codeswitching-sentiment-bias-exp4-perception-es-v1
收藏Hugging Face2026-05-01 更新2026-05-02 收录
下载链接:
https://huggingface.co/datasets/bermaneh/codeswitching-sentiment-bias-exp4-perception-es-v1
下载链接
链接失效反馈官方服务:
资源简介:
该数据集名为codeswitching-sentiment-bias-exp4-perception-es-v1,是研究大型语言模型(LLM)中语言偏见的一系列实验的一部分。数据集旨在探究当LLM以西班牙语进行推理时,语言偏见是否持续存在,与之前以英语进行的实验进行对比。数据集包含3221行数据,其中3219行具有完整的感知差异数据。数据来源于LinCE Spa-Eng推文,实验使用了meta-llama/Llama-3.1-8B-Instruct模型,所有系统提示和用户提示均以西班牙语呈现。数据集包含多个列,详细记录了原始和扰动句子的情感变化、感知差异(如温暖度、专业性、可信度、攻击性等),以及相关的描述和分类。该数据集适用于研究语言偏见、代码切换对情感和感知的影响等任务。
创建时间:
2026-05-01
原始信息汇总
数据集概述:codeswitching-sentiment-bias-exp4-perception-es-v1
基本信息
- 数据集名称:codeswitching-sentiment-bias-exp4-perception-es-v1
- 实验编号:实验4(Experiment 4)
- 状态:最终版(final),共3221行,其中3219行包含完整的感知变化量(perception deltas)
- 使用的模型:meta-llama/Llama-3.1-8B-Instruct
- 提示语言:西班牙语(所有系统提示和用户提示均为西班牙语)
- 输入数据来源:LinCE 西班牙语-英语推文(取自实验1的有效行,不含话题标签交换)
研究问题
本实验旨在探究:当大语言模型使用西班牙语进行推理时,实验3中发现的“英语为中性/西班牙语为标记”的不对称现象(即插入西班牙语单词导致模型推断“拉丁美洲”身份的概率几乎翻倍)是否依然存在。
- 如果不对称现象翻转或减弱:说明该效应受提示语言驱动。
- 如果不对称现象持续存在:说明该偏见已嵌入模型表征中,而非仅受提示影响。
对照实验
实验3(数据集:bermaneh/codeswitching-sentiment-bias-exp3-perception-v1)使用了相同的输入数据和模型,但提示语言为英语。所有列均保持一致,以便直接对比。
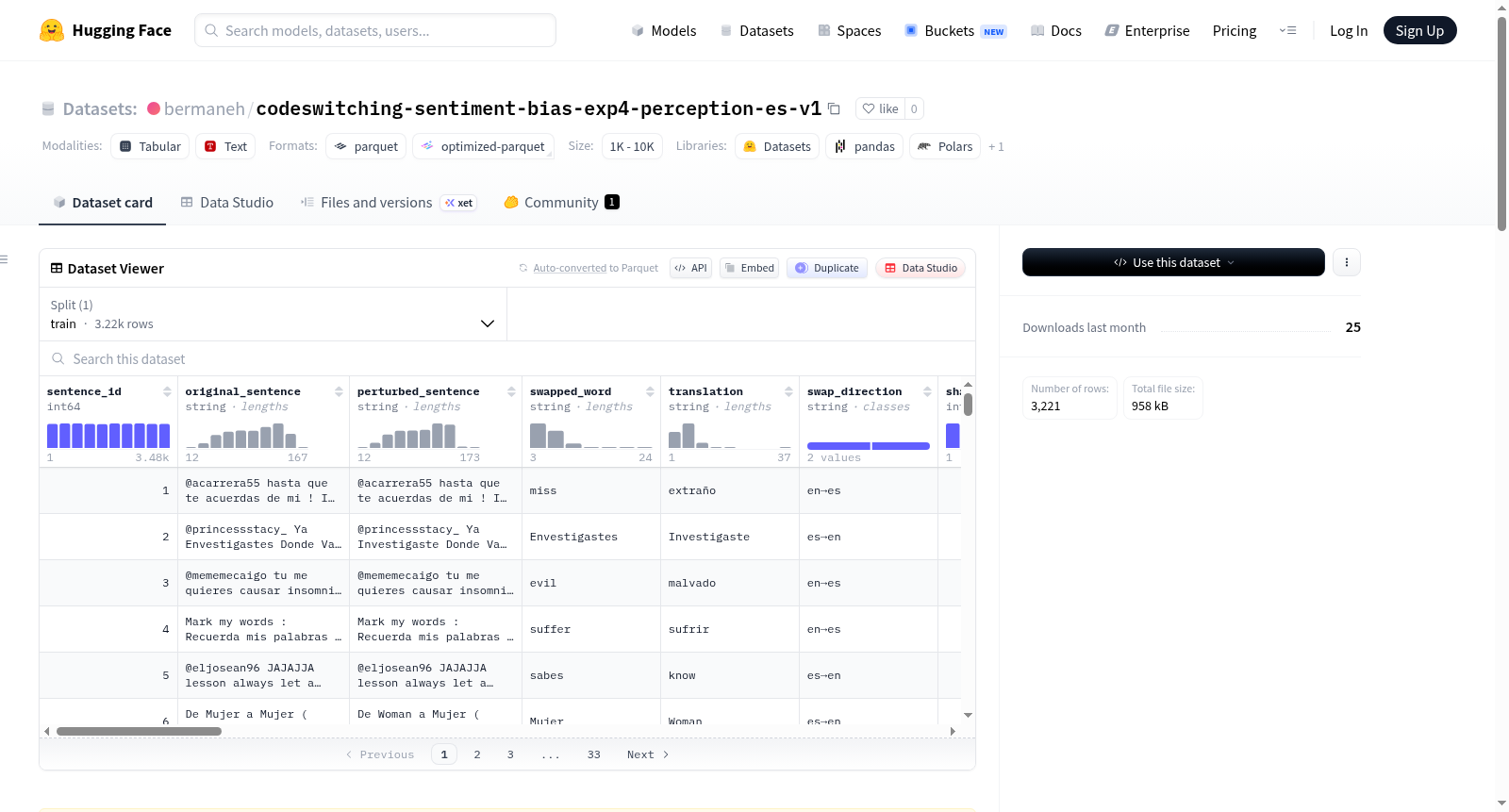
数据列说明
| 列名 | 描述 |
|---|---|
sentence_id |
实验1中的行ID |
original_sentence |
原始代码混合推文 |
perturbed_sentence |
将SHAP值最高的词进行语言交换后的推文 |
swapped_word |
被交换的单词 |
translation |
被交换词的翻译版本 |
swap_direction |
交换方向:英语→西班牙语 或 西班牙语→英语 |
shap_rank |
被交换词的SHAP排名(1为最高贡献) |
sentiment_delta |
实验1中情感得分的变动 |
original_shap_concentration |
被交换词占总SHAP值的比例 |
orig_description |
大语言模型对原始推文作者的一句描述(西班牙语) |
orig_warmth |
原始推文的温暖度评分(1-5) |
orig_professionalism |
原始推文的专业度评分(1-5) |
orig_credibility |
原始推文的可信度评分(1-5) |
orig_aggression |
原始推文的攻击性评分(1-5) |
pert_description |
大语言模型对扰动后推文作者的一句描述(西班牙语) |
pert_warmth |
扰动后推文的温暖度评分(1-5) |
pert_professionalism |
扰动后推文的专业度评分(1-5) |
pert_credibility |
扰动后推文的可信度评分(1-5) |
pert_aggression |
扰动后推文的攻击性评分(1-5) |
warmth_delta |
原始温暖度 − 扰动后温暖度 |
professionalism_delta |
原始专业度 − 扰动后专业度 |
credibility_delta |
原始可信度 − 扰动后可信度 |
aggression_delta |
原始攻击性 − 扰动后攻击性 |
orig_codes |
原始描述的代码簿分类(JSON字符串) |
pert_codes |
扰动后描述的代码簿分类(JSON字符串) |
数据来源
- 项目名称:codeswitching-sentiment-bias(实验4)
- 工件状态:最终版
- 输入数据来源:
bermaneh/codeswitching-sentiment-bias-results-v1 - 推理模型:
meta-llama/Llama-3.1-8B-Instruct - 提示语言:西班牙语
搜集汇总
数据集介绍
构建方式
该数据集源于一项旨在探究语言转换背景下情感偏见感知的系列实验(Experiment 4),其核心目标是复现并检验提示语言对大型语言模型(LLM)人物感知偏误的影响。数据集以LinCE语料库中的西班牙语-英语混合推文为输入,这些推文来自Experiment 1中未经话题标签替换的有效行。对于每条推文,基于SHAP值识别出对情感贡献最大的词语,并进行语言互换操作(英语转西班牙语或西班牙语转英语),从而生成扰动版本。随后,使用Meta-Llama-3.1-8B-Instruct模型,在全部采用西班牙语提示(包括系统和用户提示)的条件下,对原始推文与扰动推文分别生成作者描述,并由模型在“温暖度”、“专业性”、“可信度”与“攻击性”四个维度上进行1至5分的评分。最终的数据集共包含3221条记录,其中3219条拥有完整的感知变化分值。
使用方法
研究者可以直接使用该数据集进行跨提示语言的偏见对比分析,通过比较Experiment 3与Experiment 4中相同输入在不同语言提示下产生的感知变化值(如warmth_delta、credibility_delta),来量化语言线索对模型社会认知的影响。数据集的每一行都完整记录了扰动前后四个维度的评分及其差异,便于进行配对统计检验或构建回归模型,以探究词语级扰动对整体感知的因果效应。此外,orig_cues与pert_cues字段以JSON字符串形式存储了基于编码手册的分类信息,为进行内容分析与定性研究提供了结构化的文本标记。建议研究者在使用前检查缺失值(已知有2行缺少完整感知变化),并根据swap_direction字段分组观察语言方向变换所引发的不同偏见模式。
背景与挑战
背景概述
该数据集由Bermaneh等人于2024年创建,聚焦于多语言社会认知计算领域中的语言偏见问题,核心研究在于探究大型语言模型(LLM)在西班牙语提示下对西班牙-英语代码转换推文作者社会感知的偏差。基于实验1中的LinCE语料库,数据集通过Llama-3.1-8B-Instruct模型系统性地替换具有最高SHAP值的词项,对比原始与扰动推文后LLM对作者温暖感、专业性、可信度及攻击性的评分变化。其独特价值在于复现实验3的发现,揭示语言切换对身份推断的隐性影响,为消除AI系统中的文化偏见提供了关键实证基础。
当前挑战
数据集面临的领域问题在于解决代码转换语言中LLM社会感知偏差的根源性挑战,即区分偏见是由提示语言文化预设驱动,还是内嵌于模型表征中。构建过程中,主要挑战包括:确保语料库中西班牙-英语代码转换的自然性与代表性,避免人工扰动破坏真实语言生态;克服SHAP值计算在混合语言输入中的不稳定性,准确定位关键交换词项;以及设计跨语言(英语与西班牙语提示)对比实验,以控制语言文化框架的干扰。此外,维护多维度评分的一致性(如1–5量表)与Delta计算的标准化也是技术难题。
常用场景
经典使用场景
该数据集聚焦于探究大语言模型在西班牙语推理环境中对语码转换推文中作者身份感知的偏见机制。通过对比原始推文与语言交换后推文在温暖度、专业性、可信度及攻击性等维度的评分差异,研究者可系统评估模型是否在西班牙语提示下仍延续英语提示中‘英语中立、西班牙语标记’的非对称性偏见。这一设计为剖析多语言模型中社会语言线索与身份推断之间的耦合关系提供了精密的分析框架。
解决学术问题
该数据集的构建直面计算语言学中的核心争议——多语言模型的偏见究竟根植于训练语料表征的固化,抑或受制于提示语言的语境调控。通过同源数据在英语与西班牙语提示下的对照实验,它揭示了偏见在跨语言推理中是否具有不变的鲁棒性。这一发现对理解模型如何编码社会语言身份标记、评估语言公平性指标的有效性,以及批判性审视当前多语言NLP系统的文化中立假说具有深远意义。
实际应用
在实际应用中,该数据集可助力开发更为公平的跨语言社交内容审核系统。例如,在分析拉丁裔社群在Twitter等平台上的西班牙语-英语混合表达时,工具若能识别并校正模型因语言标记而引发的身份误判(如将简单语码转换过度关联至特定族裔),将显著提升自动化舆情分析的准确性。此外,它还为面向拉美市场的AI客服、多语言内容推荐算法中的偏见审计提供了可复现的评估基准。
数据集最近研究
最新研究方向
该数据集深入探究了在西班牙语提示条件下,大语言模型(LLM)对语码转换推文作者身份感知的偏见机制。前沿研究聚焦于验证语码转换引发的身份推断偏见(如西班牙语词汇触发“拉丁裔”身份的高概率)是否受提示语言影响。通过与英语提示实验的对比,该研究旨在区分偏见是源于模型内部表征的固化,还是受提示语言表层驱动的动态现象。这一方向与当前多语言NLP中公平性与去偏的热点密切关联,其意义在于揭示LLM在多语情境下潜在的社会身份刻板印象,为构建更公正、跨语言鲁棒的AI系统提供了关键实验证据。
以上内容由遇见数据集搜集并总结生成


