cryptom/ceval-exam
收藏Hugging Face2023-06-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/cryptom/ceval-exam
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
task_categories:
- text-classification
- multiple-choice
- question-answering
language:
- zh
pretty_name: C-Eval
size_categories:
- 10K<n<100K
---
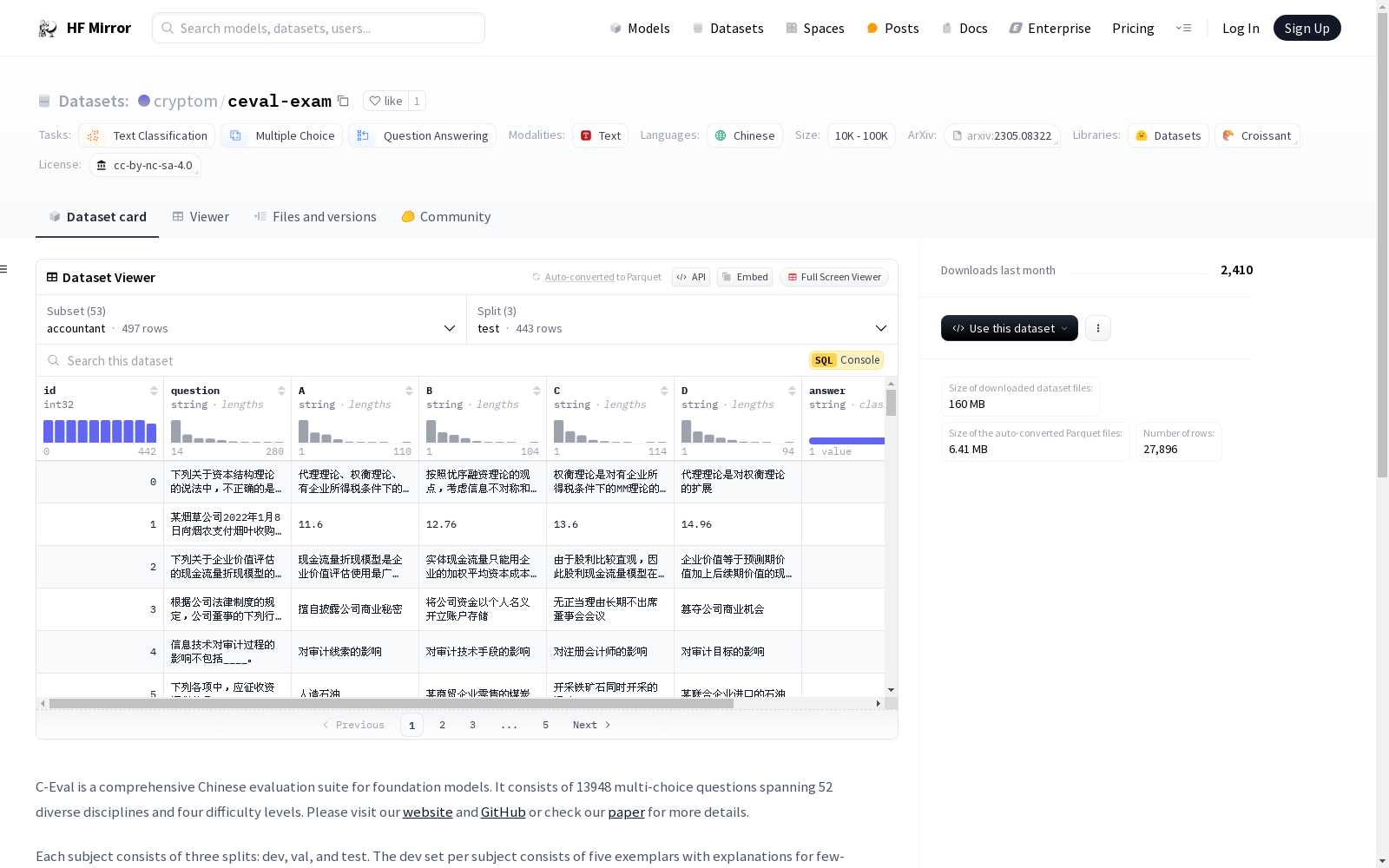
C-Eval is a comprehensive Chinese evaluation suite for foundation models. It consists of 13948 multi-choice questions spanning 52 diverse disciplines and four difficulty levels. Please visit our [website](https://cevalbenchmark.com/) and [GitHub](https://github.com/SJTU-LIT/ceval/tree/main) or check our [paper](https://arxiv.org/abs/2305.08322) for more details.
Each subject consists of three splits: dev, val, and test. The dev set per subject consists of five exemplars with explanations for few-shot evaluation. The val set is intended to be used for hyperparameter tuning. And the test set is for model evaluation. Labels on the test split are not released, users are required to submit their results to automatically obtain test accuracy. [How to submit?](https://github.com/SJTU-LIT/ceval/tree/main#how-to-submit)
### Load the data
```python
from datasets import load_dataset
dataset=load_dataset(r"ceval/ceval-exam",name="computer_network")
print(dataset['val'][0])
# {'id': 0, 'question': '使用位填充方法,以01111110为位首flag,数据为011011111111111111110010,求问传送时要添加几个0____', 'A': '1', 'B': '2', 'C': '3', 'D': '4', 'answer': 'C', 'explanation': ''}
```
More details on loading and using the data are at our [github page](https://github.com/SJTU-LIT/ceval#data).
Please cite our paper if you use our dataset.
```
@article{huang2023ceval,
title={C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models},
author={Huang, Yuzhen and Bai, Yuzhuo and Zhu, Zhihao and Zhang, Junlei and Zhang, Jinghan and Su, Tangjun and Liu, Junteng and Lv, Chuancheng and Zhang, Yikai and Lei, Jiayi and Fu, Yao and Sun, Maosong and He, Junxian},
journal={arXiv preprint arXiv:2305.08322},
year={2023}
}
```
许可协议:CC BY-NC-SA 4.0
任务分类:
- 文本分类
- 多项选择
- 问答
语言:中文
展示名称:C-Eval
样本规模:1万 < 样本量 < 10万
C-Eval是一款面向基础模型的综合性中文评测套件,包含13948道多项选择题,覆盖52个多元学科与4个难度层级。如需获取更多详情,请访问我们的[官方网站](https://cevalbenchmark.com/)、[GitHub仓库](https://github.com/SJTU-LIT/ceval/tree/main)或查阅相关[学术论文](https://arxiv.org/abs/2305.08322)。
每个学科均分为开发集(dev)、验证集(val)与测试集(test)三个子集。单学科的开发集包含5个附带解释的示例样本,用于少样本(Few-shot)评测;验证集用于超参数调优;测试集用于模型性能评估。测试子集的标签未对外公开,用户需提交模型预测结果以自动获取测试准确率,[提交方式详见此处](https://github.com/SJTU-LIT/ceval/tree/main#how-to-submit)。
### 数据加载
python
from datasets import load_dataset
dataset=load_dataset(r"ceval/ceval-exam",name="computer_network")
print(dataset['val'][0])
# {'id': 0, 'question': '使用位填充方法,以01111110为位首flag,数据为011011111111111111110010,求问传送时要添加几个0____', 'A': '1', 'B': '2', 'C': '3', 'D': '4', 'answer': 'C', 'explanation': ''}
更多关于数据加载与使用的细节可查阅我们的[GitHub页面](https://github.com/SJTU-LIT/ceval#data)。
若您使用本数据集,请引用我们的学术论文:
@article{huang2023ceval,
title={C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models},
author={Huang, Yuzhen and Bai, Yuzhuo and Zhu, Zhihao and Zhang, Junlei and Zhang, Jinghan and Su, Tangjun and Liu, Junteng and Lv, Chuancheng and Zhang, Yikai and Lei, Jiayi and Fu, Yao and Sun, Maosong and He, Junxian},
journal={arXiv preprint arXiv:2305.08322},
year={2023}
}
提供机构:
cryptom
原始信息汇总
数据集概述
名称: C-Eval
许可证: cc-by-nc-sa-4.0
任务类别:
- 文本分类
- 多项选择
- 问答
语言: 中文
规模: 10K<n<100K
数据集内容
C-Eval 是一个综合性的中文基础模型评估套件,包含13948个多项选择题,涵盖52个不同学科和四个难度级别。
数据集结构
每个学科包含三个部分:
- dev 集:包含五个示例及其解释,用于少样本评估。
- val 集:用于超参数调整。
- test 集:用于模型评估,测试集的标签不公开,用户需提交结果以自动获取测试准确率。
数据加载示例
python from datasets import load_dataset dataset=load_dataset(r"ceval/ceval-exam",name="computer_network")
print(dataset[val][0])
{id: 0, question: 使用位填充方法,以01111110为位首flag,数据为011011111111111111110010,求问传送时要添加几个0____, A: 1, B: 2, C: 3, D: 4, answer: C, explanation: }
引用信息
@article{huang2023ceval, title={C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models}, author={Huang, Yuzhen and Bai, Yuzhuo and Zhu, Zhihao and Zhang, Junlei and Zhang, Jinghan and Su, Tangjun and Liu, Junteng and Lv, Chuancheng and Zhang, Yikai and Lei, Jiayi and Fu, Yao and Sun, Maosong and He, Junxian}, journal={arXiv preprint arXiv:2305.08322}, year={2023} }
搜集汇总
数据集介绍
构建方式
C-Eval数据集的构建旨在为中文基础模型提供一个全面且多样化的评估平台。该数据集包含了13948道多选题,涵盖了52个不同的学科领域,并分为四个难度级别。每个学科领域被细分为开发集(dev)、验证集(val)和测试集(test)。开发集包含五个带有解释的样本,用于少样本评估;验证集用于超参数调优;测试集则用于模型评估。测试集的标签未公开,用户需提交结果以自动获取测试准确率。
特点
C-Eval数据集的显著特点在于其广泛性和多样性。它不仅覆盖了多个学科领域,还通过四个难度级别确保了评估的全面性。此外,数据集的结构设计合理,包括开发集、验证集和测试集,使得模型可以在不同阶段进行有效的评估和优化。测试集的标签保密机制也增加了数据集的挑战性和实用性。
使用方法
使用C-Eval数据集时,用户可以通过HuggingFace的datasets库轻松加载数据。例如,使用`load_dataset`函数可以加载特定学科的数据集,如计算机网络。数据集的使用包括开发集的少样本评估、验证集的超参数调优以及测试集的模型评估。用户需遵循提交指南,将测试结果提交以获取准确率评估。更多详细信息和使用示例可在数据集的GitHub页面找到。
背景与挑战
背景概述
C-Eval数据集是由上海交通大学LIT实验室主导开发的综合性中文评估套件,旨在为基石模型提供全面的中文能力评估。该数据集创建于2023年,包含了13948道多选题,涵盖52个不同学科领域,并设置了四个难度级别。C-Eval的推出填补了中文基石模型评估领域的空白,为研究人员提供了一个标准化的测试平台,有助于推动中文自然语言处理技术的发展。
当前挑战
C-Eval数据集在构建过程中面临多重挑战。首先,涵盖52个学科的多选题设计需要跨学科的专业知识,确保题目在不同领域的代表性和准确性。其次,数据集的难度分级要求对题目进行精细的难度评估,以确保评估结果的可靠性。此外,数据集的规模和多样性也带来了管理和维护的挑战,特别是在处理大规模数据时,如何保证数据的质量和一致性是一个重要问题。
常用场景
经典使用场景
C-Eval数据集在多学科领域的基础模型评估中展现了其经典应用场景。该数据集包含了13948道多选题,涵盖了52个不同的学科和四个难度级别,为模型在广泛学科中的表现提供了全面的评估。通过使用C-Eval,研究者可以有效地测试和比较不同基础模型在中文环境下的性能,尤其是在跨学科和多难度层次的复杂任务中。
衍生相关工作
C-Eval数据集的发布激发了一系列相关研究工作。例如,研究者基于C-Eval开发了新的模型评估方法,探索了不同模型在多学科和多难度级别下的表现差异。此外,还有研究聚焦于如何利用C-Eval数据集进行模型优化和参数调整,以提高模型在中文环境下的整体性能。这些工作不仅丰富了中文自然语言处理的研究内容,也为未来的模型评估提供了新的思路和方法。
数据集最近研究
最新研究方向
在自然语言处理领域,C-Eval数据集的推出为中文基础模型的评估提供了全面且细致的工具。该数据集涵盖了52个学科领域,并设置了四个难度级别,旨在通过多选题的形式评估模型在不同学科和难度下的表现。近年来,研究者们利用C-Eval数据集进行了一系列前沿研究,特别是在多任务学习、少样本学习和跨学科知识迁移等方面。这些研究不仅推动了中文基础模型的性能提升,还为模型在实际应用中的泛化能力提供了新的评估标准。此外,C-Eval的开放性和多样性也吸引了学术界和工业界的广泛关注,成为评估中文语言模型性能的重要基准之一。
以上内容由遇见数据集搜集并总结生成


