ipfs_netherlands_laws_knowledge_graph
收藏Hugging Face2026-04-26 更新2026-04-27 收录
下载链接:
https://huggingface.co/datasets/justicedao/ipfs_netherlands_laws_knowledge_graph
下载链接
链接失效反馈官方服务:
资源简介:
IPFS荷兰法律知识图谱是一个基于IPFS内容地址的知识图谱数据集,包含荷兰法律相关的JSON-LD图和节点/边表。数据集目前包含6792个节点和6692条边,来源于配对的CID数据集。需要注意的是,当前数据集可能有所限制,不能视为完整的荷兰法律语料库,除非配对的基数据集清单或运行元数据证明其具有完整的发现覆盖范围。基数据集还包括文章提取诊断和针对旧式/法语标题样式的解析器覆盖改进。
The IPFS Netherlands Laws Knowledge Graph is a knowledge graph dataset based on IPFS content addressing, containing JSON-LD graphs and node/edge tables related to Dutch laws. The dataset currently includes 6792 nodes and 6692 edges, sourced from paired CID datasets. It should be noted that the current dataset may have limitations and cannot be considered a complete corpus of Dutch laws unless the paired base dataset inventory or runtime metadata proves it has complete discovery coverage. The base dataset also includes article extraction diagnostics and parser coverage improvements for old-style/French title styles.
创建时间:
2026-04-12
原始信息汇总
数据集概述
- 数据集名称:IPFS Netherlands Laws Knowledge Graph(IPFS 荷兰法律知识图谱)
- 语言:荷兰语(
nl) - 标签:IPFS、CID、法律
- 许可协议:其他(
other) - 目标地址:
justicedao/ipfs_netherlands_laws_knowledge_graph
数据集内容
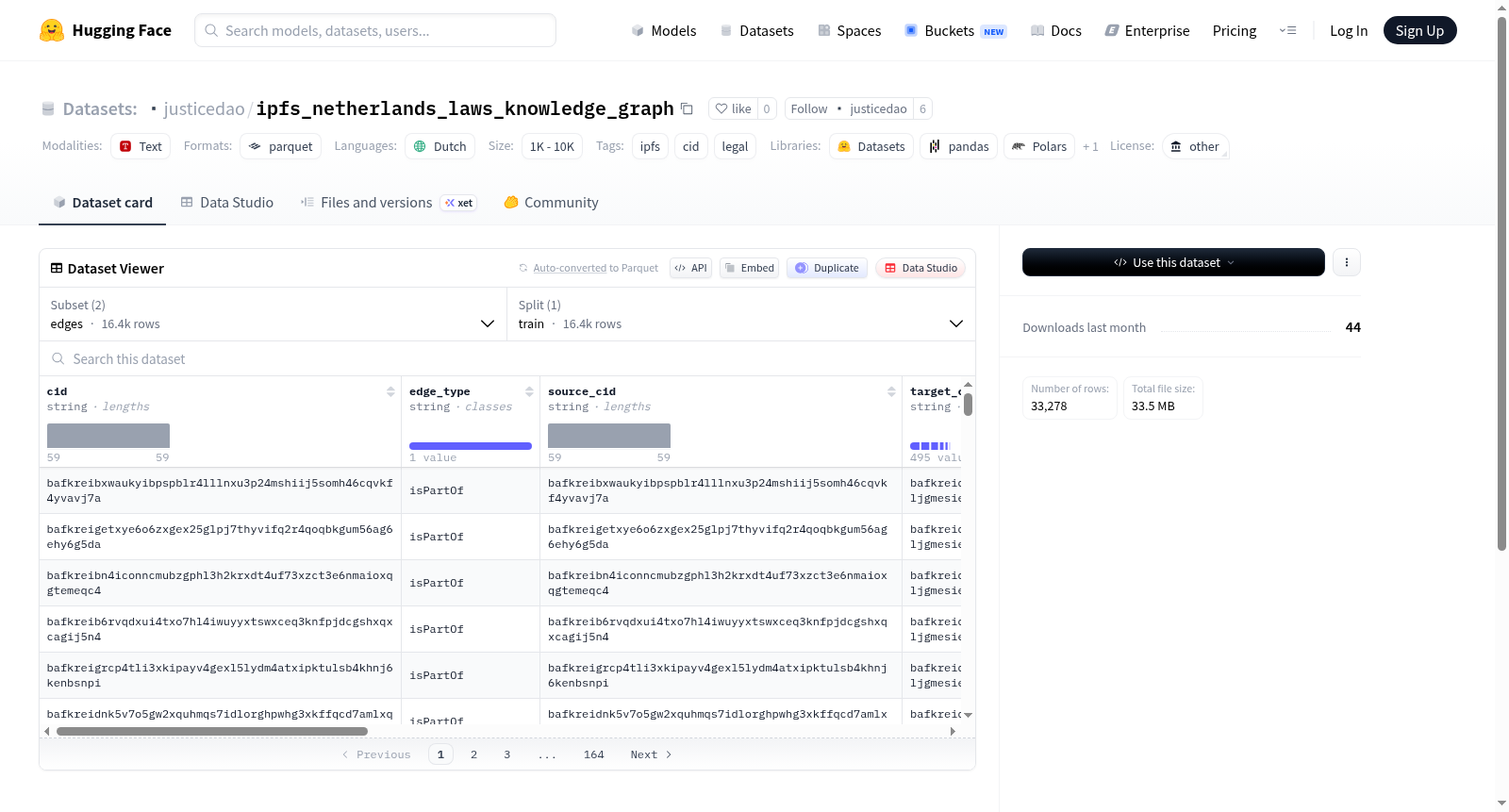
该数据集包含一个 JSON-LD 图以及节点/边表格,其身份标识为 IPFS 内容地址。当前版本包含 6792 个节点和 6692 条边,源自配对的 CID 数据集。
数据集配置
数据集包含两个配置:
nodes配置:训练数据文件位于parquet/nodes/*.parquetedges配置:训练数据文件位于parquet/edges/*.parquet
注意事项
- 当前源数据集可能存在上限,不应将其描述为完整的荷兰语语料库,除非配对的基数据集清单/运行元数据能够证明完全覆盖。
- 配对的基数据集包含文章提取诊断信息以及针对旧式/法式标题风格的解析器覆盖改进。
搜集汇总
数据集介绍
构建方式
该数据集以IPFS内容寻址技术为基石,构建了一个关于荷兰法律的异构图谱。其节点与边表均以内容标识符(CID)作为唯一身份,确保了数据的去中心化与不可篡改性。数据集源自平行的CID数据集,当前包含6792个节点与6692条边,通过解析荷兰法律条文中的章节结构、引用关系等要素,将法律文本转化为结构化的图谱数据。构建过程涵盖了从原始法律文书中提取文章、诊断解析质量,并针对老旧/法文标题风格进行了解析器覆盖范围的优化。
特点
本数据集的核心特征在于其独特的身份标识机制——所有节点与边均依托IPFS内容地址,实现了数据的永久性定位与防篡改保障。图谱结构清晰呈现了荷兰法律体系内部的关联网络,适合用于知识推理与法律分析。同时,数据集提供了节点与边两种配置模式,便于用户根据需求灵活取用。此外,数据来源虽可能因源数据集上限而并非涵盖所有荷兰法律文献,但其配套的基数据集包含了文章提取诊断与解析器改进信息,为数据质量提供了可追溯的元数据支撑。
使用方法
用户可通过Hugging Face仓库直接加载数据,仓库提供`nodes`与`edges`两个子配置,分别对应图谱的节点和边数据,均以Parquet格式存储。使用时,用户可依据任务需求选择加载完整的节点表或边表,例如使用`load_dataset`函数指定配置名。若需结合图谱进行推理,亦可结合IPFS的CID进行外部数据验证或跨链关联。对于需要完整荷兰法律语料的研究,建议先核对基数据集的清单与运行元数据,以确认数据覆盖率是否满足需求。
背景与挑战
背景概述
在法律文本结构化与语义互联的研究领域中,知识图谱作为将分散法规转化为可计算知识体的关键基础设施,正日益受到学术界与实务界的重视。IPFS Netherlands Laws Knowledge Graph 数据集由 JusticeDAO 机构于近期创建,旨在利用星际文件系统(IPFS)的内容寻址特性,将荷兰法律体系中的法规条文及其相互关系以节点-边表与JSON-LD图的形式进行编码。该数据集包含6792个节点与6692条边,其核心研究问题在于探索如何通过去中心化存储技术保障法律知识图谱的持久性与不可篡改性,同时为法律人工智能应用的语义推理与跨文档链接提供结构化基础。作为首个将荷兰法律语料与IPFS内容标识符(CID)深度融合的知识图谱,该数据集为法律知识工程与分布式数据管理领域提供了创新范本。
当前挑战
该数据集所解决的领域挑战主要在于法律文本的异构性与动态性:荷兰法律体系包含多种历史版本与条文格式(如老旧法文标题样式),传统集中式知识图谱难以支持版本追溯与引文完整性验证,而IPFS的CID机制虽能确保内容一致性,但图谱构建中需处理不完整的语料覆盖(当前数据集来源可能受限,无法代表完整的荷兰法律全集)以及多源文档的解析诊断与格式适配。在构建过程中,挑战集中于节点/边关系的精准抽取——如何从非结构化法律条款中识别跨文档引用、应对法语标题等特殊排版导致的解析歧义,并在仅有有限元数据(如未提供完整运行清单)的条件下,确保图谱的发现覆盖率达到可验证的学术标准。此外,由于数据存储依赖去中心化网络,其访问延迟与更新机制的可扩展性也是实际应用中的潜在难点。
常用场景
经典使用场景
该数据集以荷兰法律体系为根基,构建了一幅包含6792个节点与6692条边的知识图谱,其中每个实体与关系均通过IPFS内容地址(CID)进行身份标识。其经典使用场景在于为法律文本的结构化表示提供去中心化、不可篡改的存储范式,研究者可借此探索法律条款之间的关联网络,例如法规间的引用关系、法条与判例的语义连接,以及法律术语的层级分类。通过图谱的节点与边表格,用户能够高效执行法律知识的检索与推理,支撑起诸如法律文本一致性验证或立法影响评估等任务。
解决学术问题
该数据集着力解决法律知识图谱构建中普遍存在的中心化存储脆弱性与数据溯源难题。传统法律数据库常面临版本管理混乱与跨系统互操作障碍,而IPFS Netherlands Laws Knowledge Graph通过内容寻址技术确保了法律数据的完整性与持久性,使每一条法条或关系变更均有迹可循。此外,数据集揭示了荷兰语法律文档中旧式法语标题风格的解析挑战,推动了自然语言处理在法律文本分割与实体识别领域的算法优化,为多语言法律知识系统的鲁棒性研究奠定了实证基础。
衍生相关工作
该数据集催生了一系列围绕法律知识图谱与去中心化存储融合的衍生研究。相关工作包括基于CID的法律文本版本追踪系统,旨在通过IPFS哈希链记录荷兰法案的修订历程;另有工作聚焦于法语-荷兰语法律术语的跨语言对齐,借助图谱中的多语言节点标签训练法律领域的翻译模型。此外,部分学者以此为起点,探索将法律推理引擎与图谱查询接口结合,开发出支持自然语言问询的判例推荐工具,而数据集中标注的解析缺陷也为改进非当代荷兰语法律文档的分词器提供了基准测试用例。
以上内容由遇见数据集搜集并总结生成


