synthetic-complaints-v2
收藏Hugging Face2024-10-31 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/leonvanbokhorst/synthetic-complaints-v2
下载链接
链接失效反馈官方服务:
资源简介:
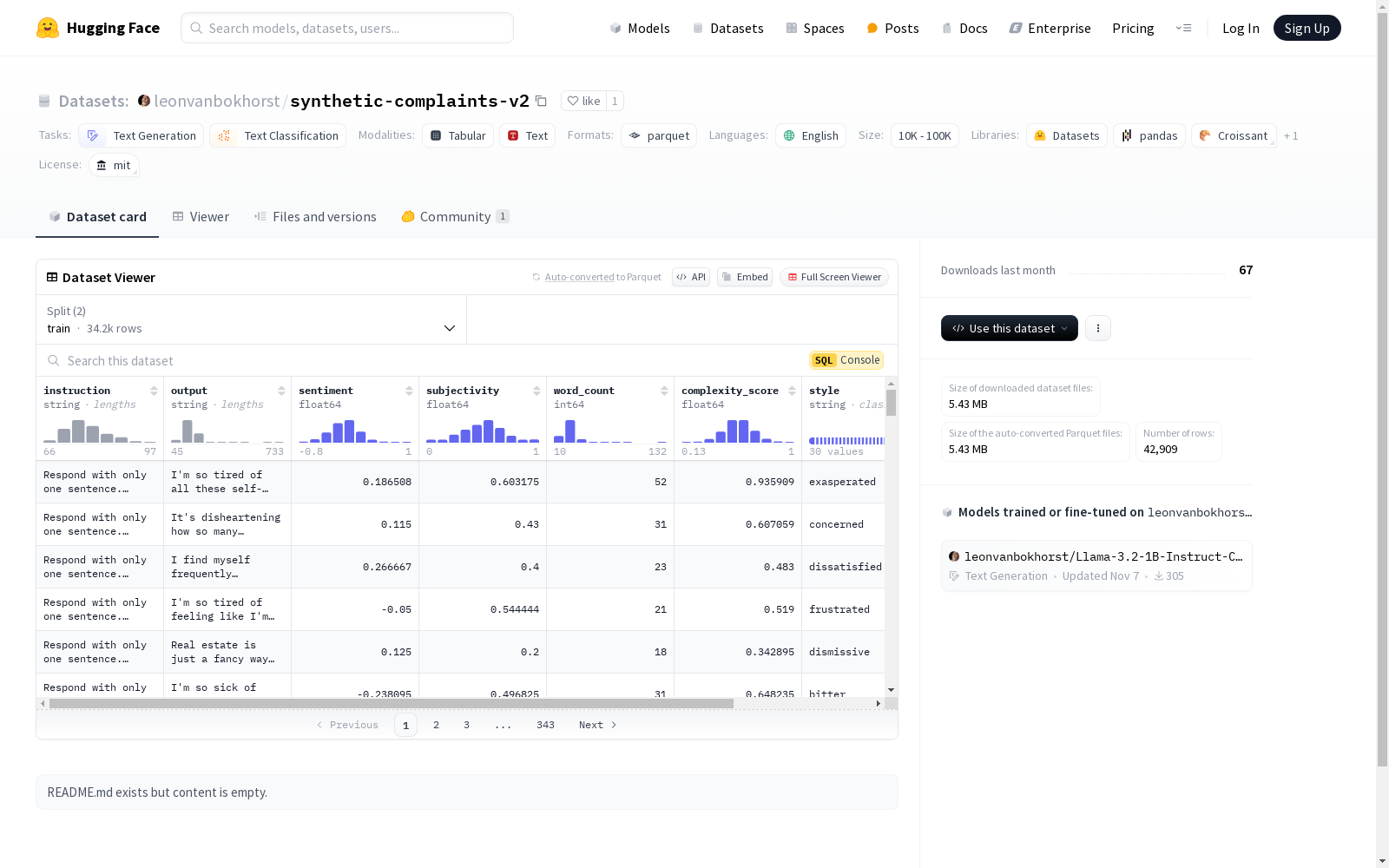
该数据集包含多个特征,如指令、输出、情感等,每个特征都有其特定的数据类型。数据集分为训练集和测试集,分别包含1812和460个样本。数据集的下载大小为295020字节,总大小为702486.746007891字节。数据集的配置名为'default',包含训练和测试数据文件。数据集的许可证为MIT,主要用于文本生成任务,语言为英语,数据集的友好名称为'Synthetic Complaints'。
This dataset encompasses multiple features including instruction, output, sentiment, and others, each with a specific data type. The dataset is split into training and test subsets, which contain 1812 and 460 samples respectively. The download size of the dataset is 295020 bytes, while the total size is 702486.746007891 bytes. The dataset's configuration is named 'default', which includes the training and test data files. The dataset is licensed under MIT, primarily intended for text generation tasks, uses English as its language, and has a friendly name of 'Synthetic Complaints'.
创建时间:
2024-10-31
原始信息汇总
数据集概述
数据集名称
Synthetic Complaints
数据集信息
特征
- instruction: 字符串类型
- output: 字符串类型
- sentiment: 浮点数类型
- subjectivity: 浮点数类型
- word_count: 整数类型
- complexity_score: 浮点数类型
- style: 字符串类型
- topic: 字符串类型
数据分割
- train: 包含12392个样本,大小为3837107.1221398646字节
- test: 包含3140个样本,大小为971572.9667598633字节
数据集大小
- 下载大小: 1975645字节
- 数据集总大小: 4808680.088899728字节
配置
- config_name: default
- data_files:
- train: data/train-*
- test: data/test-*
- data_files:
许可证
MIT
任务类别
- 文本生成
语言
- 英语
搜集汇总
数据集介绍
构建方式
Synthetic Complaints V2数据集的构建基于文本生成与分类任务的需求,通过模拟用户投诉场景生成大量合成数据。该数据集包含训练集和测试集,分别包含34229和8680条样本。每条样本均标注了指令、输出、情感、主观性、词数、复杂度评分、风格和主题等多个特征,确保了数据的多样性和丰富性。数据集的构建过程注重真实性与多样性,旨在为自然语言处理任务提供高质量的基准数据。
使用方法
Synthetic Complaints V2数据集适用于文本生成与分类任务的研究与开发。用户可通过加载训练集进行模型训练,利用测试集进行性能评估。数据集的多维度标注信息可用于多任务学习,提升模型的泛化能力。在使用过程中,用户可根据任务需求选择特定特征进行建模,例如基于情感或主题的分类任务。数据集的MIT许可证允许广泛的学术与商业用途,为自然语言处理领域的研究者提供了灵活的应用空间。
背景与挑战
背景概述
Synthetic Complaints V2数据集是一个专注于文本生成与分类任务的人工合成数据集,旨在模拟真实世界中的用户投诉场景。该数据集由多个特征组成,包括指令、输出、情感、主观性、词数、复杂性评分、风格和主题等,涵盖了广泛的文本属性。其创建时间与主要研究人员或机构虽未明确提及,但可以推测其设计初衷是为了提升自然语言处理模型在处理用户反馈时的表现。通过提供多样化的投诉文本,该数据集为研究人员和开发者提供了一个丰富的实验平台,推动了文本生成与分类领域的技术进步。
当前挑战
Synthetic Complaints V2数据集在解决文本生成与分类问题时面临多重挑战。首先,如何确保生成的投诉文本在语义和情感上接近真实用户反馈,是一个关键难题。其次,数据集在构建过程中需要平衡多样性与一致性,既要涵盖广泛的投诉主题和风格,又要保证文本的质量和可解释性。此外,情感与主观性评分的标注需要高度的精确性,以避免模型训练中的偏差。这些挑战不仅考验了数据集的构建技术,也对后续模型的性能提出了更高的要求。
常用场景
经典使用场景
在自然语言处理领域,synthetic-complaints-v2数据集常用于文本生成和文本分类任务的模型训练与评估。该数据集通过提供多样化的投诉文本,帮助研究人员深入理解不同情感、主题和风格下的语言表达模式。特别是在生成具有特定情感倾向的文本时,该数据集为模型提供了丰富的训练样本,使其能够更好地模拟真实场景中的语言行为。
解决学术问题
synthetic-complaints-v2数据集解决了文本生成和分类研究中数据多样性和复杂性的问题。通过包含情感、主观性、词汇量、复杂度和风格等多维度特征,该数据集为研究人员提供了全面的分析工具,使其能够更精确地评估模型在不同语言环境下的表现。此外,该数据集还为研究情感分析、主题建模和风格迁移等任务提供了高质量的数据支持,推动了相关领域的技术进步。
实际应用
在实际应用中,synthetic-complaints-v2数据集被广泛用于客户服务自动化系统的开发。通过训练基于该数据集的模型,企业能够自动生成或分类客户投诉,从而提高服务效率和客户满意度。此外,该数据集还可用于社交媒体监控,帮助企业和政府机构实时分析公众情绪和舆论趋势,为决策提供数据支持。
数据集最近研究
最新研究方向
在自然语言处理领域,synthetic-complaints-v2数据集因其丰富的文本特征和多样化的情感标注,成为研究文本生成与分类任务的重要资源。近年来,随着深度学习技术的快速发展,该数据集被广泛应用于情感分析、文本风格迁移以及主题分类等前沿研究方向。特别是在情感分析领域,研究者们通过结合情感得分和主观性指标,探索了更为精细的情感分类模型,提升了模型对复杂情感表达的识别能力。此外,该数据集在文本生成任务中的应用也备受关注,研究者们利用其多样化的指令和输出对,训练出更具上下文感知能力的生成模型。这些研究不仅推动了自然语言处理技术的进步,也为实际应用场景如客户服务自动化、情感智能助手等提供了有力支持。
以上内容由遇见数据集搜集并总结生成


