synthetic_OCR_dataset
收藏Hugging Face2026-05-16 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/GaborMadarasz/synthetic_OCR_dataset
下载链接
链接失效反馈官方服务:
资源简介:
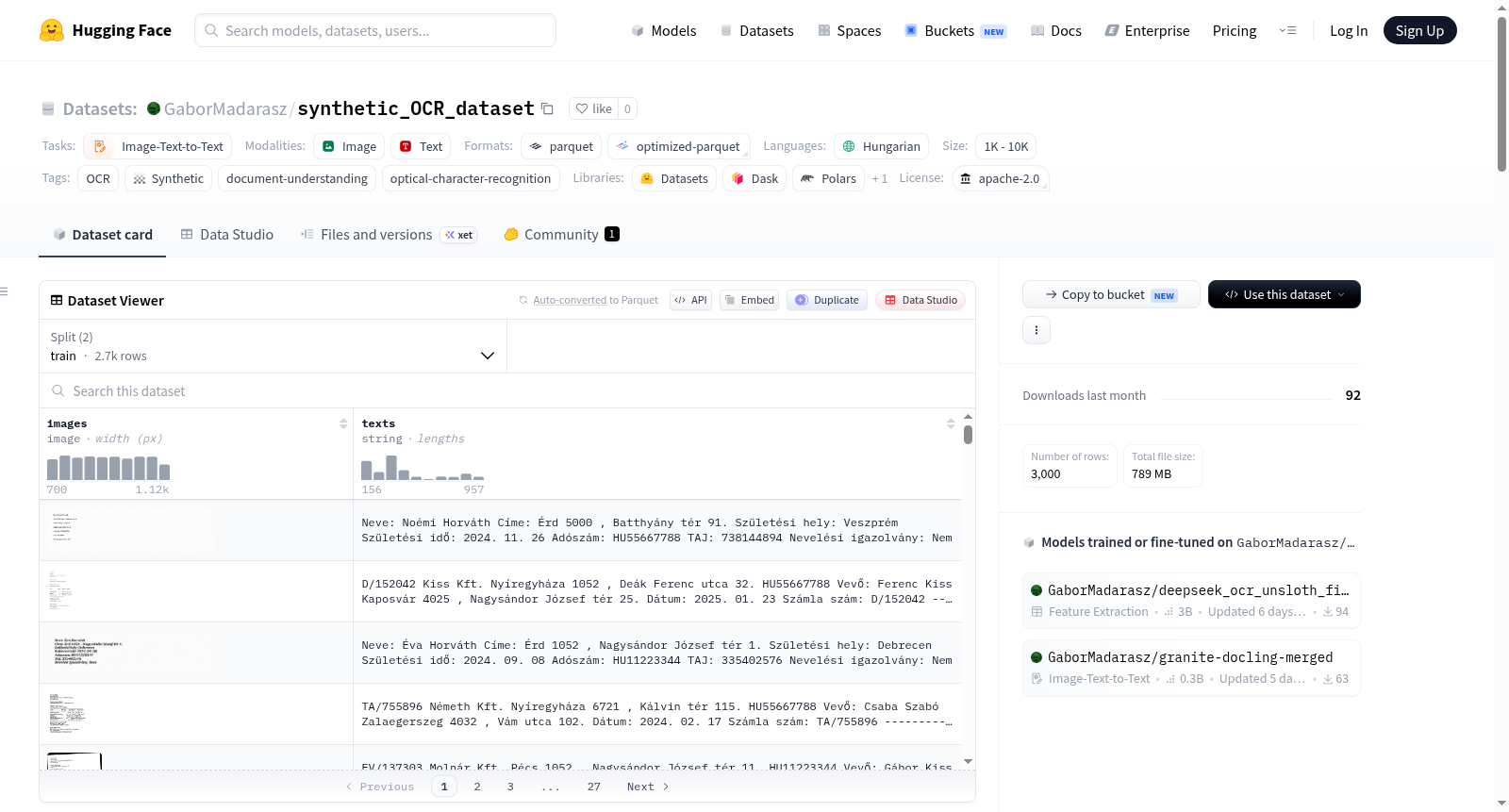
该数据集是一个合成生成的匈牙利文档OCR数据集,包含3000个匈牙利文档图像及其对应的真实文本转录。它专为训练和评估光学字符识别(OCR)、文档布局分析以及匈牙利行政和商业文档上的多模态语言模型而设计。数据集语言为匈牙利语,完全支持变音符号(如á、é、í、ó、ö、ő、ú、ü、ű)。文档类型包括发票(带有项目表格、增值税计算和银行详细信息)、正式信件(带有发件人/收件人标题和结构化正文)、表格(带有姓名、地址、税号、TAJ等标签字段)以及混合内容的自由格式文档(如标题、片段、列表、金额)。视觉上具有可变性:使用随机系统字体(TTF/OTF)和字体大小(10-22磅),DPI范围为150-300,可选高斯噪声(30%概率,严重程度0.02-0.08)和轻微旋转(±3°,20%概率),并支持两种渲染后端(Pillow默认,ReportLab+ImageMagick用于结构化发票)。文本内容包含真实的匈牙利名称、地址、城市、街道名称,有效格式的税号(HUxxxxxxxx)、IBAN/BIC代码、发票号码,以及福林货币格式和领域特定词汇(产品、服务、法律短语)。数据字段包括图像路径列表和文本字符串(以换行符分隔)。数据分割为单个分割,其中约60%为基于模板的文档(约1800个样本),约40%为自由格式文档(约1200个样本)。创建过程涉及从策划列表采样内容、使用预定义模板或随机组合组装布局,并通过PIL/Pillow渲染图像,可选后处理。使用注意事项:数据为合成生成,缺乏真实世界扫描伪影(如倾斜、阴影、纸张纹理),需考虑领域适应;专注于匈牙利语,保留变音符号和正字法;所有个人数据均为合成生成,不对应真实个体。限制包括字体覆盖依赖系统可用字体、布局多样性有限(模板样本结构固定,自由格式样本可能未覆盖所有真实布局),且所有文本为机器渲染,不适用于手写文本识别。
This dataset is a synthetically generated Hungarian document OCR dataset, containing 3000 Hungarian document images and their corresponding ground truth text transcriptions. It is specifically designed for training and evaluating optical character recognition (OCR), document layout analysis, and multimodal language models on Hungarian administrative and commercial documents. The dataset language is Hungarian, fully supporting diacritics (e.g., á, é, í, ó, ö, ő, ú, ü, ű). Document types include invoices (with item tables, VAT calculations, and bank details), formal letters (with sender/recipient headers and structured body), forms (with labeled fields such as name, address, tax number, TAJ), and free-form documents with mixed content (e.g., headings, paragraphs, lists, amounts). Visually, it exhibits variability: random system fonts (TTF/OTF) and font sizes (10-22 points) are used, DPI ranges from 150-300, optional Gaussian noise (30% probability, severity 0.02-0.08) and slight rotation (±3°, 20% probability) are applied, and two rendering backends are supported (Pillow by default, ReportLab+ImageMagick for structured invoices). Text content includes realistic Hungarian names, addresses, cities, street names, validly formatted tax numbers (HUxxxxxxxx), IBAN/BIC codes, invoice numbers, as well as Hungarian forint currency formats and domain-specific vocabulary (products, services, legal phrases). Data fields consist of a list of image paths and text strings (separated by newlines). The data is split into a single split, with approximately 60% being template-based documents (about 1800 samples) and approximately 40% free-form documents (about 1200 samples). The creation process involves sampling content from curated lists, assembling layouts using predefined templates or random combinations, and rendering images via PIL/Pillow, with optional post-processing. Usage notes: The data is synthetically generated and lacks real-world scanning artifacts (e.g., skew, shadows, paper texture), requiring consideration for domain adaptation; it focuses on Hungarian, preserving diacritics and orthography; all personal data is synthetically generated and does not correspond to real individuals. Limitations include font coverage dependent on system-available fonts, limited layout diversity (template samples have fixed structures, and free-form samples may not cover all real layouts), and all text is machine-rendered, making it unsuitable for handwritten text recognition.
创建时间:
2026-05-15
搜集汇总
数据集介绍
构建方式
该数据集通过系统性流水线生成:首先从精心挑选的语料库中采样匈牙利语文本片段、姓名、地址及领域特定词汇;继而依据模板(如发票、信函、表格)或随机组合策略进行版面组装;最终利用PIL/Pillow将文本渲染至白色背景PNG图像,过程中随机选取系统字体、字号(10-22磅)及DPI(150-300),并以30%概率施加高斯噪声(强度0.02-0.08)、20%概率引入随机旋转(±3°)。对于发票类文档,可选通过ReportLab生成高保真PDF再经ImageMagick转制为PNG,以提升结构保真度。
特点
数据集共包含3,000张合成匈牙利语文档图像,覆盖发票、正式信函、表格及自由格式文档四类,突出展现了语言特异性与视觉多样性:完整支持匈牙利语变音符号(á, é, í, ó, ö, ő, ú, ü, ű),内容包含真实感姓名、地址、有效格式税号(HUxxxxxxxx)及IBAN/BIC代码;图像在字体、噪声、旋转角度上呈现随机变化,模拟自然成像差异。数据集聚焦于低资源OCR场景下的文档理解,为多模态预训练提供结构化标注。
使用方法
本数据集适用于光学字符识别(OCR)、文档版面分析与多模态语言模型的训练与评估。使用时,通过读取JSON格式记录中的`images`字段获取图像相对路径(如`images/img_000001.png`),同时利用`texts`字段提取与图像完全对齐的换行分隔真值文本。单拆分结构包含3,000个样本,无需额外划分。建议针对生产级OCR应用进行领域自适应以弥补合成数据与真实扫描图像之间的分布差异;对于其他语言任务,需在匈牙利语微调的基础上进一步适配。
背景与挑战
背景概述
光学字符识别(OCR)技术是文档数字化与智能理解的核心,尤其对于匈牙利语等小语种,因含有丰富变音符号(如á、é、í、ó、ö、ő、ú、ü、ű),通用模型往往识别精度不足。为此,Gabor Madarasz于2026年发布了Synthetic Hungarian Document OCR Dataset,该数据集包含3,000张合成匈牙利文档图像,涵盖发票、正式信函、表格及自由格式文档等典型行政与商业场景。数据通过模板生成与随机组合实现布局多样性,并引入随机字体、噪声及旋转以模拟真实环境。该数据集为低资源匈牙利语OCR、文档布局分析与多模态预训练提供了关键基准,有力推动了小语种文档智能领域的发展。
当前挑战
该数据集面临的挑战首要在于领域问题的复杂性:匈牙利语变音符号众多,传统OCR模型在区分ë̋与ö等细微差异时易出错,且文档结构高度多样化(如表格、多栏布局),对端到端识别模型提出高要求。其次,构建过程中挑战显著:为保证文本真实性,需手工整理大量匈牙利姓名、地址、税务代码等语料,并设计多套模板模拟真实文档逻辑;渲染时需兼顾Pillow与ReportLab双后端兼容性,并调和字体差异与随机扰动(噪声、旋转)对图像质量的影响。此外,合成数据缺乏真实扫描伪影(如折痕、污渍),导致域适应成为将模型迁移至生产环境的核心瓶颈。
常用场景
经典使用场景
该数据集经典使用场景在于匈牙利语文档的光学字符识别(OCR)模型训练与评估,特别是针对带有变音符号的复杂文本。通过提供3,000张合成文档图像及其精确转录,研究者可训练模型识别发票、正式信函、表格等结构化文档,并应对字体、字号、旋转和噪声的随机变化,从而提升OCR系统在商业与行政场景中的鲁棒性。
实际应用
实际应用中,该数据集可用于自动化匈牙利企业文档处理,如发票数据提取、表单信息录入和信件分类。金融、法律和公共服务机构可借此构建数字工作流,减少人工录入错误;同时,合成数据的可扩展性使其能模拟真实扫描场景,辅助开发抗噪声的OCR系统,提升低资源语言文档数字化效率。
衍生相关工作
基于该数据集,研究者已衍生出多项工作,包括:结合变换器架构的端到端OCR模型微调策略、针对匈牙利语文档的布局识别基准、以及通过域适应技术将合成模型迁移至真实扫描图像的方法。此外,数据集还被用于评估多模态语言模型在混合内容文档(如表格与段落交错的发票)上的表现,推动了低资源语言文档AI的发展。
以上内容由遇见数据集搜集并总结生成


