Dataset-LinkSocial
收藏github2023-09-09 更新2024-05-31 收录
下载链接:
https://github.com/vishalshar/Dataset-LinkSocial
下载链接
链接失效反馈官方服务:
资源简介:
该数据集用于链接多个社交媒体平台上的用户配置文件,包含用户在不同平台上的用户名、简介、全名、外部链接和双词组等信息。
This dataset is designed for linking user profiles across multiple social media platforms, encompassing usernames, bios, full names, external links, and bigram information from different platforms.
创建时间:
2019-02-28
原始信息汇总
数据集概述
数据集名称
Dataset-LinkSocial
数据集统计信息
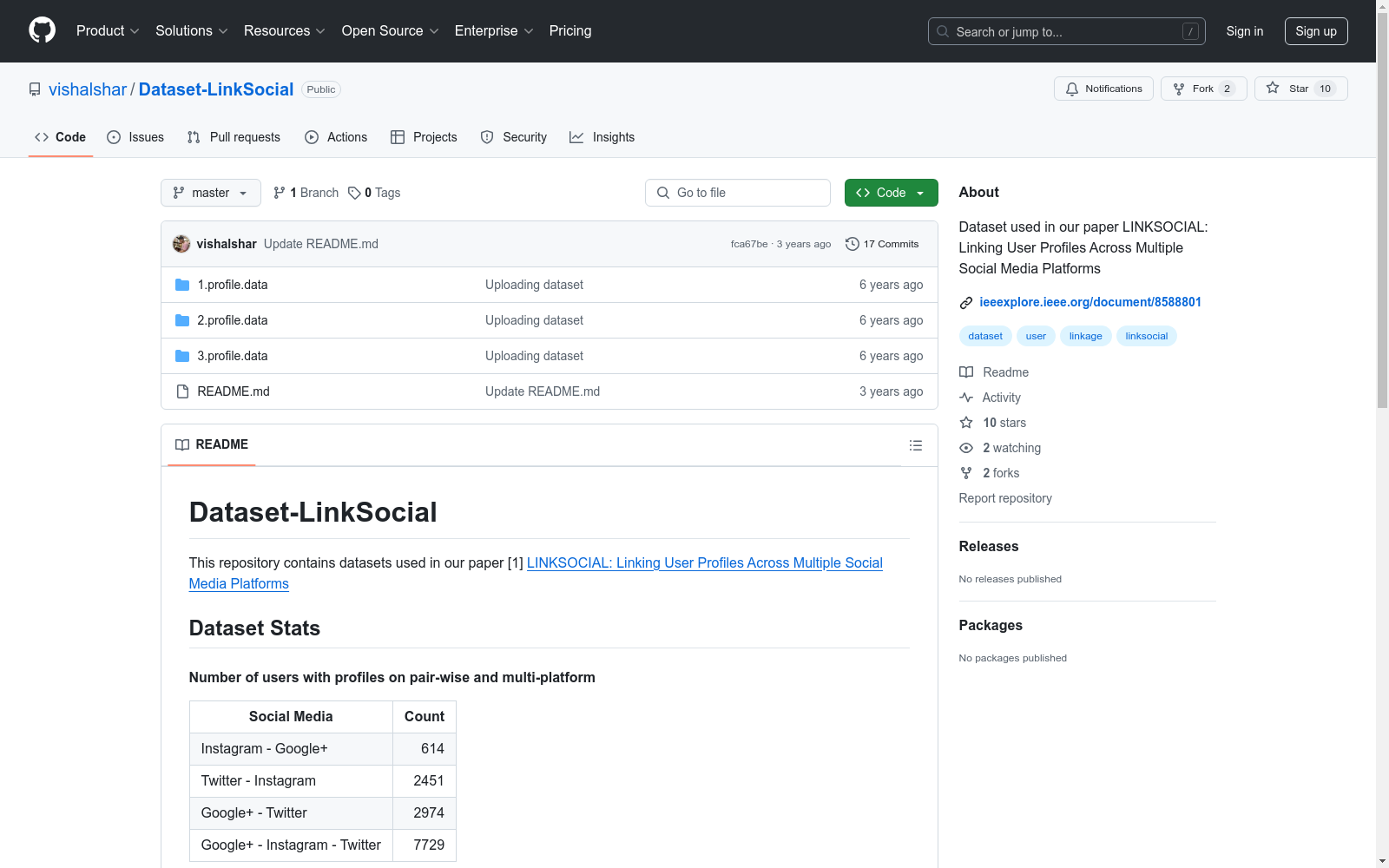
用户跨平台统计
| 社交平台组合 | 用户数 |
|---|---|
| Instagram - Google+ | 614 |
| Twitter - Instagram | 2451 |
| Google+ - Twitter | 2974 |
| Google+ - Instagram - Twitter | 7729 |
各社交平台用户数
| 社交平台 | 用户数 |
|---|---|
| 10,958 | |
| 13,961 | |
| Google+ | 11,892 |
数据集内容
| 字段 | Google+ | ||
|---|---|---|---|
| 用户名 | √ | √ | √ |
| 个人简介 | √ | √ | √ |
| 全名 | √ | √ | √ |
| 外部链接 | √ | √ | √ |
| 双词组(用户名 & 全名) | √ | √ | √ |
| 头像URL | × | √ | √ |
引用信息
@article{Sharma2018LINKSOCIALLU, title={LINKSOCIAL: Linking User Profiles Across Multiple Social Media Platforms}, author={Vishal Sharma and Curtis E. Dyreson}, journal={2018 IEEE International Conference on Big Knowledge (ICBK)}, year={2018}, pages={260-267} }
搜集汇总
数据集介绍
构建方式
Dataset-LinkSocial数据集的构建基于跨社交媒体平台的用户档案链接研究。研究者通过收集Instagram、Google+和Twitter三大社交平台上的用户档案信息,包括用户名、个人简介、全名、外部链接以及用户与全名的双字母组合等数据,构建了一个跨平台用户档案链接数据集。数据集的构建过程涉及对多个平台用户档案的匹配与整合,旨在为跨平台用户身份识别提供数据支持。
特点
Dataset-LinkSocial数据集的特点在于其覆盖了多个主流社交媒体平台的用户档案信息,并提供了跨平台用户档案的匹配数据。数据集包含超过10,000个Instagram用户档案、13,000个Twitter用户档案以及11,000个Google+用户档案,涵盖了用户在不同平台上的基本信息与行为特征。此外,数据集还提供了用户档案的双字母组合特征,为跨平台用户身份识别提供了丰富的特征信息。
使用方法
Dataset-LinkSocial数据集的使用方法主要围绕跨平台用户档案链接的研究展开。研究者可以通过分析数据集中的用户档案信息,探索跨平台用户身份识别的算法与模型。数据集中的双字母组合特征可用于构建用户档案的相似性度量,而跨平台匹配数据则可用于验证算法的有效性。此外,数据集还可用于社交媒体用户行为分析、用户画像构建等研究领域。
背景与挑战
背景概述
Dataset-LinkSocial数据集由Vishal Sharma和Curtis Dyreson于2018年创建,旨在解决跨多个社交媒体平台的用户档案链接问题。该数据集的研究背景源于社交媒体平台的多样性和用户在不同平台上创建多个档案的普遍现象。通过整合Instagram、Google+和Twitter等平台上的用户档案信息,研究人员能够探索用户在不同平台上的行为模式和身份一致性。该数据集在2018年IEEE国际大知识会议(ICBK)上发布,为跨平台用户档案链接研究提供了重要的数据支持,推动了社交媒体分析和用户行为研究的深入发展。
当前挑战
Dataset-LinkSocial数据集面临的挑战主要集中在两个方面。首先,跨平台用户档案链接的复杂性使得数据集的构建过程充满挑战。不同平台的用户档案结构各异,数据格式和内容的不一致性增加了数据整合的难度。其次,用户隐私保护和数据获取的合法性也是构建过程中需要克服的重要问题。此外,数据集在解决跨平台用户档案链接问题时,还需应对用户在不同平台上使用不同用户名、头像和简介等信息的多样性,这对算法的鲁棒性和准确性提出了更高的要求。
常用场景
经典使用场景
Dataset-LinkSocial数据集在跨社交媒体平台用户画像链接研究中具有重要应用。该数据集通过整合Instagram、Google+和Twitter三大社交平台的用户信息,为研究者提供了一个多维度、跨平台的用户画像数据集。其经典使用场景包括用户身份识别、跨平台行为分析以及社交网络中的用户画像匹配研究。通过分析用户在多个平台上的用户名、简介、全名等信息,研究者能够深入探讨用户在不同社交平台上的行为模式及其关联性。
实际应用
在实际应用中,Dataset-LinkSocial数据集为社交媒体平台用户画像的跨平台整合提供了重要支持。例如,在广告精准投放、用户兴趣推荐以及社交网络安全监控等领域,该数据集能够帮助企业和研究机构实现跨平台用户画像的统一管理。通过分析用户在多个平台上的行为数据,企业可以更精准地定位目标用户群体,优化广告投放策略。同时,该数据集还为社交网络安全监控提供了数据基础,帮助识别潜在的虚假账号和异常行为。
衍生相关工作
Dataset-LinkSocial数据集自发布以来,衍生了一系列经典研究工作。例如,基于该数据集的跨平台用户画像匹配算法研究,推动了多模态信息融合技术的发展。此外,该数据集还被广泛应用于社交网络分析、用户行为预测以及社交网络安全等领域。相关研究不仅提升了跨平台用户画像匹配的准确性,还为社交网络中的用户行为建模提供了新的思路。这些工作进一步拓展了数据集的应用范围,推动了社交网络研究领域的发展。
以上内容由遇见数据集搜集并总结生成


