chess-puzzles-images-mini
收藏Hugging Face2024-10-06 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/bingbangboom/chess-puzzles-images-mini
下载链接
链接失效反馈官方服务:
资源简介:
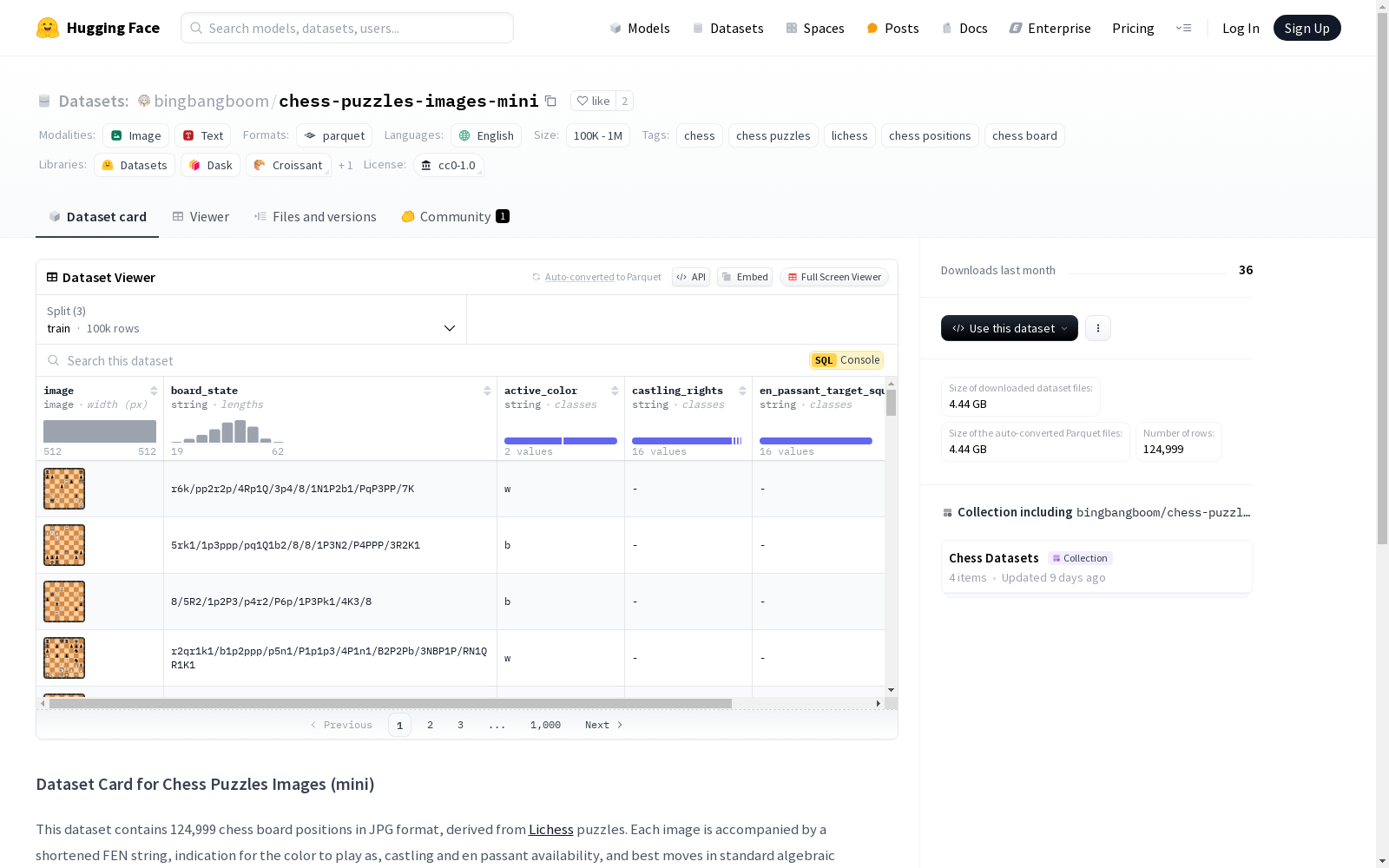
该数据集包含124,999个国际象棋棋盘位置的图像,这些图像以JPG格式存储,来源于Lichess的谜题。每个图像都附有一个简化的FEN字符串,指示当前轮到哪一方移动,以及是否可以进行王车易位和吃过路兵,以及最佳的棋步。数据集分为训练集、验证集和测试集,分别包含99,999、12,500和12,500个样本。
创建时间:
2024-10-06
原始信息汇总
数据集概述
数据集名称
Chess Puzzles Images (mini)
数据集描述
该数据集包含124,999个国际象棋棋盘位置的JPG格式图像,源自Lichess谜题。每个图像附带一个简化的FEN字符串、指示轮到哪一方移动、王车易位和吃过路兵的可能性,以及最佳着法的标准代数表示法。
数据集特征
image:image,棋盘的视觉表示,显示当前棋子排列。board_state:string,简化的FEN(Forsyth–Edwards Notation)字符串,表示对手移动后的棋盘上的棋子位置。此状态指示玩家必须找到正确续着的位置。active_color:string,指示轮到哪一方移动。"w"表示白方移动,"b"表示黑方移动。castling_rights:string,指示双方剩余的王车易位选项。如果双方都不能王车易位,此字段使用字符"-"。否则,此字段包含一个或多个字母:"K"表示白方可以王车易位到王翼,"Q"表示白方可以王车易位到后翼,"k"表示黑方可以王车易位到王翼,"q"表示黑方可以王车易位到后翼。en_passant_target_square:string,指定可以吃过路兵的格子,用代数表示法表示。如果没有吃过路兵的可能,此字段包含"-"。best_continuation:string,谜题的解答,由“唯一着法”组成——这些着法明显优于任何其他选择。对于一步杀谜题,如果所有解决方案都导致将杀,可能存在多个解决方案。
数据集分割
- train: 包含99,999个样本,大小为3,819,944,422.152字节。
- validation: 包含12,500个样本,大小为477,938,253.5字节。
- test: 包含12,500个样本,大小为479,103,793字节。
数据集大小
- 下载大小: 4,435,938,030字节
- 数据集大小: 4,776,986,468.652字节
数据集配置
- config_name: default
- data_files:
- train: data/train-*
- validation: data/validation-*
- test: data/test-*
- data_files:
许可证
cc0-1.0
语言
- en
标签
- chess
- chess puzzles
- lichess
- chess positions
- chess board
搜集汇总
数据集介绍
构建方式
该数据集通过从Lichess平台提取的棋局谜题构建而成,包含了124,999个国际象棋棋盘位置的JPG格式图像。每个图像均附有简化的FEN字符串,用于表示对手移动后的棋子布局,并标注了当前移动方、王车易位权利、过路兵目标方格以及最佳续着。数据集的构建过程充分考虑了棋局的实际应用场景,确保了数据的多样性和实用性。
特点
该数据集的特点在于其丰富的棋局信息标注。每个棋局不仅包含棋盘图像,还提供了详细的FEN字符串、当前移动方、王车易位权利、过路兵目标方格以及最佳续着。这些信息为棋局分析和棋艺提升提供了全面的数据支持。此外,数据集涵盖了多种棋局类型,包括一步杀等复杂局面,适合用于训练和评估棋局分析模型。
使用方法
该数据集适用于国际象棋相关的研究和应用开发。研究人员可以利用该数据集训练棋局分析模型,评估模型的棋局理解能力。开发者则可以通过该数据集构建棋局推荐系统或棋艺提升工具。使用该数据集时,建议首先加载图像和对应的标注信息,然后根据具体任务需求进行数据预处理和模型训练。数据集的标准化标注格式使得其易于集成到现有的机器学习框架中。
背景与挑战
背景概述
Chess Puzzles Images (mini) 数据集由Lichess平台衍生而来,专注于国际象棋谜题的视觉化表示与解决方案。该数据集创建于近年,旨在为国际象棋爱好者与研究者提供一个包含124,999个棋局位置的图像数据集。每个图像均附有简化的FEN字符串、当前行动方、王车易位权利、过路兵目标方格以及最佳续着信息。这一数据集不仅为国际象棋的计算机视觉研究提供了丰富的素材,还为棋局分析与人工智能训练奠定了坚实基础。其核心研究问题在于如何通过图像识别与棋局状态分析,提升计算机在国际象棋谜题中的表现。
当前挑战
Chess Puzzles Images (mini) 数据集在构建与应用过程中面临多重挑战。首先,棋局图像的生成与标注需要高度精确,以确保FEN字符串与图像内容的一致性,这对数据清洗与标注流程提出了严格要求。其次,棋局状态的复杂性使得最佳续着的标注需要依赖专业棋手的判断,增加了数据构建的难度。此外,如何在图像识别模型中有效融合棋局状态信息,以提升模型对复杂棋局的理解能力,仍是一个亟待解决的技术难题。这些挑战不仅考验数据集的构建质量,也对后续的研究与应用提出了更高的要求。
常用场景
经典使用场景
在人工智能和机器学习领域,chess-puzzles-images-mini数据集被广泛用于训练和评估棋类游戏相关的模型。该数据集通过提供大量的棋盘图像及其对应的状态信息,使得研究者能够开发出能够理解和解决复杂棋局问题的算法。特别是在深度学习模型中,这些数据被用来训练卷积神经网络(CNN)以识别棋盘上的棋子位置和预测最佳走法。
解决学术问题
该数据集解决了棋类游戏研究中一个关键问题:如何有效地训练模型以理解和预测复杂的棋局变化。通过提供精确的棋盘状态和最佳走法,研究者可以开发出更准确的棋局分析工具,从而推动棋类人工智能的发展。此外,该数据集还为研究棋类游戏的策略和战术提供了丰富的数据支持,有助于深入理解棋类游戏的复杂性。
衍生相关工作
基于chess-puzzles-images-mini数据集,研究者们已经开发出多种先进的棋类游戏模型和算法。例如,一些研究利用该数据集训练深度强化学习模型,使其能够在复杂的棋局中做出最优决策。此外,该数据集还催生了一系列关于棋类游戏策略和战术的研究,进一步推动了棋类人工智能领域的发展。
以上内容由遇见数据集搜集并总结生成


