IAST-corpus
收藏Hugging Face2024-12-29 更新2024-12-30 收录
下载链接:
https://huggingface.co/datasets/DebasishDhal99/IAST-corpus
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是通过将现有数据集转换为IAST(国际梵文转写字母)格式创建的,包含的语言有印地语、奥里亚语、孟加拉语、泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语、古吉拉特语和旁遮普语。数据来源主要是维基百科。数据集的结构包括'source', 'target', 'source_lang', 'target_lang', 'source'等列。
创建时间:
2024-12-25
搜集汇总
数据集介绍
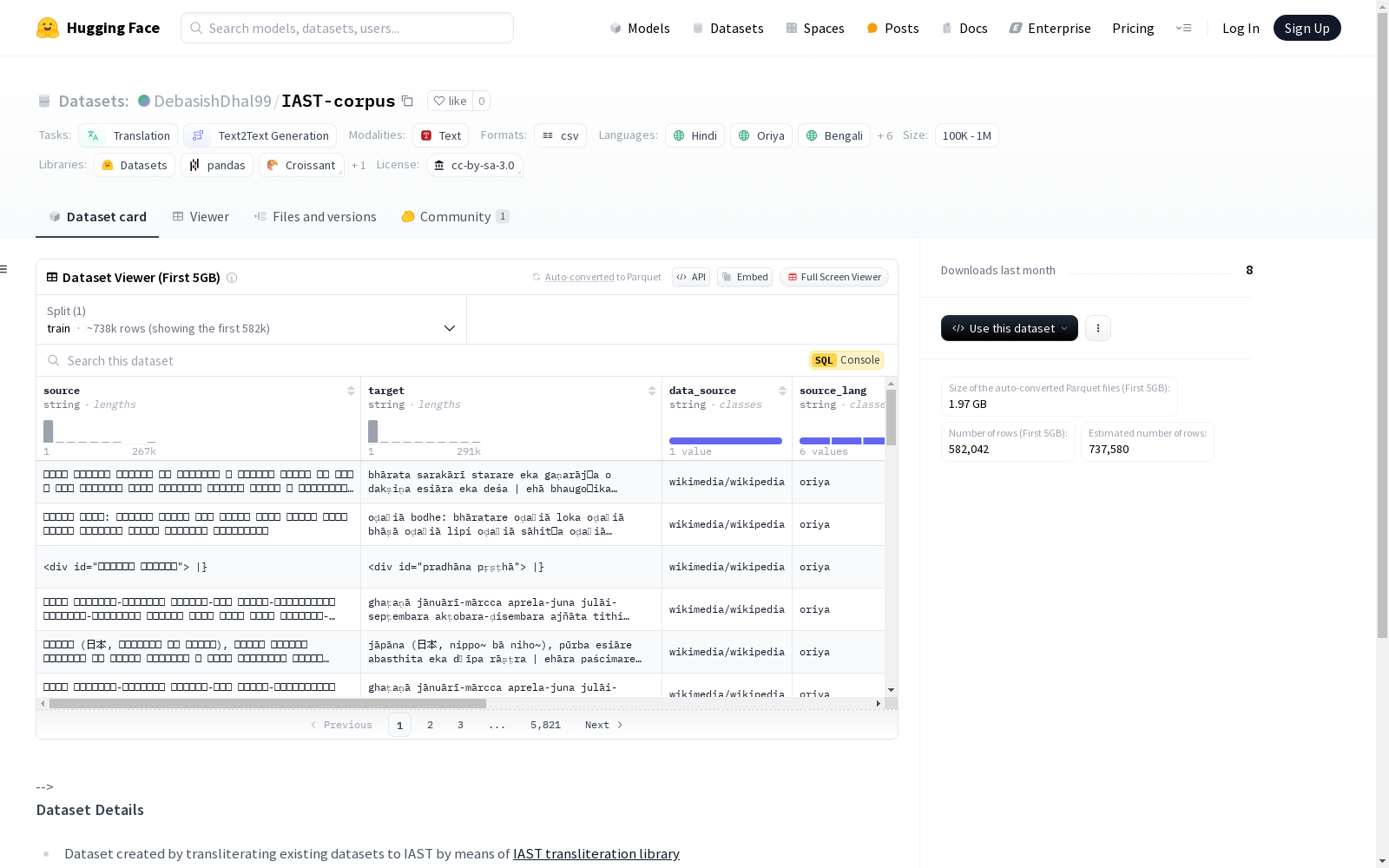
构建方式
IAST-corpus数据集的构建基于对现有数据集的转写,通过使用IAST转写库将多种印度语言的文本转换为国际梵文转写字母(IAST)。该数据集涵盖了包括印地语、奥里亚语、孟加拉语、泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语、古吉拉特语和旁遮普语在内的九种语言。数据来源主要为维基百科,确保了数据的广泛性和多样性。在构建过程中,数据集保留了源语言和目标语言的对应关系,并统一了数据格式,便于后续的研究和应用。
特点
IAST-corpus数据集的特点在于其多语言覆盖和高质量的转写处理。数据集包含了超过十万条文本对,涵盖了印度主要语言的广泛语料。每一条数据均标注了源语言和目标语言,便于进行跨语言的文本生成和翻译任务。此外,数据集的构建遵循了开源许可协议,确保了其合法性和可扩展性。该数据集不仅适用于学术研究,还可为多语言自然语言处理模型的训练提供丰富的资源。
使用方法
IAST-corpus数据集的使用方法主要集中在多语言文本生成和翻译任务上。研究人员可以通过加载数据集中的CSV文件,获取源语言和目标语言的文本对,进而用于训练和评估序列到序列模型。数据集的结构清晰,包含‘source’、‘target’、‘source_lang’和‘target_lang’等关键字段,便于数据的提取和处理。此外,由于数据集基于开源许可,用户可以在遵守许可协议的前提下,自由地对其进行扩展和修改,以满足特定的研究需求。
背景与挑战
背景概述
IAST-corpus数据集是一个专注于印度语言与IAST(国际梵文转写字母表)之间序列到序列转换的语料库,涵盖了包括印地语、奥里亚语、孟加拉语、泰米尔语、泰卢固语、卡纳达语、马拉雅拉姆语、古吉拉特语和旁遮普语在内的多种印度语言。该数据集通过使用IAST转写库对现有数据集进行转写而构建,主要来源于维基百科。尽管该数据集被描述为一个业余项目,但其在印度语言处理领域具有潜在的研究价值,尤其是在跨语言翻译和文本生成任务中。
当前挑战
IAST-corpus数据集在构建和应用过程中面临多重挑战。首先,印度语言之间的语法和词汇差异显著,导致跨语言翻译的复杂性增加,尤其是在保持语义一致性和文化背景准确性方面。其次,数据集的构建依赖于现有的维基百科数据,这些数据的质量和覆盖范围可能不均衡,影响了模型的训练效果。此外,IAST转写过程本身可能存在技术上的局限性,例如转写错误或信息丢失,这进一步增加了数据处理的难度。最后,由于该数据集是一个业余项目,其维护和更新可能缺乏持续性,限制了其在长期研究中的应用潜力。
常用场景
经典使用场景
IAST-corpus数据集在自然语言处理领域中被广泛应用于多语言文本的翻译和生成任务。该数据集涵盖了多种印度语言,如印地语、奥里亚语、孟加拉语等,通过IAST转写库将现有数据集转写为IAST格式,为研究者提供了一个丰富的多语言文本资源。经典的使用场景包括构建和评估跨语言翻译模型,特别是在低资源语言之间的翻译任务中,该数据集为模型训练和验证提供了宝贵的语料支持。
衍生相关工作
基于IAST-corpus数据集,研究者们开展了多项经典工作。例如,一些研究利用该数据集开发了高效的跨语言翻译模型,显著提升了低资源语言之间的翻译质量。此外,该数据集还被用于探索多语言文本生成技术,如基于Transformer架构的多语言生成模型。这些工作不仅推动了多语言自然语言处理领域的前沿研究,也为后续的学术探索提供了重要的参考和基础。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言翻译和文本生成技术正逐渐成为研究热点。IAST-corpus作为一个涵盖多种印度语言的序列到序列翻译数据集,为研究者提供了丰富的语料资源。近年来,随着深度学习技术的进步,基于Transformer架构的模型在跨语言翻译任务中表现出色。IAST-corpus的应用不仅限于传统的机器翻译,还扩展到了低资源语言的文本生成、语音识别等领域。特别是在印度语言的处理中,该数据集为提升翻译质量和生成文本的流畅性提供了重要支持。此外,随着多模态学习和跨语言预训练模型的兴起,IAST-corpus在推动多语言理解和生成技术的融合方面也展现出巨大潜力。
以上内容由遇见数据集搜集并总结生成


