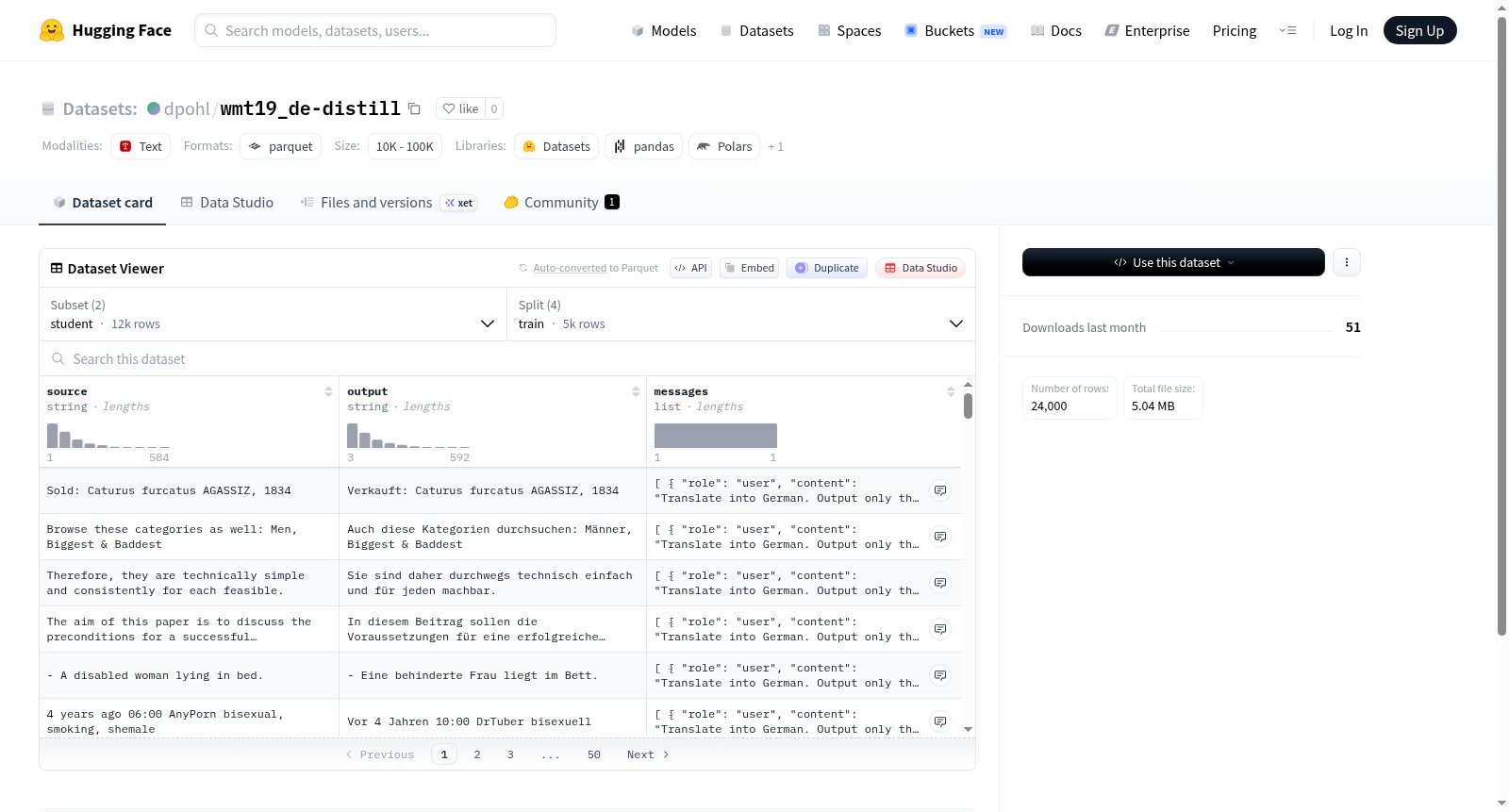
该数据集基于WMT19德语到英语翻译任务的机器翻译数据,通过知识蒸馏技术构建。其中包含两个配置:student和teacher。student配置包含5000条训练样本、1000条验证样本和1000条测试样本,以及额外的5000条train_hard样本;teacher配置包含10000条训练样本、1000条验证样本和1000条测试样本。每条样本包含source字段(源语言文本)、output字段(目标语言译文)以及messages字段(对话形式的多轮交互结构,由role和content组成),为模型训练提供结构化的翻译数据。
使用方法
使用时可通过HuggingFace Datasets库加载指定配置,如load_dataset('wmt19_de-distill', 'student')或load_dataset('wmt19_de-distill', 'teacher')。对于翻译任务,可直接利用source和output字段进行序列到序列训练;对于对话模型微调,则可解析messages字段中的角色和内容,构建多轮对话数据。train_hard子集适用于对抗训练或难例挖掘场景,提升模型的鲁棒性。
背景与挑战
背景概述
在神经机器翻译领域,知识蒸馏技术作为一种模型压缩与性能提升的关键手段,近年来受到广泛关注。wmt19_de-distill数据集由学术研究机构于2019年基于WMT19英德翻译任务构建,核心研究问题聚焦于探索教师-学生框架下的翻译知识迁移效率。该数据集通过对比教师模型(teacher)与学生模型(student)的输出差异,为评估蒸馏策略对翻译质量、推理速度与模型鲁棒性的影响提供了标准化基准。其影响力体现在推动了轻量级翻译模型的实用化进程,尤其在资源受限场景中降低了部署门槛。
当前挑战
该数据集面临的核心挑战包括:其一,翻译准确性难题,即学生模型在压缩过程中需尽可能保留教师模型的翻译质量,避免因参数精简导致的语义丢失或语法错误;其二,蒸馏策略的适配性问题,不同蒸馏目标(如软标签、隐层状态对齐)对学生模型的泛化能力影响未获系统解析;其三,数据构建阶段对训练样本难度分级(如train_hard子集)的合理性存疑,复杂样本的蒸馏增益与计算成本之间的平衡需进一步验证。
常用场景
经典使用场景
在神经机器翻译的璀璨星空中,wmt19_de-distill 数据集犹如一颗精心雕琢的明珠,其经典用途聚焦于知识蒸馏技术的验证与优化。该数据集精心设计了“学生”与“教师”两种配置,其中“教师”配置包含更大规模且更高质量的翻译样例,而“学生”配置则包含精简后的训练样本。研究者通常利用这一结构,训练一个轻量级的学生模型去模仿一个强大但计算昂贵的教师模型的行为,从而在保持翻译质量的前提下,大幅降低模型参数量和推理延迟。
解决学术问题
该数据集直面机器翻译领域中的一个核心困境:如何在模型压缩与性能保真之间取得优雅平衡。通过提供标准化的蒸馏训练与评估基准,它有效解决了传统知识蒸馏研究中因数据集不一致而导致的结论泛化性不足的问题。wmt19_de-distill 的出现,使得学术界能够系统地探讨蒸馏温度、软标签分布与模型容量之间的微妙关系,推动了轻量化翻译模型在资源受限环境下的理论突破,为边缘设备上的实时翻译提供了坚实的数据基础。
实际应用
在工业界的落地实践中,wmt19_de-distill 数据集扮演着桥梁角色,连接着学术理论与产品需求。它被广泛用于开发面向移动终端和嵌入式系统的快速翻译引擎。例如,智能手机上的离线翻译应用、会议同传的实时字幕生成,以及智能穿戴设备的语音交互翻译,均受益于基于该数据集训练的紧凑型模型。这些应用场景对响应速度和存储空间有着严苛要求,而该数据集提供的蒸馏路线图,使得高精度翻译能以近乎无损的形态嵌入到毫瓦级功耗的晶片之中。
数据集最近研究
最新研究方向
在神经机器翻译领域,wmt19_de-distill数据集作为蒸馏技术的典范,正引领着模型轻量化与效率提升的潮流。该数据集通过师生框架(student与teacher配置)设计,核心聚焦于知识蒸馏——一种将大型教师模型的能力高效压缩至小型学生模型的前沿方法。当前研究热点集中在利用此类蒸馏数据训练出性能逼近教师的学生模型,同时显著降低推理时延与计算开销。结合边缘计算与实时翻译服务的迫切需求,该数据集成为解决资源受限场景下翻译模型部署难题的关键资源。其训练集包含5000条学生样本与10000条教师样本,配合train_hard子集强化困难样例学习,推动了低资源语言对之间的稳健翻译能力。这一工作不仅加速了模型压缩技术的实证研究,还为多模态翻译与少样本学习提供了高保真数据支撑,对构筑更绿色的AI翻译生态系统具有深远意义。
以上内容由遇见数据集搜集并总结生成


