DFKI-SLT/BioRel
收藏Hugging Face2024-08-11 更新2024-06-29 收录
下载链接:
https://hf-mirror.com/datasets/DFKI-SLT/BioRel
下载链接
链接失效反馈官方服务:
资源简介:
BioRel数据集是一个专门用于生物医学关系抽取的数据集。它利用了大量的电子生物医学文献,使用统一医学语言系统(UMLS)作为知识库,Medline文章作为语料库,通过Metamap进行实体识别和链接,并采用远程监督进行关系标注。数据集包含训练集、验证集和测试集,分别包含534,406、218,669和114,515个句子。数据集支持深度学习和统计机器学习方法,为生物医学关系抽取模型的训练和评估提供了丰富的资源。
BioRel is a comprehensive dataset designed for biomedical relation extraction, leveraging the vast amount of electronic biomedical literature available. Developed using the Unified Medical Language System (UMLS) as a knowledge base and Medline articles as a corpus, BioRel utilizes Metamap for entity identification and linking, and employs distant supervision for relation labeling. The training set comprises 534,406 sentences, the validation set includes 218,669 sentences, and the testing set contains 114,515 sentences. This dataset supports both deep learning and statistical machine learning methods, providing a robust resource for training and evaluating biomedical relation extraction models.
提供机构:
DFKI-SLT
原始信息汇总
BioRel 数据集概述
数据集描述
BioRel 是一个用于生物医学关系抽取的综合数据集,基于统一医学语言系统(UMLS)和Medline文章构建。该数据集利用Metamap进行实体识别和链接,并采用远监督方法进行关系标注。
数据集概要
- 训练集:包含534,406个句子。
- 验证集:包含218,669个句子。
- 测试集:包含114,515个句子。
语言
数据集中的语言为英语。
数据集结构
数据字段
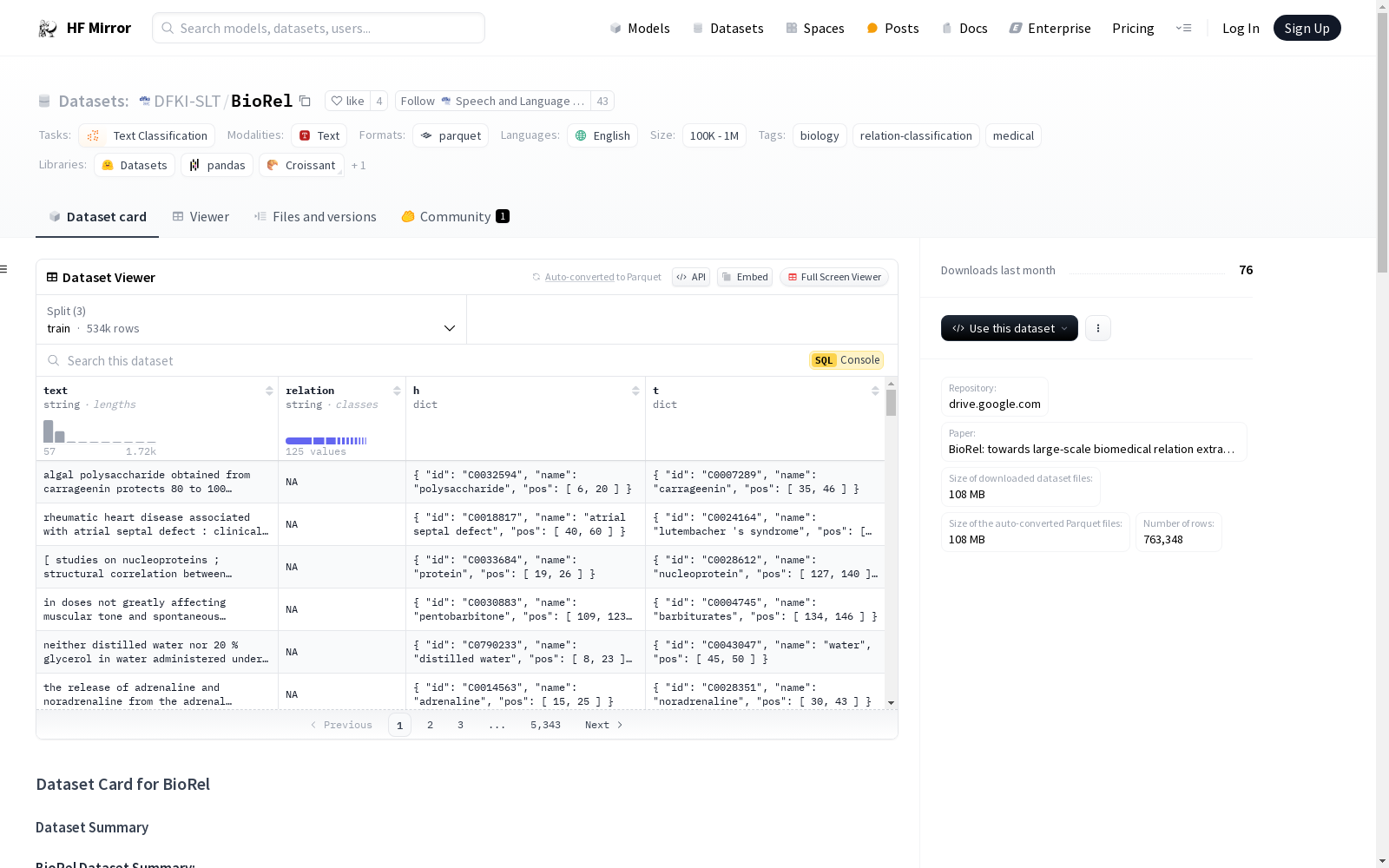
text:示例文本,类型为string。h:头实体id:头实体的标识符,类型为string。pos:头实体的字符偏移量,类型为int32列表。name:头实体的文本,类型为string。
t:尾实体id:尾实体的标识符,类型为string。pos:尾实体的字符偏移量,类型为int32列表。name:尾实体的文本,类型为string。
relation:类别标签。
数据实例
以下是训练集中的一个示例: json { "text": "algal polysaccharide obtained from carrageenin protects 80 to 100 percent of chicken embryos against fatal infections with the lee strain of influenza virus .", "relation": "NA", "h": { "id": "C0032594", "name": "polysaccharide", "pos": [6, 20] }, "t": { "id": "C0007289", "name": "carrageenin", "pos": [35, 46] } }
引用
BibTeX
@article{xing2020biorel, title={BioRel: towards large-scale biomedical relation extraction}, author={Xing, Rui and Luo, Jie and Song, Tengwei}, journal={BMC bioinformatics}, volume={21}, pages={1--13}, year={2020}, publisher={Springer} }
APA
- Xing, R., Luo, J., & Song, T. (2020). BioRel: towards large-scale biomedical relation extraction. BMC bioinformatics, 21, 1-13.
搜集汇总
数据集介绍
构建方式
BioRel数据集的构建基于Unified Medical Language System (UMLS)知识库和Medline文章,通过Metamap工具进行实体识别与链接,并采用远监督方法进行关系标注。训练集包含534,406个句子,验证集和测试集分别包含218,669和114,515个句子,为生物医学关系抽取提供了丰富的资源。
特点
BioRel数据集的显著特点在于其大规模和多样性,涵盖了广泛的生物医学文献,支持深度学习和统计机器学习方法。此外,数据集的结构化设计,包括文本、头部实体、尾部实体及其关系,使得模型训练和评估更为高效和准确。
使用方法
使用BioRel数据集时,用户可以访问包含文本、实体及其关系的结构化数据。通过提供的训练、验证和测试集,用户可以进行模型训练和性能评估。数据集的转换脚本也已公开,便于用户将其转换为OpenNRE格式,进一步支持关系抽取任务的研究与应用。
背景与挑战
背景概述
在生物医学领域,关系抽取是理解复杂生物医学文献的关键任务。BioRel数据集由DFKI-SLT团队开发,旨在通过大规模的生物医学文献数据来支持关系抽取模型的训练与评估。该数据集利用统一医学语言系统(UMLS)作为知识库,并结合Medline文章进行实体识别与链接,采用远监督方法进行关系标注。BioRel数据集包含534,406个训练句子、218,669个验证句子和114,515个测试句子,为深度学习和统计机器学习方法提供了丰富的资源。
当前挑战
BioRel数据集在构建过程中面临多重挑战。首先,生物医学文献的复杂性和专业性使得实体识别与关系标注任务异常艰巨。其次,远监督方法虽然能有效扩展数据集规模,但也引入了噪声和错误标注的问题。此外,数据集的规模和多样性要求高效的算法和计算资源来处理和分析。最后,如何确保数据集的质量和一致性,以支持高精度的关系抽取模型,是该数据集面临的重要挑战。
常用场景
经典使用场景
在生物医学领域,BioRel数据集的经典使用场景主要集中在关系抽取任务上。该数据集通过整合电子生物医学文献和统一医学语言系统(UMLS)的知识库,为研究人员提供了一个丰富的资源,用于训练和评估生物医学关系抽取模型。其结构化的数据格式,包括文本、头部实体和尾部实体的信息,使得模型能够有效地识别和分类生物医学实体之间的关系。
实际应用
在实际应用中,BioRel数据集被广泛用于开发和优化生物医学信息检索系统、知识图谱构建工具以及临床决策支持系统。通过利用该数据集训练的模型,研究人员能够更准确地从海量生物医学文献中提取关键信息,从而加速新药研发、疾病诊断和治疗方案的制定。
衍生相关工作
基于BioRel数据集,研究人员开发了多种生物医学关系抽取模型,并在多个国际会议上发表了相关研究成果。例如,一些工作利用该数据集训练的模型在生物医学文本中的关系抽取任务上取得了显著的性能提升。此外,BioRel数据集还被用于开发新的数据增强技术和模型评估方法,进一步推动了生物医学信息学领域的发展。
以上内容由遇见数据集搜集并总结生成


