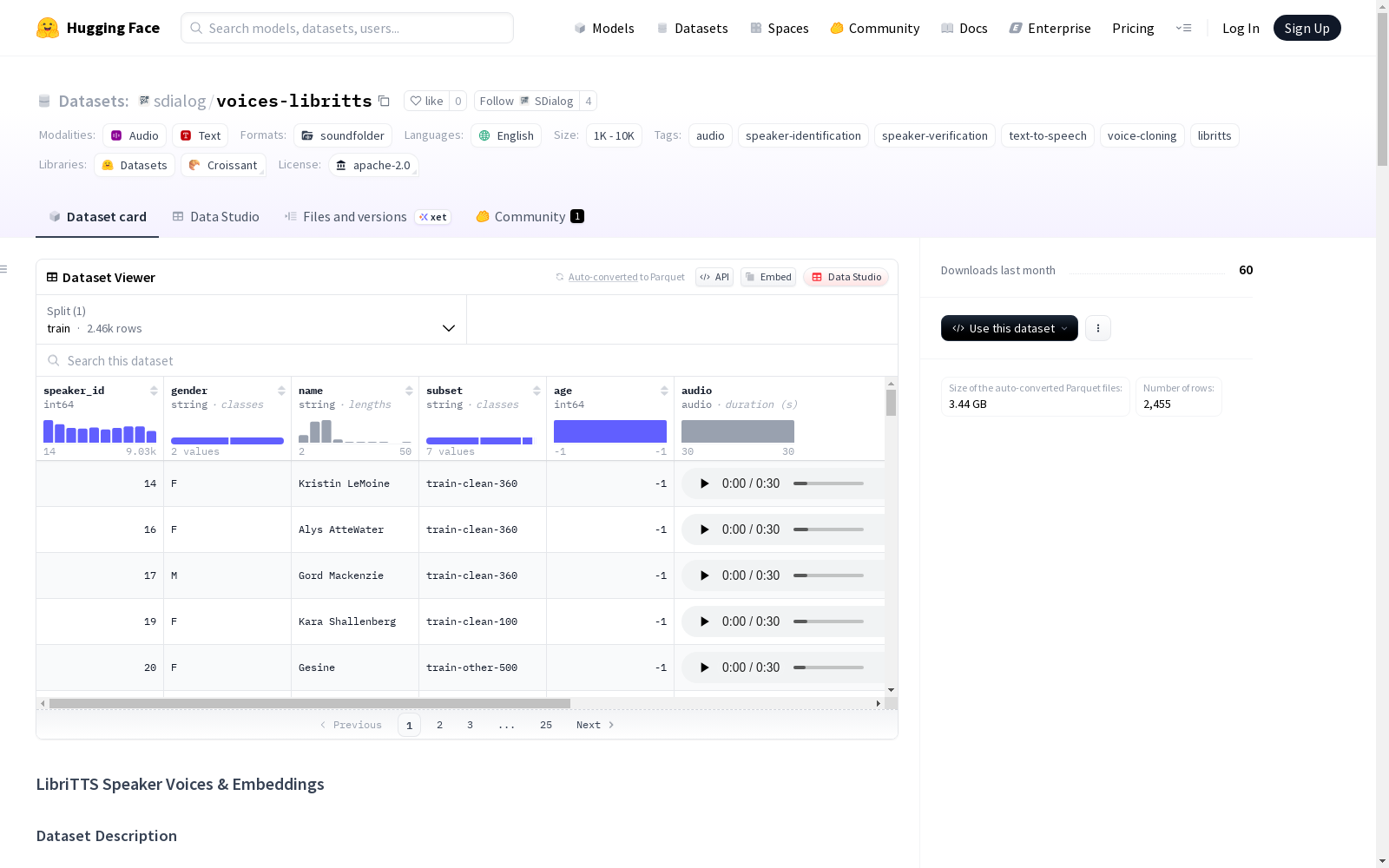
voices-libritts
收藏LibriTTS Speaker Voices & Embeddings 数据集概述
数据集基本信息
- 许可证: Apache 2.0
- 语言: 英语 (en)
- 标签: 音频、说话人识别、说话人验证、文本转语音、语音克隆、LibriTTS
- 数据集名称: LibriTTS Speaker Voices & Embeddings
数据集描述
该数据集提供来自LibriTTS语料库的说话人语音样本集合。每个说话人提供一个30秒的音频剪辑,通过拼接其语音片段创建。数据集适用于说话人识别、说话人验证以及作为文本转语音(TTS)模型的语音库,特别是语音克隆任务。
数据集组件
- 音频剪辑: 每个说话人的30秒
.wav文件。 - 元数据:
metadata.csv文件,链接音频文件到说话人信息(ID、性别、姓名等)。 - 说话人嵌入:
xvectors.pkl文件,包含一个字典,将每个speaker_id映射到其对应的嵌入向量。
数据集结构
数据字段
speaker_id(int): 说话人的唯一标识符。gender(string): 说话人的性别(M或F)。name(string): 说话人的姓名。subset(string): 说话人音频来源的LibriTTS子集。age(int): 说话人的年龄(未提供,设置为-1)。audio(Audio): 30秒的音频剪辑,采样率为24kHz。total_duration_s(float): 音频剪辑的总时长(30.0秒)。used_utterances(string): 用于创建音频剪辑的原始LibriTTS话语文件的JSON字符串。
数据文件
./audio/: 包含所有说话人音频剪辑的目录。metadata.csv: 包含所有说话人元数据的CSV文件。xvectors.pkl: 包含说话人嵌入的Python pickle文件。
数据集创建
源数据
数据集基于LibriTTS语料库创建。
预处理
- 从子集目录中定位每个说话人的
.wav话语文件。 - 拼接话语直到总时长至少30秒。
- 将拼接的音频修剪为30秒,不足则用静音填充。
- 最终音频保存为单个
.wav文件。
嵌入计算
使用pyannote/embedding模型为每个30秒音频剪辑提取一个嵌入,存储在xvectors.pkl文件中。
引用
bibtex @inproceedings{zen19_interspeech, title = {LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech}, author = {Heiga Zen and Viet Dang and Rob Clark and Yu Zhang and Ron J. Weiss and Ye Jia and Zhifeng Chen and Yonghui Wu}, year = {2019}, booktitle = {Interspeech 2019}, pages = {1526--1530}, doi = {10.21437/Interspeech.2019-2441}, issn = {2958-1796}, }
@INPROCEEDINGS{9052974, author={Bredin, Hervé and Yin, Ruiqing and Coria, Juan Manuel and Gelly, Gregory and Korshunov, Pavel and Lavechin, Marvin and Fustes, Diego and Titeux, Hadrien and Bouaziz, Wassim and Gill, Marie-Philippe}, booktitle={ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, title={Pyannote.Audio: Neural Building Blocks for Speaker Diarization}, year={2020}, volume={}, number={}, pages={7124-7128}, keywords={Voice activity detection;Conferences;Pipelines;Machine learning;Signal processing;Acoustics;Open source software;speaker diarization;voice activity detection;speaker change detection;overlapped speech detection;speaker embedding}, doi={10.1109/ICASSP40776.2020.9052974}}