AnimalCLAP Dataset
收藏arXiv2026-03-23 更新2026-03-25 收录
下载链接:
https://dahlian00.github.io/AnimalCLAP_Page/
下载链接
链接失效反馈官方服务:
资源简介:
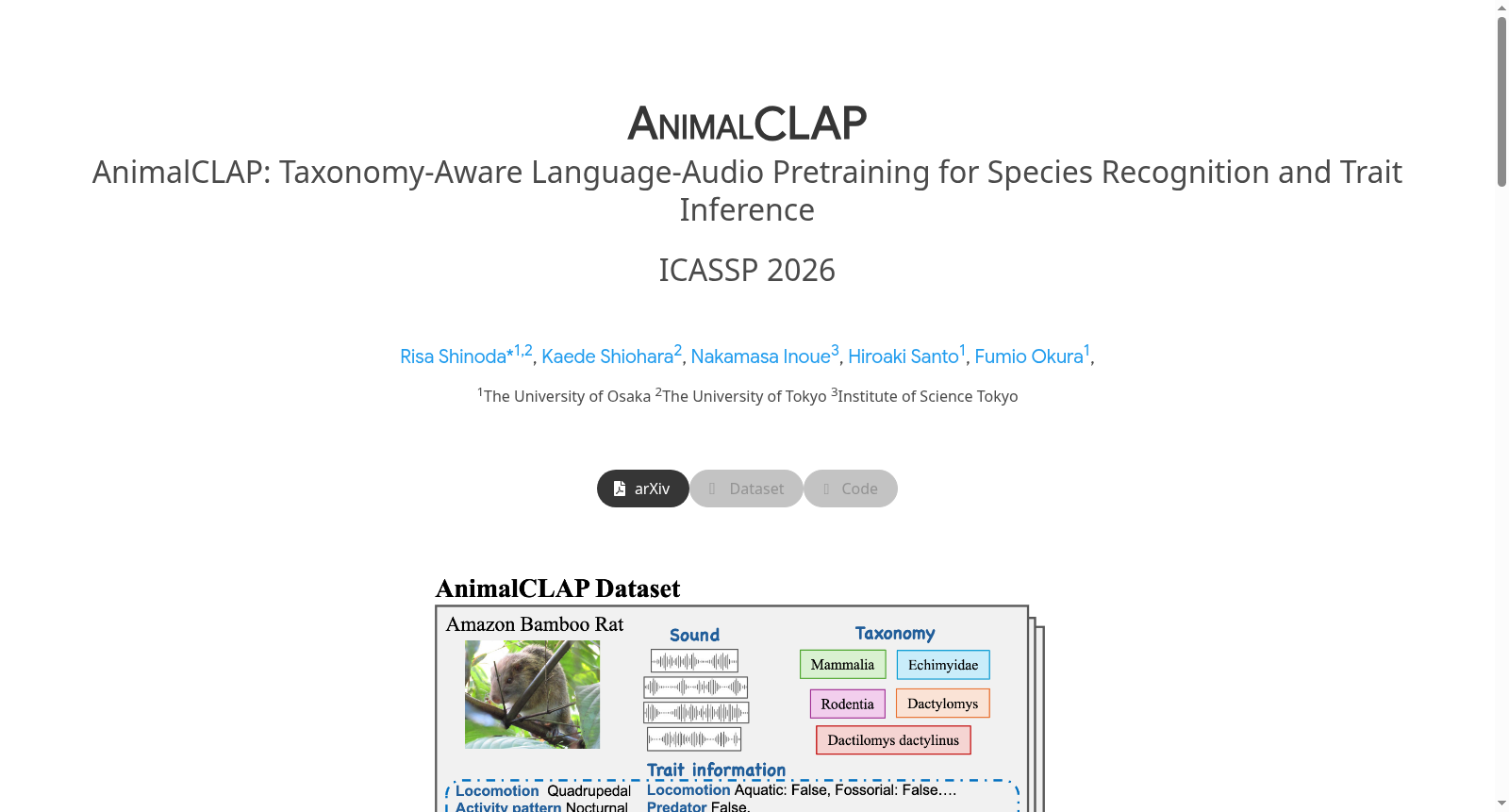
AnimalCLAP数据集由大阪大学和东京大学等机构联合构建,是一个涵盖6823个物种、4225小时动物声音记录的生物声学数据集,每条数据均标注了22种生态特征(如食性、活动模式等)。数据来源于iNaturalist和Xeno-canto平台,经过严格的物种筛选和GPT-5辅助标注验证,采用Creative Commons许可协议。该数据集通过整合生物分类学层次结构,旨在提升未见物种的识别能力,并支持从声学信号推断生态特征的跨学科研究,为生物多样性监测和计算生态学提供了重要资源。
AnimalCLAP is a bioacoustic dataset jointly constructed by institutions including Osaka University, The University of Tokyo, and other research organizations. It encompasses 6,823 species and 4,225 hours of animal sound recordings, with each data entry annotated with 22 ecological characteristics such as feeding habits and activity patterns. The data is sourced from the iNaturalist and Xeno-canto platforms, and has undergone rigorous species screening and annotation validation assisted by GPT-5, and is released under the Creative Commons license. By integrating the biological taxonomic hierarchy, this dataset aims to enhance the recognition performance of unseen species, support interdisciplinary research on inferring ecological characteristics from acoustic signals, and provide a critical resource for biodiversity monitoring and computational ecology.
提供机构:
大阪大学; 东京大学; 东京科学研究所
创建时间:
2026-03-23
搜集汇总
数据集介绍
构建方式
在生物声学领域,动物声音的自动识别已成为生态监测的关键技术。AnimalCLAP数据集的构建依托于两大开放平台:iNaturalist和Xeno-canto,前者汇集了公众提交的生物多样性观测记录,后者专注于鸟类鸣声的社区共享。研究团队从2014年至2025年上半年间收集了总计4225小时的音频数据,覆盖6823个物种。每个物种均标注了22项生态特征,如食性、活动模式和栖息地偏好等,这些特征通过GPT-5自动提取并辅以人工校验,确保了标注的准确性与完整性。数据集按物种划分为训练、验证和测试子集,其中测试集特意选取了300个稀有物种,以评估模型在未见物种上的泛化能力。
使用方法
该数据集主要应用于语言-音频对比学习框架,以提升模型对未见物种的识别能力。在使用时,音频数据通常被重采样至48kHz并随机裁剪为10秒片段,输入到音频编码器中。文本端则采用五种模板化描述,包括俗名、学名和分类学序列等,通过文本编码器生成嵌入表示。模型训练通过对比损失对齐音频与文本表示,并引入分类学结构作为监督信号,增强表示的层次化特性。完成预训练后,模型可进一步微调以直接从声音中预测生态特征。数据集的公开提供便于研究者进行零样本物种分类、跨物种泛化以及声学生态学关联分析等任务。
背景与挑战
背景概述
动物声学在生物多样性监测中扮演着关键角色,尤其在视觉受限的复杂生境如森林中,声学信号成为物种识别与生态评估的重要依据。AnimalCLAP数据集由大阪大学、东京大学及东京科学研究所的研究团队于2026年构建,旨在通过整合层级分类学信息与生态特征,推动基于音频的物种识别与性状推断研究。该数据集收录了涵盖6,823个物种、总时长4,225小时的动物发声记录,并标注了22类生态性状,为语言-音频预训练提供了大规模、结构化的资源。其核心研究问题聚焦于利用分类学结构增强模型对未见物种的泛化能力,以及探索从发声直接推断生态性状的可行性,对生物声学与计算生态学领域具有显著的推动作用。
当前挑战
AnimalCLAP数据集致力于解决动物声学领域中的两大挑战:一是提升对训练中未见物种的识别能力,这在生物多样性监测中至关重要,因为许多稀有物种的声学数据稀缺,传统模型难以泛化;二是构建能够从音频信号中直接推断物种生态性状(如活动模式、食性、栖息地等)的模型,这需要建立声学特征与复杂生态属性之间的深层关联。在数据集构建过程中,研究团队面临数据收集与标注的复杂性挑战,包括从iNaturalist和Xeno-canto等平台整合多源、异构的音频记录,确保数据质量与许可合规性;同时,为数千个物种手动验证并补充生态性状标注,涉及大量跨领域知识,过程耗时且需高精度处理。
常用场景
经典使用场景
在生物声学与计算生态学领域,AnimalCLAP数据集最经典的应用场景是作为零样本物种识别的基准测试平台。该数据集通过整合6823个物种、总计4225小时的动物声音记录,并辅以详尽的分类学层级信息和22种生态性状标注,为模型提供了学习声音与生物学知识关联的丰富素材。研究者通常利用其精心划分的训练集与测试集,评估音频-文本联合表示模型在遇到训练阶段未曾见过的物种时的泛化能力,从而推动面向真实复杂生态环境的鲁棒性生物多样性监测技术的发展。
解决学术问题
AnimalCLAP数据集主要解决了生物声学中两个关键的学术挑战:一是零样本或少量样本下的物种声音识别难题,通过引入分类学层级结构作为先验知识,增强了模型对未知物种的推理能力;二是从声音信号直接推断物种生态性状这一新兴交叉问题,数据集提供的多维度性状标签(如活动模式、食性、栖息地等)使得探索声音特征与生态功能之间的深层关联成为可能。这为理解动物声音的进化适应性与生态意义提供了可计算的研究范式,显著拓展了音频机器学习在生态学中的应用边界。
实际应用
该数据集的实际应用价值主要体现在大规模、自动化的生物多样性监测与保护中。例如,在热带雨林或深海等难以进行视觉观测的环境中,部署自动录音单元并利用基于AnimalCLAP训练的模型,可以实现对动物群落组成、物种分布乃至其行为生态性状的非侵入式、连续监测。这不仅极大降低了传统野外调查的人力与时间成本,也为评估气候变化、栖息地破碎化等环境压力对野生动物种群的影响提供了高时空分辨率的数据支持,助力于制定科学的保护管理策略。
数据集最近研究
最新研究方向
在生物声学与计算生态学领域,AnimalCLAP数据集推动了基于语言-音频预训练框架的前沿探索,其核心在于整合层级分类学信息以增强模型对未见物种的识别能力。当前研究聚焦于利用对比学习机制,将动物发声与包含科学名、俗名及分类序列的文本描述对齐,从而构建更具泛化性的跨模态表示。这一方向不仅提升了物种分类的准确性,更拓展至从声学信号直接推断生态性状(如活动模式、栖息地偏好等)的新兴任务,为生物多样性监测提供了数据驱动的创新工具。相关进展呼应了人工智能在生态保护中的应用热点,通过公开数据集与模型促进了跨学科合作,对理解声学特征与生物多样性间的复杂关联具有深远意义。
相关研究论文
- 1AnimalCLAP: Taxonomy-Aware Language-Audio Pretraining for Species Recognition and Trait Inference大阪大学; 东京大学; 东京科学研究所 · 2026年
以上内容由遇见数据集搜集并总结生成


