DVQA
收藏arXiv2025-09-30 收录
下载链接:
https://kushalkafle.com/projects/dvqa.html
下载链接
链接失效反馈官方服务:
资源简介:
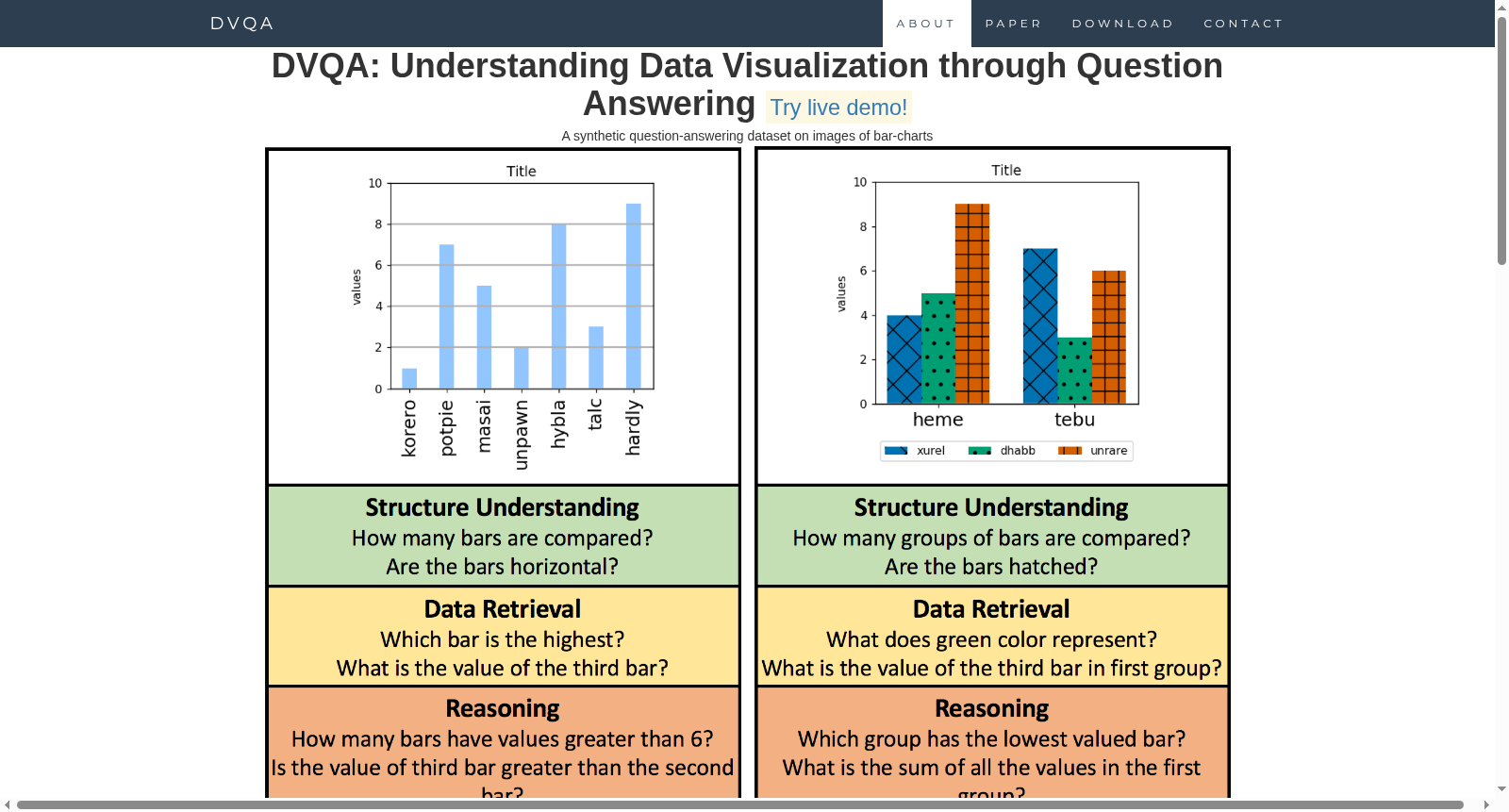
该数据集名为DVQA,专为解答关于条形图的问题而设计。它根据训练集中遇到的词汇熟悉度,被划分为测试熟悉(Test-Familiar)和测试新颖(Test-Novel)两个子集。测试熟悉子集包含熟悉的词汇所对应的图表,而测试新颖子集则包含不常见的词汇所对应的图表。该数据集强调了在性能上整合光学字符识别(OCR)的重要性。任务类型是图表问题回答。
The dataset named DVQA is specifically designed for answering questions about bar charts. It is divided into two subsets, Test-Familiar and Test-Novel, based on the familiarity of vocabulary encountered in the training set. The Test-Familiar subset contains charts corresponding to familiar vocabulary, while the Test-Novel subset includes charts associated with uncommon vocabulary. This dataset emphasizes the importance of integrating optical character recognition (OCR) for model performance. The core task of this dataset is chart question answering.
搜集汇总
数据集介绍
背景与挑战
背景概述
DVQA是一个专注于数据可视化问答的合成数据集,包含30万张条形图图像和近350万个平衡的问答对,覆盖结构理解、数据检索和推理三类问题。该数据集旨在提升AI从图表中提取信息的能力,并作为评估注意力、记忆等AI代理任务的重要工具。
以上内容由遇见数据集搜集并总结生成


