PODS
收藏Hugging Face2024-12-22 更新2024-12-23 收录
下载链接:
https://huggingface.co/datasets/chaenayo/PODS
下载链接
链接失效反馈官方服务:
资源简介:
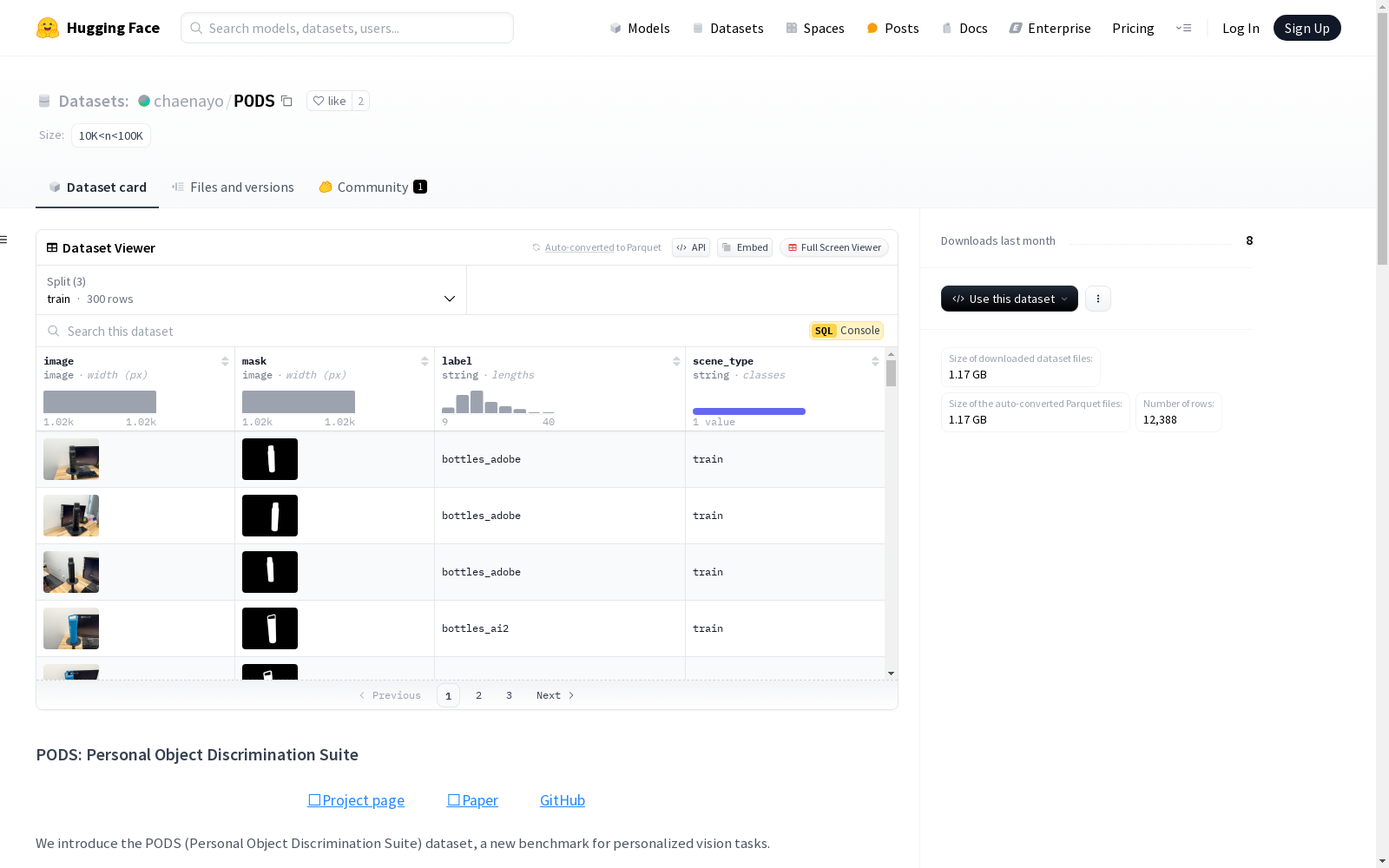
PODS数据集是一个用于个性化视觉任务的新基准,包含100个常见的家用物品,分为5个语义类别,涵盖4个任务(分类、检索、分割、检测),并具有4个不同分布偏移的测试分割。每个实例有71-201个测试图像用于分类标签注释,以及每个实例12个测试图像用于分割注释。数据集的元数据存储在两个文件中,分别包含类名、类到整数ID的映射、类到语义类别的映射以及类到验证或测试分割的映射。
创建时间:
2024-12-20
原始信息汇总
PODS: Personal Object Discrimination Suite
数据集概述
PODS(Personal Object Discrimination Suite)是一个用于个性化视觉任务的新基准数据集。该数据集包含以下内容:
- 100个常见的家用物品,分为5个语义类别。
- 4个任务(分类、检索、分割、检测)。
- 4个具有不同分布偏移的测试集。
- 每个实例有71-201张测试图像,带有分类标签注释。
- 每个实例有12张测试图像(每个分割3张),带有分割注释。
数据集结构
数据集包含以下特征:
image: 图像数据,类型为image。mask: 掩码数据,类型为image。label: 标签数据,类型为string。scene_type: 场景类型,类型为string。
数据集分为以下几个部分:
train: 训练集,包含300个样本,大小为27536486.0字节。test: 测试集,包含10888个样本,大小为1057911404.0字节。test_dense: 密集测试集,包含1200个样本,大小为142883772.0字节。
数据集元数据
元数据存储在两个文件中:
pods_info.json:classes: 类别名称列表。class_to_idx: 每个类别到整数ID的映射。class_to_sc: 每个类别到单个语义类别的映射。class_to_split: 每个类别到val或test分割的映射。
pods_image_annos.json: 将每个图像ID映射到其类别和测试分割(train,objects,pose,all之一)。
数据集加载
使用HuggingFace加载数据集
可以通过以下代码使用HuggingFace datasets库加载数据集:
python
from datasets import load_dataset
pods_dataset = load_dataset("chaenayo/PODS")
也可以指定分割: python pods_dataset = load_dataset("chaenayo/PODS", split="train") # 或 "test" 或 "test_dense"
直接下载数据集
可以通过以下命令直接下载数据集: bash wget https://data.csail.mit.edu/personal_rep/pods.zip
数据集大小
- 下载大小:1168229577字节。
- 数据集大小:1228331662.0字节。
搜集汇总
数据集介绍
构建方式
PODS数据集的构建旨在为个性化视觉任务提供一个全新的基准。该数据集精心挑选了100种常见的家用物品,涵盖5个语义类别,并设计了4种不同的任务类型,包括分类、检索、分割和检测。此外,数据集还包含了4个具有不同分布偏移的测试集,以确保其在多样性上的广泛适用性。每个实例的测试图像数量在71到201之间,且每张图像均附有分类标签注释。对于分割任务,每个实例提供了12张图像,每张图像均包含分割注释。
特点
PODS数据集的显著特点在于其高度个性化的设计,涵盖了多种视觉任务,并提供了丰富的注释信息。数据集中的图像不仅数量庞大,且每张图像都经过精心标注,确保了其在分类、检索、分割和检测任务中的高效应用。此外,数据集还包含了详细的元数据,如类别名称、类别索引、语义类别映射以及类别与测试集的映射关系,这些元数据为研究者提供了极大的便利。
使用方法
PODS数据集可以通过HuggingFace的`datasets`库进行加载,用户只需安装该库并调用`load_dataset`函数即可。此外,数据集也可以通过直接下载的方式获取,使用`wget`命令即可完成下载。在使用过程中,用户可以根据需求选择不同的数据集分割,如训练集、测试集或密集测试集。数据集的多样性和丰富的注释信息使其适用于多种视觉任务的研究与应用。
背景与挑战
背景概述
PODS(Personal Object Discrimination Suite)数据集由Sundaram等人于2024年提出,旨在为个性化视觉任务提供一个新的基准。该数据集包含了100种常见的家用物品,涵盖5个语义类别,并支持分类、检索、分割和检测四种任务。PODS的创建不仅为个性化视觉研究提供了丰富的资源,还通过引入不同分布偏移的测试集,推动了模型在实际应用中的鲁棒性研究。该数据集的发布标志着个性化视觉领域的一个重要里程碑,为未来的研究提供了坚实的基础。
当前挑战
PODS数据集在构建过程中面临了多重挑战。首先,个性化视觉任务的复杂性要求数据集不仅包含多样化的物体,还需涵盖多种任务类型,如分类、检索、分割和检测,这增加了数据标注和处理的难度。其次,为了模拟真实世界中的分布偏移,数据集设计了四个不同的测试集,这对模型的泛化能力提出了更高的要求。此外,如何在有限的资源下高效地标注和组织大规模数据,也是构建过程中的一大挑战。
常用场景
经典使用场景
PODS数据集在个性化视觉任务中展现了其经典应用场景,特别是在家庭物品的分类、检索、分割和检测任务中。通过提供100种常见家庭物品的图像数据,PODS为研究人员提供了一个丰富的基准,用于评估和开发个性化视觉模型。其多样化的任务设置和不同分布偏移的测试集,使得该数据集在个性化视觉领域的研究中具有重要的参考价值。
实际应用
PODS数据集在实际应用中具有广泛的潜力,特别是在智能家居、机器人视觉和个性化推荐系统等领域。例如,在智能家居系统中,PODS可以用于训练模型,使其能够识别和区分家庭成员的个人物品,从而提供更加个性化的服务。此外,在机器人视觉领域,PODS可以帮助机器人更好地理解和操作家庭环境中的物品,提升其交互能力和任务执行效率。
衍生相关工作
PODS数据集的发布激发了大量相关研究工作,特别是在个性化视觉模型的开发和评估方面。许多研究者基于PODS数据集进行了深入的实验和分析,提出了多种改进的模型和算法。例如,有研究者利用PODS数据集开发了更加鲁棒的分类和分割模型,以应对不同分布偏移的挑战。此外,PODS还启发了在个性化视觉任务中引入生成模型的研究,进一步推动了该领域的技术进步。
以上内容由遇见数据集搜集并总结生成


