TrainingDataPro/selfie_and_video
收藏Hugging Face2024-04-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/TrainingDataPro/selfie_and_video
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-nd-4.0
task_categories:
- image-to-video
- image-to-image
- video-classification
- image-classification
- image-feature-extraction
language:
- en
tags:
- biology
- finance
- code
- legal
---
# Selfies and video dataset
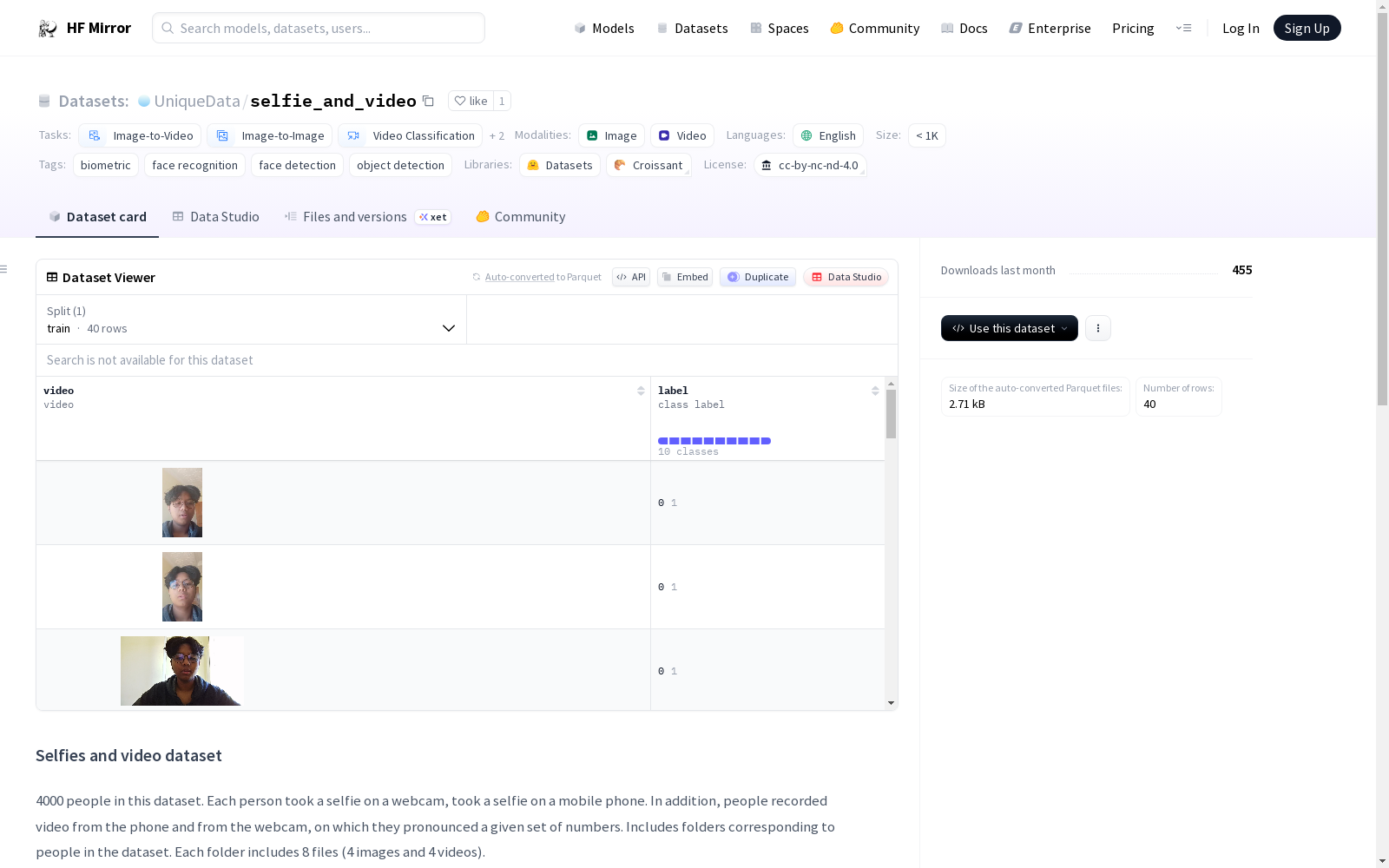
4000 people in this dataset. Each person took a selfie on a webcam, took a selfie on a mobile phone. In addition, people recorded video from the phone and from the webcam, on which they pronounced a given set of numbers.
Includes folders corresponding to people in the dataset. Each folder includes 8 files (4 images and 4 videos).
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/datasets**](https://trainingdata.pro/datasets/selfie-and-video?utm_source=huggingface&utm_medium=cpc&utm_campaign=selfie_and_video) to discuss your requirements, learn about the price and buy the dataset.
# File with the extension .csv
includes the following information for each media file:
- **SetId**: a unique identifier of a set of 8 media files,
- **WorkerId**: the identifier of the person who provided the media file,
- **Country**: the country of origin of the person,
- **Age**: the age of the person,
- **Gender**: the gender of the person,
- **Type**: the type of media file
- **Link**: the URL to access the media file
# Folder "img" with media files
- containg all the photos and videos
- which correspond to the data in the .csv file
**How it works**: *go to the first folder and you will make sure that it contains media files taken by a person whose parameters are specified in the first 8 lines of the .csv file.*
## [**TrainingData**](https://trainingdata.pro/datasets/selfie-and-video?utm_source=huggingface&utm_medium=cpc&utm_campaign=selfie_and_video) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
*keywords: biometric system, biometric dataset, face recognition database, face recognition dataset, face detection dataset, facial analysis, object detection dataset, deep learning datasets, computer vision datset, human images dataset, human videos dataset, human faces dataset, machine learning, video-to-image, re-identification, verification models, video dataset, video classification, video recognition, photos and videos*
许可协议:CC BY-NC-ND 4.0
任务类别:
- 图像转视频(image-to-video)
- 图像转图像(image-to-image)
- 视频分类(video-classification)
- 图像分类(image-classification)
- 图像特征提取(image-feature-extraction)
语言:
- 英语(en)
标签:
- 生物学(biology)
- 金融(finance)
- 代码(code)
- 法律(legal)
# 自拍与视频数据集
本数据集共收录4000名受试者的相关数据。每名受试者均通过网络摄像头拍摄自拍照片,同时使用移动设备完成自拍采集;此外,受试者还分别使用手机与网络摄像头录制了朗读指定数字序列的视频内容。
数据集内设有与每名受试者对应的专属文件夹,每个文件夹均包含8份媒体文件(4张图像与4段视频)。
# 数据集获取方式
### 本数据集仅为数据样例
请访问[**https://trainingdata.pro/datasets**](https://trainingdata.pro/datasets/selfie-and-video?utm_source=huggingface&utm_medium=cpc&utm_campaign=selfie_and_video)提交申请,即可洽谈定制需求、了解定价方案并完成数据集采购。
# 扩展名为.csv的索引文件
该文件为每条媒体文件提供如下元数据:
- **SetId**:8份媒体文件组合的唯一标识符
- **WorkerId**:提交该媒体文件的受试者唯一标识
- **Country**:受试者所属国家
- **Age**:受试者年龄
- **Gender**:受试者性别
- **Type**:媒体文件类型
- **Link**:媒体文件访问链接
# 媒体文件存储文件夹「img」
- 存储所有图像与视频文件
- 与.csv索引文件中的记录一一对应
**使用说明**:*进入首个受试者文件夹,即可验证其包含的媒体文件与.csv索引文件前8行记录的受试者参数完全匹配。*
## [**TrainingData**](https://trainingdata.pro/datasets/selfie-and-video?utm_source=huggingface&utm_medium=cpc&utm_campaign=selfie_and_video) 可提供按需定制的高质量数据标注服务
TrainingData在Kaggle平台的公开数据集仓库:**https://www.kaggle.com/trainingdatapro/datasets**
TrainingData官方GitHub仓库:**https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
*关键词:生物识别系统(biometric system)、生物特征数据集(biometric dataset)、人脸识别数据库(face recognition database)、人脸识别数据集(face recognition dataset)、人脸检测数据集(face detection dataset)、面部分析(facial analysis)、目标检测数据集(object detection dataset)、深度学习数据集(deep learning datasets)、计算机视觉数据集(computer vision dataset)、人体图像数据集(human images dataset)、人体视频数据集(human videos dataset)、人脸数据集(human faces dataset)、机器学习(machine learning)、视频转图像(video-to-image)、重识别(re-identification)、验证模型(verification models)、视频数据集(video dataset)、视频分类(video classification)、视频识别(video recognition)、图像与视频(photos and videos)*
提供机构:
TrainingDataPro
原始信息汇总
数据集概述
数据集名称
- Selfies and video dataset
数据集描述
- 包含4000人的自拍和视频数据。
- 每位参与者通过网络摄像头和手机拍摄自拍照片,并通过手机和网络摄像头录制视频,视频中参与者朗读一组数字。
- 每位参与者的数据包含在一个文件夹中,每个文件夹内有8个文件(4张图片和4个视频)。
数据集结构
- 文件夹结构:每位参与者的数据对应一个文件夹,包含4张图片和4个视频。
- .csv文件:包含每个媒体文件的详细信息,包括SetId(唯一标识符)、WorkerId(参与者标识符)、Country(国家)、Age(年龄)、Gender(性别)、Type(媒体文件类型)和Link(访问媒体文件的URL)。
数据集内容
- 图片和视频:所有图片和视频文件存储在名为"img"的文件夹中,与.csv文件中的数据相对应。
数据集用途
- 适用于多种任务类别,包括:
- 图像到视频转换
- 图像到图像转换
- 视频分类
- 图像分类
- 图像特征提取
数据集标签
- 相关领域包括生物学、金融、代码和法律。
数据集许可证
- 许可证:CC-BY-NC-ND-4.0
数据集语言
- 语言:英语
搜集汇总
数据集介绍
构建方式
在生物特征识别领域,高质量数据集的构建对算法性能至关重要。该数据集通过系统化采集流程,招募了来自不同国家的4000名参与者,每位参与者使用网络摄像头和移动设备分别拍摄自拍照片,并录制视频朗读指定数字序列。数据以个人为单位组织,每个文件夹包含4张图像和4段视频,共计8个媒体文件,确保了样本的多样性和一致性。
特点
该数据集在生物特征分析中展现出显著的多模态特性,融合了静态图像与动态视频数据,覆盖了网络摄像头与移动设备两种采集环境。数据集附带详细的元数据CSV文件,包含参与者唯一标识、国籍、年龄、性别及媒体类型等信息,为跨设备人脸识别、活体检测及语音视觉融合研究提供了结构化支持。其规模介于10万至100万样本之间,适用于训练复杂的深度学习模型。
使用方法
研究人员可通过数据集提供的CSV文件与媒体文件夹进行对应访问,利用SetId与WorkerId字段关联个体数据。该数据集支持图像分类、视频分类、特征提取及跨模态任务,适用于开发人脸验证、活体检测或身份重识别模型。使用前需注意其CC-BY-NC-ND 4.0许可限制,商业用途需通过官方渠道获取授权,确保符合伦理与法律规范。
背景与挑战
背景概述
在生物识别技术蓬勃发展的时代背景下,TrainingDataPro/selfie_and_video数据集应运而生,旨在为多模态身份验证研究提供关键数据支撑。该数据集由Unidata团队构建,汇集了来自4000位参与者的自拍图像与视频资料,每位参与者均通过手机与网络摄像头两种设备采集静态与动态生物特征。其核心研究问题聚焦于跨设备、跨模态的人脸识别与活体检测,通过结构化标注的年龄、性别、国籍等元数据,为提升生物识别系统的鲁棒性与公平性奠定了实证基础,对计算机视觉与安全认证领域产生了深远影响。
当前挑战
该数据集致力于应对生物识别领域中跨模态身份验证的固有挑战,例如在复杂光照、设备差异及动态表情下维持高精度人脸匹配。构建过程中的挑战尤为显著,包括确保大规模参与者数据的隐私合规性、统一多设备采集的媒体格式与质量标准,以及在海量图像与视频数据间建立精确的元数据关联。此外,数据标注需克服个体生物特征多样性带来的标注一致性难题,这些因素共同构成了数据集构建与应用的核心瓶颈。
常用场景
经典使用场景
在生物特征识别领域,Selfie_and_video数据集以其丰富的多模态数据为模型训练提供了理想环境。该数据集包含来自4000名个体的自拍图像与视频记录,涵盖了不同设备采集的静态与动态面部信息。经典使用场景聚焦于跨模态人脸识别与验证任务,研究者可借助图像与视频的配对关系,构建鲁棒的深度神经网络,以应对真实世界中光照、姿态及设备差异带来的挑战。
解决学术问题
该数据集有效解决了生物特征识别研究中若干关键学术问题。其多模态特性为跨设备人脸验证提供了基准数据,助力探索图像与视频特征的对齐与融合机制。同时,数据集标注的年龄、性别及国籍等元信息,为公平性分析与偏见消减研究提供了实证基础。这些贡献显著推动了生物识别系统在泛化能力与伦理考量方面的理论进展。
衍生相关工作
围绕该数据集已衍生出多项经典研究工作。部分研究聚焦于跨模态表征学习,提出了新型视频-图像特征提取架构;另有工作利用其元数据开展公平性评估,揭示了不同人口属性群体的识别性能差异。这些成果不仅丰富了生物识别领域的学术文献,也为后续多模态数据集构建标准提供了重要参考范式。
以上内容由遇见数据集搜集并总结生成


